This week we launched the Open Benchmarks Grant with a $3M initial commitment from @SnorkelAI + partner support from @huggingface@togethercompute@PrimeIntellect@PyTorch@harborframework & others, in order to close the evaluation gap in AI.
Our ability to measure AI has been outpaced by our ability to develop it - and open benchmarks are one of several critical, complementary tools to fix this.
We're particularly interested in novel benchmarks that push and probe the frontier along three key vectors:
(1) Environment complexity
--> E.g. complex, domain-specific context and tool/action spaces, human interaction, world modeling)
(2) Autonomy horizon
--> E.g. long horizon, non-stationary goals
(3) Output complexity
--> E.g. complex outputs with nuanced, rubric-based evaluation / reward signals
Check out more detail + link to apply here! https://t.co/m1EftlAQTB
Our thanks to everyone who dropped by yesterday for boba to learn from @EchoShao8899 of @stanfordnlp about "Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration".
Key takeaway: across 3 tasks (travel planning, related-work writing, and tabular analysis), the best collaborative agents consistently outperformed fully autonomous ones when judged by real users.
Recording/transcript ICYMI: https://t.co/jbI3KX5HSI
ProgramBench up-levels evaluation to the artifact rather than purely measuring implementation.
1. It mirrors the interface that software users (e.g. engineers, researchers) are increasingly interacting with
2. This provides a new kind of "research tool" to study frontier models, including implementation trade-offs, fuzzing/validation, new interfaces for steering models
Full discussion w/ @jyangballin below
Today, Ramp raised $750M at a $44B valuation.
Last time we grew this fast, we were 1/20th the size.
For 2000 years, business was built on two pillars. Today, a third: intelligence.
It’s your least governed cost. It’s also your single greatest opportunity.
Check out new @SnorkelAI Benchtalks with @jyangballin , author of ProgramBench, SWEBench, and many other key benchmarks in the space.
While I'm crestfallen that @vincentsunnchen so quickly dropped the gag of having the interviews on a literal bench... this is a great one!!
New Benchtalks with @jyangballin: on ProgramBench (0% frontier models at launch) and the lineage/future of coding benchmarks, from SWE-bench/InterCode to now
01:29 ProgramBench launch and reception
03:41 Why artifact-level evaluation, not code-level
06:03 Why models love Python
08:29 ProgramBench as a research tool
12:45 From SWE-bench & InterCode to ProgramBench
17:47 How to grade a coding model
21:53 The position paper & humans in the loop
25:01 Managing quality with agents-in-the-loop
28:40 Internet access and benchmark integrity
35:26 Where models may surpass human abilities
38:56 When a model hits 80% on ProgramBench
43:55 Benchmarks worth paying attention to
46:24 What benchmark do you wish existed
49:32 Will benchmarks still look like benchmarks in 5 years
52:02 How to contribute to ProgramBench
So excited for this bold vision of small, personalized, on-device AI that everyone can own themselves!
Excited to support the multi-objective evaluations that chart this new quality/latency/efficiency/cost/privacy Pareto frontier via @SnorkelAI Open Benchmarks Grants.
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
Huge congrats to @jonsaadfalcon, @Avanika15, @Azaliamirh and the @HazyResearch team on @OpenJarvisAI — out today.
For two years, they've been making the case that AI inference belongs on hardware people already own, not just in megawatt data centers. Excited to support the Intelligence per Watt line of work.
Read more on their blog: https://t.co/6XYJFICGj3
Great turnout in San Jose today for @chris_m_glaze's paper session on Benchmarking Agents in Insurance Underwriting Environments at @CAISconf.
If you're at the conference, catch the team behind the paper today at the poster session from 5:15–6:45 p.m. at Carmel/Monterey. And come find us tomorrow night at the Day 2 Conference Reception (sponsored by Snorkel).
Paper: https://t.co/4VFVq4Gjcc
Announcing JudgmentBench – a dataset we at @StanfordLaw liftlab developed along with @harvey and @SnorkelAI that evaluates frontier LLM work product.
The dataset contains 30 real-world tasks crafted by Biglaw attorneys paired with >3000 rubric and preference expert annotations.
