Recent history:
- graduate from uiuc on sun
- 6am flight to sf on mon
- pitch to countless vc’s
- close pre-seed
- reopen pre-seed bc investors are interested
Excited for the future
All glory to God
Major difference in my mind:
- an engineer, given a problem, invents and tries multiple solutions and stops when the solution is good enough. The goal is product innovation and shipping.
- a scientist asks new questions, proposes various new solutions, compares them (sometimes with old ones), and writes about it. The methodology must be sound or else peers will sneer. The goal is scientific breakthroughs and technological progress.
Both can be called "researchers". Many people can do both: these are activities, not identities.
Importantly, most product innovations are built on scientific breakthroughs and technological innovations that happened 2, 5, 10, or 20 years earlier.
Just pitched to 3 VC’s today, got another one in 9hrs😴. Reception was good, gearing up to be a nice pre-seed round
Travel was insane though Berkeley->downtown SF->mountain view and tmr is in Salinas
"Thank you so much for this award, it is with great humility and gratitude that I accept this honor. This achievement is not solely my own — it is the result of the sacrifices, support, and guidance of all who have helped me along the way. Additionally, I am thankful to God for gifting me these opportunities and to the University of Illinois for cultivating a climate of innovation, real-world impact, and freedom to pursue revolutionary work. This award will directly accelerate my mission at AgAnswers, where we are leveraging the AI research built at UIUC to revolutionize farm operations and, more broadly, agriculture.”
- aidan
https://t.co/C1lWbZ64C4
AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]
This AI race is getting interesting…
If they ipo there may be a ton of upside
Will be interesting to see what models they can cook up with the user data of cursor and the compute power of XAI
SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI.
The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models.
Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
I see every week on X an announcement or demo which implies that robotic manipulation has been solved. The only reason I don't believe it is because manipulation had already been solved last week by somebody else! So may I propose the "5 year old paired comparison test" ? At the next conference let's set up a number of tables to which you can bring your robot hardware. Next to it we will have another table where there will be a 5 year old child. In parallel we will try 100 different manipulation tasks that a neutral person has chosen- we could start with "pick up anything" - only household objects (e.g. as might be found in a typical American home) will be used, and we compare the performance of your robot with that of the 5 year old. Can you pick up a coin? Or a book? Or untwist a bottle top? Or insert any plug into a matching socket? Rotate one face of a Rubik's cube? Until your robot can do all the "open world manipulation" that a 5 year old kid can, some humility is in order.
the level of sycophancy in these models only snowballs the AI psychosis @karpathy is talking about.
the problem is two fold:
1/ these models extend the capabilities of ur mind beyond what was previously fathomable. solving complex tasks takes minutes instead of weeks. when u deeply understand how truly difficult these problems are, it only follows that u’d think ur a genius for moving so quickly.
2/ the models affirm this belief. they continuously tell u how smart and clever u are. they never push back. they never say “this is the model doing the heavy lifting, not you.”
so you get this feedback loop: superhuman tool + constant validation = completely distorted self-perception.
that’s the real danger nobody’s talking about.
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
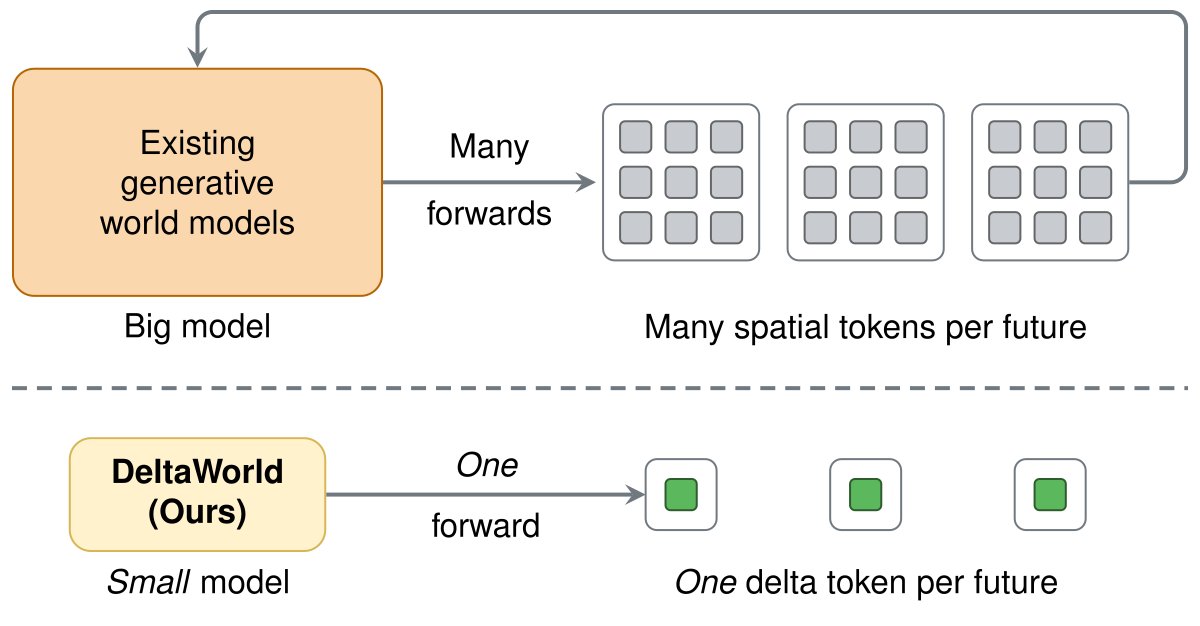
World models are heavy. They don't need to be.
Each frame is encoded as 1024 spatial tokens. What if it were just 1?
In our #CVPR2026 Highlight from Amazon FAR, we compress frames into "delta" tokens for efficient generative world modeling.
Paper, code & models below ↓
(1/7)























![AndrewYNg's tweet photo. AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This post focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
[Original text: https://t.co/1pUxNC5UXk ]](https://pbs.twimg.com/media/HG7HHJqbsAA3iao.jpg)