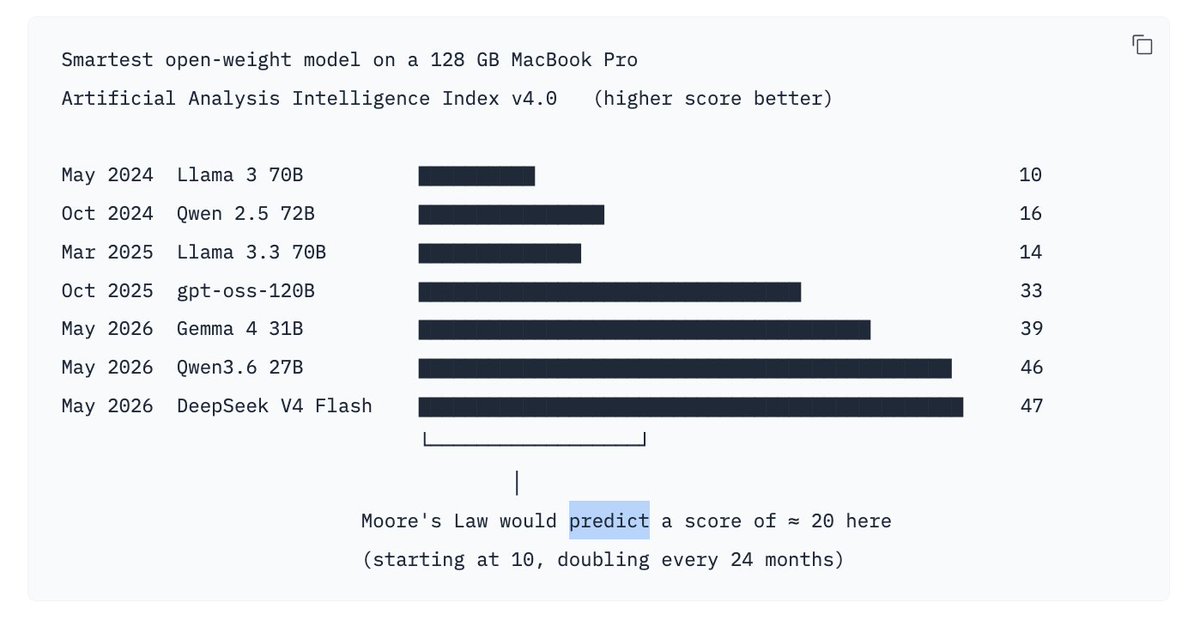
Local open-weight AI on a laptop has been improving more than twice as fast as Moore's Law!
Between May 2024 and May 2026, the most expensive MacBook Pro you could buy stayed at 128 GB of unified memory. The hardware ceiling barely moved.
But the smartest open-weight model from @huggingface you could actually run on it went from a score of 10 (Llama 3 70B) to 47 (DeepSeek V4 Flash on @antirez's mixed-Q2 GGUF) on the @ArtificialAnlys Intelligence Index.
That is 4.7× in 24 months, or a doubling of intelligence every 10.7 months. Moore's Law (transistor count) doubles every 24 months. Local open-weight AI on a laptop has been improving more than twice as fast as Moore's Law, on completely unchanged hardware.
Why is no one talking about this?
