Had the surreal experience of telling a room full of computer vision researchers at the ICCV25 AC workshop why “computer vision researcher” won’t be a thing in 5 years 🌶️
Of course, this was an extreme stance to keep things lively in a fun debate setting but it echoed some of my own internal monologue over the past few years as someone who has identified as a computer vision researcher for the last decade.
The argument went as follows:
⚡️a research community needs a set of core problems and methods that are specific to that community
⚡️the vision community used to have these 10-15yrs ago but today’s general purpose multimodal architectures assume very little about the input/output modality and are likely to subsume more tasks and modalities over time
⚡️time and again we have had to swallow the bitter pill — methods that bake human intuition into learning algorithm might show gains in the short term but are eventually surpassed by more general methods that utilize more data and compute - llms, vlms, sora, genie etc
⚡️gains in vision systems over the last many years have come from things that have nothing to do with vision or images but general advances in deep learning - optimizers, normalization layers, attention, residual connections, quantization, parallelization methods, larger models etc. Computer vision ends at tokenization and then deep learning and distributed systems engineering take over.
⚡️so not only would “vision researcher” be obsolete, we must actively fight the urge to play a “computer vision researcher” to avoid our biases from creeping into our AI systems
⚡️in short, there is nothing uniquely vision in today’s computer vision research and there is too much overlap with other specialized communities like robotics, graphics etc
Thanks again @ICCVConference PCs for hosting the debate and @anikembhavi for inviting me to participate! It was incredibly awesome for everyone at the AC workshop to take this discussion in a fun spirit 🙌
Arguing for the motion with me were @sarameghanbeery and @RoozbehMottaghi
In our opposition were @HildeKuehne@aagrawalAA and @bluevincent
If you are a vision researcher, share your thoughts whether you agree or not!
VLAs have become the fastest-growing subfield in robot learning. So where are we now?
After reviewing ICLR 2026 submissions and conversations at CoRL, I wrote an overview of the current state of VLA research with some personal takes:
https://t.co/OMMdB1MHtS
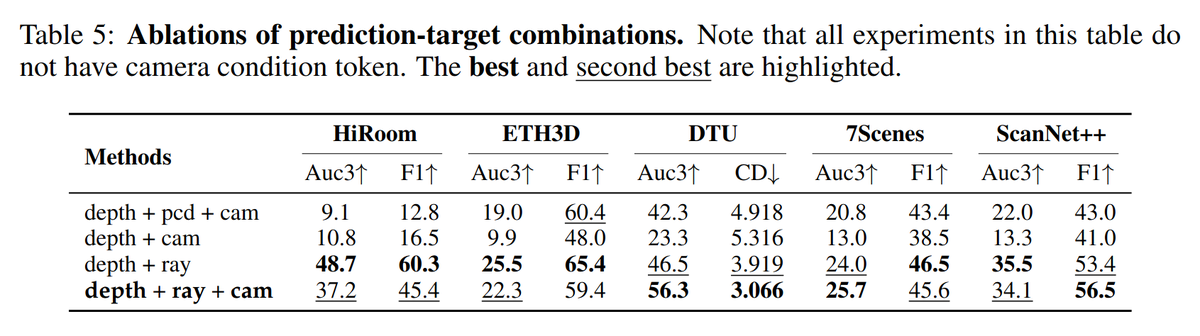
Is the terror reign of redundant scene representations ending? Where VGGT, CUT3R, and other recent models relied on godless redundant outputs (depth+points+pose) without guaranteeing internal prediction consistency, MapAnything and DepthAnything 3 are now heroically pushing back.
𝗗𝗟𝗥 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗲𝗿𝘀 𝗴𝗮𝘃𝗲 𝗮 𝗿𝗼𝗯𝗼𝘁𝗶𝗰 𝗮𝗿𝗺 𝗳𝘂𝗹𝗹-𝗯𝗼𝗱𝘆 𝘁𝗼𝘂𝗰𝗵 𝘀𝗲𝗻𝘀𝗶𝘁𝗶𝘃𝗶𝘁𝘆 𝘄𝗶𝘁𝗵 𝗻𝗼 𝗮𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝘀𝗸𝗶𝗻 𝗻𝗲𝗲𝗱𝗲𝗱.
They used internal force-torque sensors at 8 kHz + deep learning. The robot can feel where you touch it, recognize letters drawn on its surface, and respond to virtual buttons placed anywhere on its body.
What's interesting is the infrastructure behind it. To train these models, you need high-frequency sensor streams, manifold learning to unfold trajectories, and the ability to iterate fast.
They collected 2,300 samples from 20 people and hit 95.5% accuracy on digit recognition.
This is what's possible when you have the right data infrastructure.
📄 https://t.co/yadvb1iKnW
Video credit: @DLR_en
Can mathematical models of history help us escape the worst outcomes?
@Peter_Turchin, the pioneering complexity scientist, and Interintellect founder @TheAnnaGat explore his groundbreaking work on cliodynamics, recurring cycles of societal collapse, and America's current position on the brink of upheaval.