1/ We’ve raised over $1B at a $26B valuation, led by @Lux_Capital, @generalcatalyst, and @8vc.
Our enterprise usage has grown >10x since the start of this year, and our run-rate revenue grew to $492 M.
We launched Devin two years ago as the first AI software engineer. Since then, cloud agents have gone from niche to mainstream, and today they are the fastest growing way to create software.
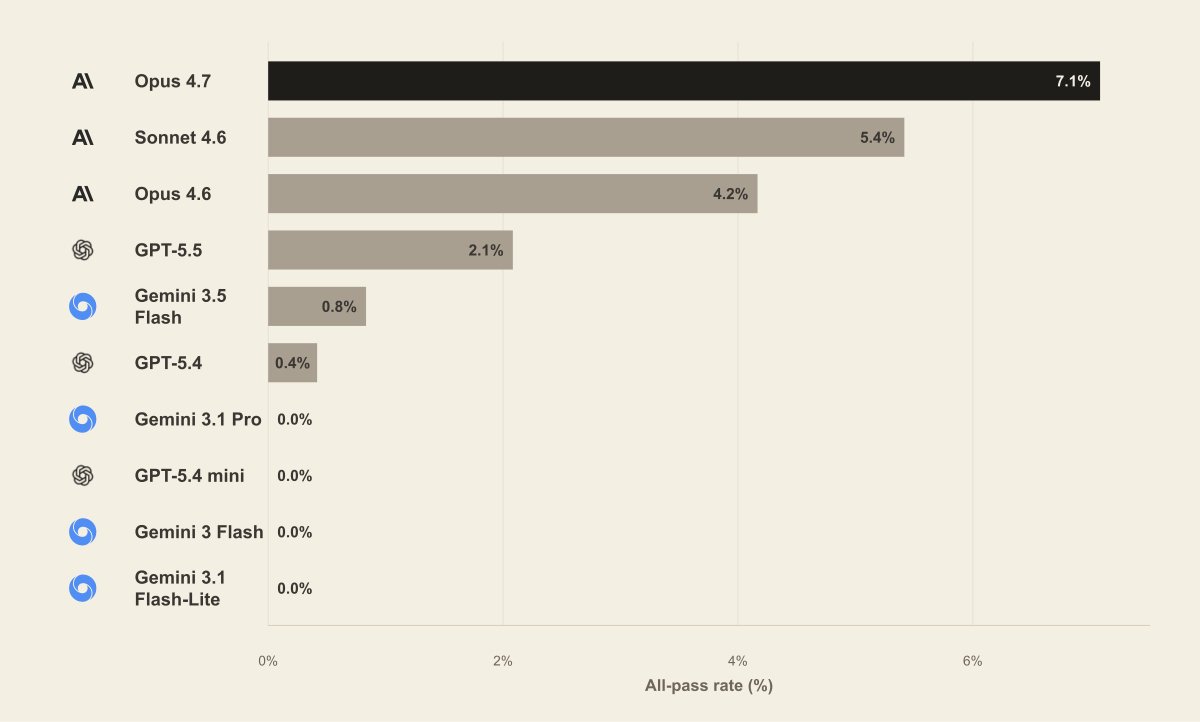