This is why I don't use an AI browser
You can literally get prompt injected and your bank account drained by doomscrolling on reddit:
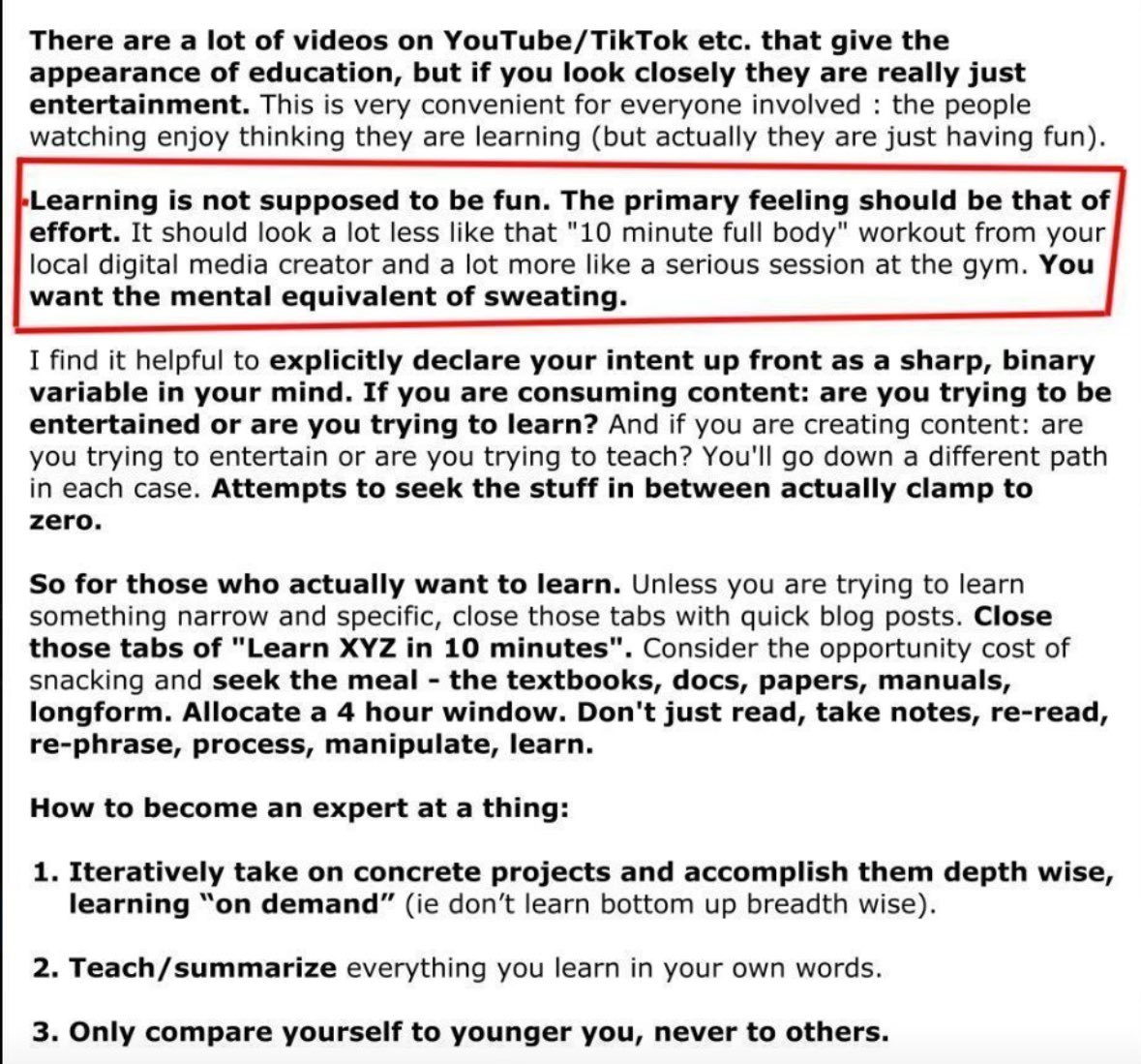
Andrej Karpathy’s bombshells on how to learn:
> learning is not supposed to be fun
> don’t hallucinate of learning
> learn on-demand, depth-wise
> teach what you learn to others
> compare yourself to you, not others
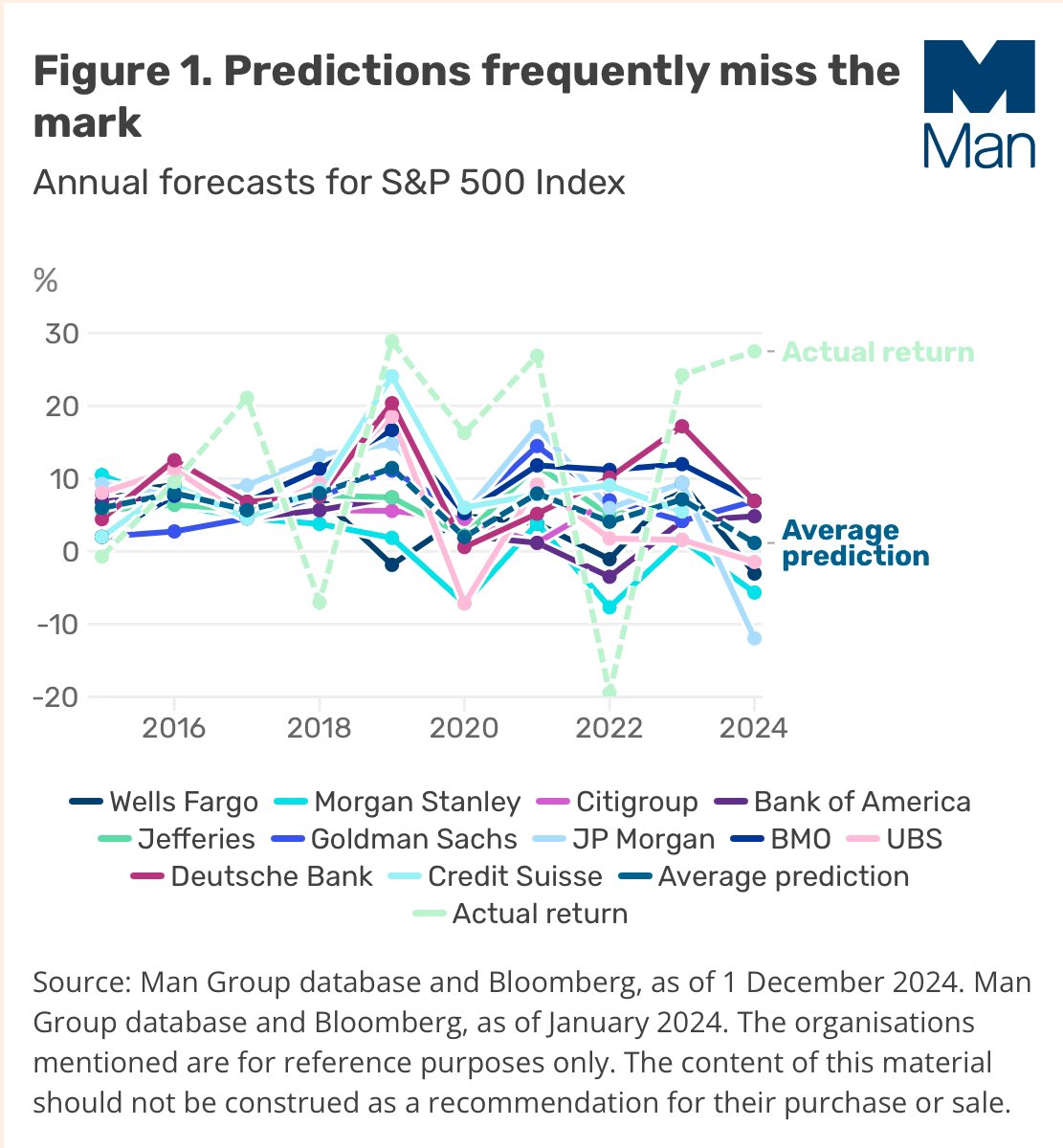
Every person making forecasts should have these framed on their desks:
1. Implied interest rate forecasts vs actual rates
2. Yearly S&P500 predictions
We achieved AGI today, wether you like it or not and I explain you why
Because I was criticized by some people first an explanation: I am very well aware that the 87.7% in Arc-AGI does not (!) mean that AGI is there. The Arc-AGI is not (!) the only evidence for AGI. Nobody has claimed that. Those who follow me will probably have read my 100-page analysis “Scale is all you need?” by Matthew Berman, where I devoted 5 pages exclusively to the question of what the definition of AGI is. So what is the definition? There is none! There is no single definition of what AGI is. Google DeepMind has made a distinction in different levels with their levels in narrow and general, OpenAI on the other hand makes AGI to 5 “levels”, which includes that it must 1) be agentic and 2) lead its own organization to be level 5 AGI.