Watch the full, thought-provoking conversation: https://t.co/68LIUvaIcw
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
https://t.co/fYV4FPi71m
🎉CameraBench has been accepted as a Spotlight (3%) @ NeurIPS 2025. Huge congrats to all collaborators at CMU, MIT-IBM, UMass, Harvard, and Adobe.
CameraBench is a large-scale effort that pushes video-language models to reason about the language of camera motion just like professional cinematographers.
🌍 Our open-source dataset, models, and code are also gaining strong interest and adoption from frontier labs such as DeepMind and Kling to advance video generation research.
📄Paper: https://t.co/Rn6pArwdlv
🌐 Website: https://t.co/RnVQfzSiUc
Inspired by recent convos on ViPE, VGGT, and MapAnything—e.g., @rsasaki0109, @ducha_aiki, @gabriberton.
Optimized VGGT for Apple Silicon with MPS for efficient 3D recon on Macs!
Repo: https://t.co/VIASbJldD3
1/4
I was lucky to work in both China and the US LLM labs, and I've been thinking this for a while. The current values of pretraining are indeed different:
US labs be like:
- lots of GPUs and much larger flops run
- Treating stabilities more seriously, and could not tolerate spikes in large flops run, thus invented so many stability-related tricks, including all kinds of soft-cap, MuP, and spectral norm control tricks
- Treats predictabilities more seriously. Check GPT 4 report for reference, even trying to predict the eval task performances
- Because of the stability and predictability ask, treats hyper-params and optimization more seriously
- Generally believe more in data, optimization than arch
China labs be like:
- has very limited GPUs, e.g. k2 in 4k GPU and v3 in 2k GPU
- as a result, pushing for the limit of pretrain modeling-infra co-design, see so many tricks in V3, and K2 has some cool stuff too (the offload trick helps remove the stupid MoE gating constrain and only uses EP 16)
- cares model arch/token efficiency over optimization, stability
- cares more about data quality than data quantity
- taking inference into consideration day 0, even before the training starts
In general, China labs are trying to use <4e+24 flops models to catch up with >1e+25 flops models. It is hard or impossible, but they are making good progress.
I am actually very happy to see Qwen's new try on model archs, they used to be focusing more on data side rather than on model arch side. They developed linear attn, not just for people to think they are innovating, it is actually considering pushing the limit for test time scaling. Llama4 failed for many reasons, but qwen-next is different. They just used very limited flops and it is a brave try for good reasons.
@fchollet@generativist You say this but a lot of early to mid 20th century physics papers were like "notes about what kind of things I'm thinking about the stuff we are all thinking about" 😛
Towards the Next Generation of 3D Reconstruction
@Parskatt PhD Thesis.
tl;dr: would be useful in teaching image matching - nice explanations. (too) Fancy and stylish notation. Cool Ack section and cover image.
https://t.co/ugQmYu5t3S
Introducing: Hyperscape Capture 📷
Last year we showed the world's highest quality Gaussian Splatting, and the first time GS was viewable in VR.
Now, capture your own Hyperscapes, directly from your Quest headset in only 5 minutes of walking around.
https://t.co/PsS1x4hyaf
Goodbye SOGS, hello SOG! 👋
PlayCanvas open sources Spatially Ordered Gaussians - a new super-compressed format for 3D Gaussian Splatting.
https://t.co/XPe1aY4fub
How AI Taught Itself to See
Self-supervised learning is fascinating! How can AI learn from images only without labels?
In this video, we’ll build the method from first principles and uncover the key ideas behind CLIP, MAE, SimCLR, and DINO (v1–v3).
Video 👇
AI is great at hitting explicit goals, but often at the cost of the hidden ones.
Terence Tao just wrote about this. He points out: AI is the ultimate executor of Goodhart’s law, i.e. when a measure becomes the target, it stops measuring what we care about.
Take a call center. Management sets a KPI: “shorten average call time.” Sounds reasonable: shorter calls should mean faster resolutions, happier customers.
At first, it works. Agents become more efficient. But soon, people start gaming it: nudging customers to hang up when the problem is tricky, or just dropping the call themselves.
The numbers look amazing. Call times plummet. But customer satisfaction? Straight into the ground.
Now replace “call time” with “prove theorem X.”
If human mathematicians did it, they’d refine definitions, polish lemmas, contribute back to Mathlib, train juniors, deepen the understanding of math structures, and strengthen the community.
The AI, by contrast, optimizes only for the explicit goal. It might generate a 10,000-line proof in hours. Perfectly correct, but unreadable, unusable, and useless for human learning.
The summit is reached but the forest along the way is gone.
We need to start making our implicit goals explicit and design systems that protect the values we actually care about, not just the numbers we can measure.
If you do functional programming (like in Wolfram Language) you've probably used lots of pure functions, or lambdas. But what are lambdas like in the wild? Things I'm doing in CS, bio and ML converged to make me curious to find out... And as seems to happen whenever I go exploring in the computational universe ... they surprised me ...
https://t.co/N6kD5SaboN