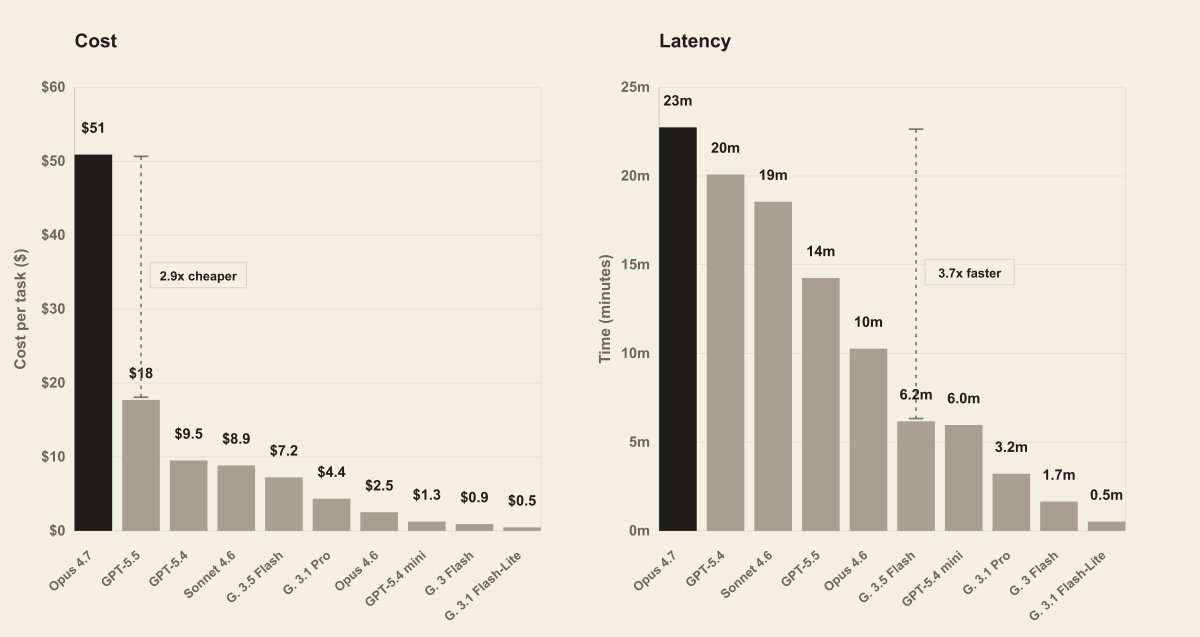
We evaluated frontier models on LAB, our long-horizon legal agent benchmark.
Three findings stood out:
1) Legal work is far from saturated by frontier models.
2) Model performance varies sharply by practice area.
3) Cost and latency rise at the frontier.
Read more:
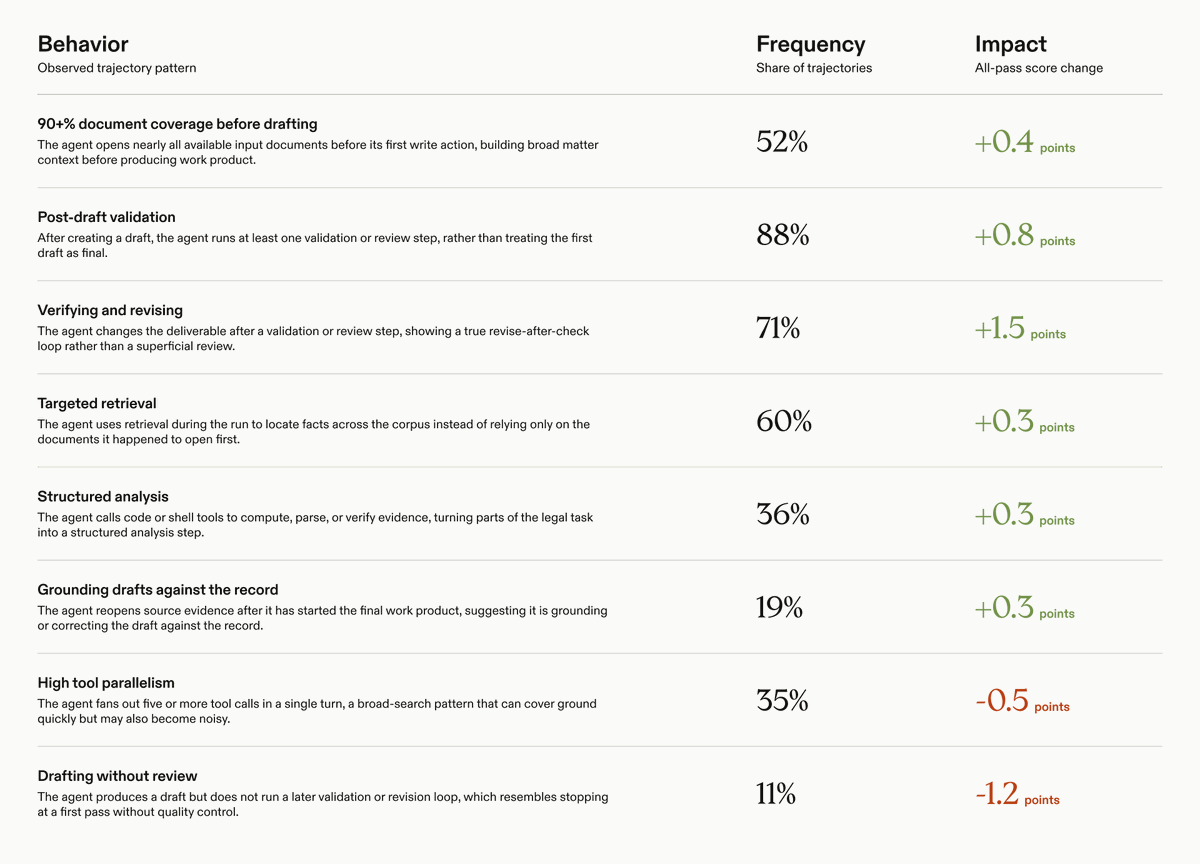
Trajectory-based error analysis points to levers for post-training and harness engineering!
