Don't sleep on @GoogleDeepMind in AI...
This week on Training Data, Google Labs VP @joshwoodward gave us the BTS on Google's imagination playground for AI, from Notebook to Mariner (computer use agent) to Veo (video models).
Thanks Josh for the spicy convo and hot takes :)
Here’s a quick preview of Whisk Animate, which lets you turn images you create in Whisk into 8 second clips using our Veo 2 model. Stay tuned for updates on when this will be made more widely available.
Accelerate data science workflows with Google Colab's new Data Science Agent. This agent uses Gemini to act as your coding partner: upload your data, define your analysis goals, and watch a Colab notebook take shape. Now available for all Colab users → https://t.co/PO6OMko9qV
Exciting new @Waymo milestone: Waymo One is now serving 200k+ paid trips each week across LA, Phoenix and SF - that’s 20x growth in less than two years! Up next: Austin, Atlanta and Miami.
From Wan 2.1 to LLaDA to this boring reality LoRA for HunyuanVideo (that warms my millennial heart🥹) - February was a wild month for open source 🤩
That's why we made you a recap of all the major releases in the AI & creativity space👇✨
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream.
Most of the image / video generation AI tools actually work this way and use Diffusion, not Autoregression. It's only text (and sometimes audio!) that have resisted. So it's been a bit of a mystery to me and many others why, for some reason, text prefers Autoregression, but images/videos prefer Diffusion. This turns out to be a fairly deep rabbit hole that has to do with the distribution of information and noise and our own perception of them, in these domains. If you look close enough, a lot of interesting connections emerge between the two as well.
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
For friends of open source: imo the highest leverage thing you can do is help construct a high diversity of RL environments that help elicit LLM cognitive strategies. To build a gym of sorts. This is a highly parallelizable task, which favors a large community of collaborators.
Thank you, Kijai @Kijaidesign , for creating the ComfyUI wrapper for Hunyuan3D 2.0 and for assisting enthusiasts in solving problems in our Discord channel.
https://t.co/Lt03Lh3aeW
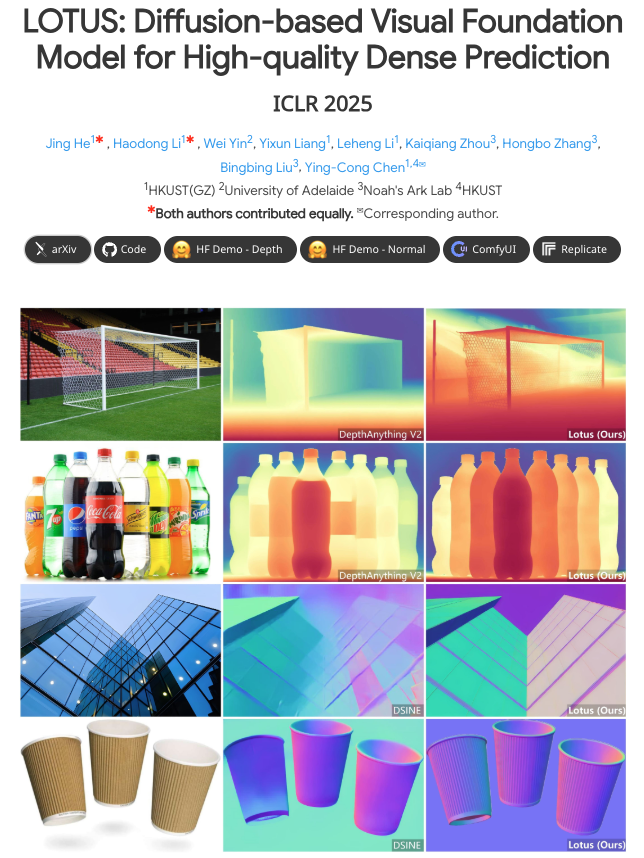
Thrilled to share that our paper, "LOTUS: Diffusion-based Visual Foundation Model for High-quality Dense Prediction", has been accepted to #ICLR2025! 🎉 Many thanks to @YingCongChen1@haodongli00 and all co-authors!
Github: https://t.co/U6IohPw6lS