I am posting the definitions here.
In this respect, I am considering for myself what it means that we have AGI. I have asked myself whether agentic is a necessary criterion, and for me it is not. Why? I stick closely to the term: an artificial intelligence, not an artificial presence and not an artificial agent. For me, intelligence is a capacity for knowledge, a solution orientation. It doesn't necessarily have to be embodied. It can be, but it doesn't have to be. And if you define the term more broadly, an embodied AGI would be something like a “broad” AGI.
So why do I say that we now have AGI?
Because we have beaten almost all (!) of the benchmarks set by us humans. They are almost “saturated”. We ourselves and numerous researchers have repeatedly set limits that have always been so difficult that people thought an AI could not solve them for many years. We have repeatedly tightened the benchmarks and made them more difficult.
In 2022, it started with the fact that an AI could initially offer good solutions based on general knowledge. The answers got better and better over the months, but math was a big problem and there was a knowledge cutoff. There were also major problems with hallucinations. With reasoning models, the math got better and better; so good, in fact, that it took top places in the Math Olympiad. In addition, reasoning has also reduced hallucinations so that we are now in an area where there are still hallucinations, but they are becoming less and less. Knowledge-cutoff is also becoming less relevant in many areas due to webcrawlers such as SearchGPT. In short: in many areas, LLMs and reasoning have brought the models up to PhD level.
However, we have considered even more difficult benchmarks, such as Arc-AGI. Especially for AI outstandingly hard tasks. Until yesterday, the best model had reached about 50%. In addition, the models were a little different with their own priorities. Sonnet 3.5 was good at coding, ChatGPT at creative work and Gemini at context-window.
Today, however, the decisive turning point for me, which explains why we have AGI. o3 is the first model that is so good in all the areas shown above that it is better than PhD everywhere. It is the best model in coding, excels in math, if you want current knowledge you take GPT-4o with Search (which will surely come for o3 as well) and also excels in general knowledge. In short: With o3 we have for the first time a model that is so outstanding in all areas that it is now a real, genuine general (!) intelligence at PhD level. Yes, there are certainly still problems and it will not be able to solve everything. But nobody says that AGI has to be perfect, we can apply this criterion to ASI. Just as PhDs make mistakes, o3 will also make mistakes. Nevertheless: o3 is the first outstanding model that is generally superior and also retains the multimodalities. As I said, the multimodalities are still there, only in the other models. So that together explains to me why OpenAI has achieved AGI.
til, Ilya sutskever gave john carmack this reading list of approx 30 research papers and said, ‘If you really learn all of these, you’ll know 90% of what matters today.’
https://t.co/6eNmrgyq7k
We trained a robot dog to balance and walk on top of a yoga ball purely in simulation, and then transfer zero-shot to the real world. No fine-tuning. Just works.
I’m excited to announce DrEureka, an LLM agent that writes code to train robot skills in simulation, and writes more code to bridge the difficult simulation-reality gap. It fully automates the pipeline from new skill learning to real-world deployment.
The Yoga ball task is particularly hard because it is not possible to accurately simulate the bouncy ball surface. Yet DrEureka has no trouble searching over a vast space of sim-to-real configurations, and enables the dog to steer the ball on various terrains, even walking sideways!
Traditionally, the sim-to-real transfer is achieved by domain randomization, a tedious process that requires expert human roboticists to stare at every parameter and adjust by hand. Frontier LLMs like GPT-4 have tons of built-in physical intuition for friction, damping, stiffness, gravity, etc. We are (mildly) surprised to find that DrEureka can tune these parameters competently and explain its reasoning well.
DrEureka builds on our prior work Eureka, the algorithm that teaches a 5-finger robot hand to do pen spinning. It takes one step further on our quest to automate the entire robot learning pipeline by an AI agent system. One model that outputs strings will supervise another model that outputs torque control.