From the @harvey team:
- Verify-and-revise correlates with the biggest score jump (+1.5).
- "Fan-out" tool parallelism hurts (-0.5); potentially adds noise without direction
- Grounding drafts against source evidence is +0.3, but only occurs in 19% of trajectories
Excited for more behavior-level analysis over long-horizon agent evals - great example here from Legal Agent Benchmark (LAB)!
Initial LAB results from Harvey put a number on something we see across specialized AI work: under rigorous all-pass standards, frontier models complete fewer than 10% of long-horizon legal tasks, and no single model leads across practice areas.
General capability isn't sufficient for high-stakes professional work. Closing that gap takes domain-grounded data, evaluation, and post-training, which is exactly the research we're excited to do with the Harvey team next.
Live from MLSys 2026! Thanks to everyone who joined @pham_derek's talk yesterday on RLVR in low-data, low-compute regimes and swung by our poster session.
Paper: https://t.co/dZL8uyhn4I
Around tonight? Unwind after the conference with drinks, swing suites, and the team behind the paper. Last chance to RSVP ⛳: https://t.co/cBsH6D9TEz
@vincentsunnchen @ArminPCM @realjustinbauer
Congratulations @ravirajjain@ravi_lsvp !!! They have been incredible partners to @SnorkelAI from day one, and at every stage after that. Well deserved recognition!!
Congratulations to @ravi_lsvp, @ravirajjain, and @buckymoore on their recognition in the Seed 100 List!
The Seed 100 List from @businessinsider highlights early-stage investors with a unique ability to scout the tech stars of tomorrow. Amid the AI boom, the competitiveness and speed of investors getting in before the “seed stage” as we know it have been reinforced.
This is the Seed 100’s sixth year, and it is an honor to have 3 Lightspeed team members acknowledged on the list.
Early-stage investing has been wired into our team’s DNA for over 26 years. And we are incredibly proud to have backed many teams from their Seed rounds and beyond.
As Ravi puts it: "The founders Lightspeed backs don't extrapolate from the present; they derive from first principles and arrive at futures others haven't thought to look for.”
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
https://t.co/MSPMwnbhVt
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
https://t.co/MSPMwnbhVt
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
Sat down with my friend Rezaur @intellgenc (CIO / CISO / CAIO at the @usachp) for a long conversation on building frontier AI for federal infrastructure.
Among his projects: "We're working with Google Public Sector and @SnorkelAI on a geospatial deep-research, AI-native system. And since that wasn't challenging enough, a world-simulation system to model real-world impacts on large infrastructure projects."
We get into the limits of frontier models, mechanistic interpretability for applied AI, and why Rezaur wants more entropy from his models (not less).
00:26 Building AI-native, not bolt-on
05:18 Why one model can't do geospatial AI
08:23 "I want more entropy, not less"
10:28 Inside the model: mechanistic interpretability
15:32 Externalizing memory: context, files, graphs
26:01 The RGB-pixel trick for sensor data
28:24 The geospatial benchmark gap
31:11 When a frontier model hallucinated an Iran-backed attack