We open-source everything! Welcome you all to check out the paper, more videos, and try the codebase today: https://t.co/RwiBT3z78H
Code: https://t.co/ERp4Gl0N36
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
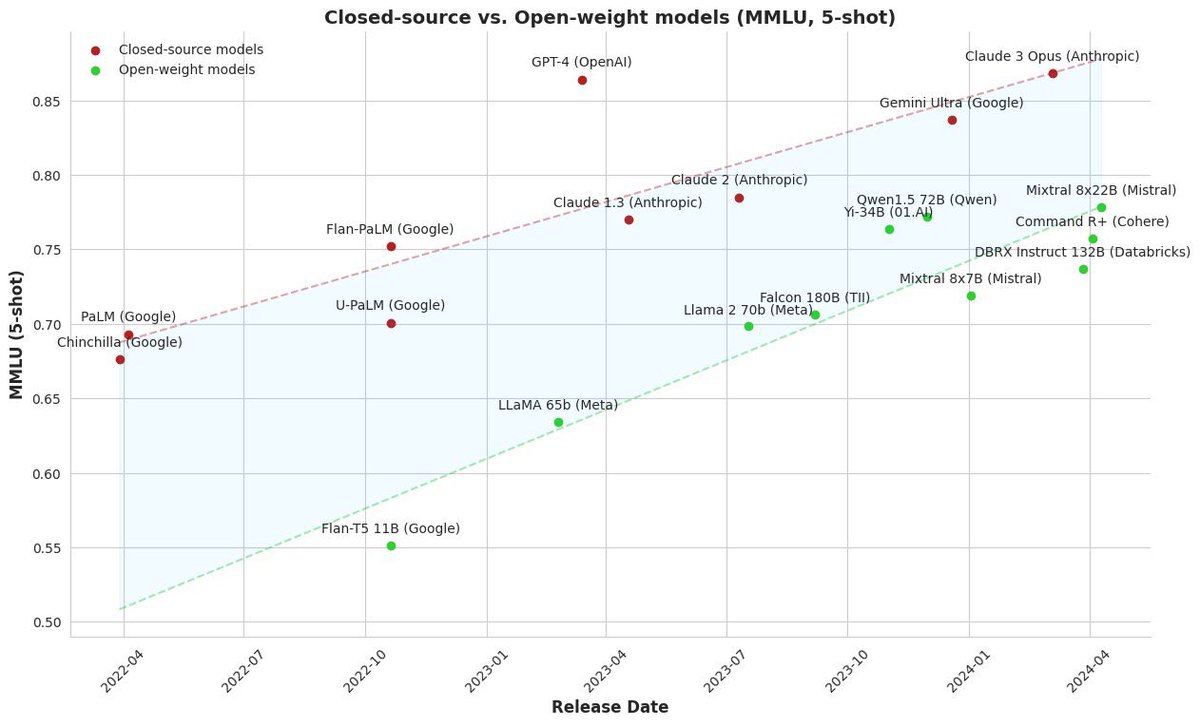
The gap between open and closed source LLMs is narrowing!
Inevitably, it will fully close and OSS will catch up by the end of the year! Even with GPT-5 in the arena!
Now that we have about two dozen LLMs in the market, here are the dimensions that matter when it comes to using them.
Reasoning - Claude 3 Opus beats everything out
Code - GPT-4 is still king here
Cost - Claude Haiku is your best bet
Latency - Claude or a local open-source model is worse best
Fine-Tuning - If you must fine-tune, I would vote for Mistral.
Best Local Model - If your security team throws a fit for no good reason and insists on a local model - Qwen 72B or Smaug-2 (fine-tune on Qwen). Qwen 72B instruct is on top of the human eval leaderboard.
Best small local model - Starling-7b. Again, on top of that leaderboard.
I purposely didn't include the extended context here as it has yet to translate to good context understanding. For now, I prefer sticking to 128K and dealing with it.
Stanford researchers just introduced Octopus v2, a groundbreaking new framework for on-device AI agents.
It outperforms GPT-4 in accuracy by fine-tuning language models with special functional tokens.
The new era of on-device AI agents is coming.
https://t.co/oE13AmrBf4