What if your #containerd snapshotter skipped the host mounts entirely? 🚀
Introducing nexus-erofs: Pulls OCI images, converts layers to #EROFS on-the-fly, merges multiple layers into a single VMDK, and passes it directly to your VM via virtio-blk. The guest handles mounting-zero host overhead!
🧪 Experimental plugin for #containerd in VM runtimes
GitHub: https://t.co/8fXRqqUPM1
Built qemubox: experimental containerd shim that runs containers in lightweight QEMU/KVM VMs:
- ~300ms boot with full systemd
- Docker works inside the VM
- Snapshot & commit like regular images
Demo: https://t.co/L0e90zw11z
GitHub: https://t.co/GsimqOCgwj
Total unified memory: 2TB @ 3.2TB/s.
Apple Silicon leads in memory / memory bandwidth unit economics.
This is what matters for local AI where batch_size is small and workloads are memory-bound.
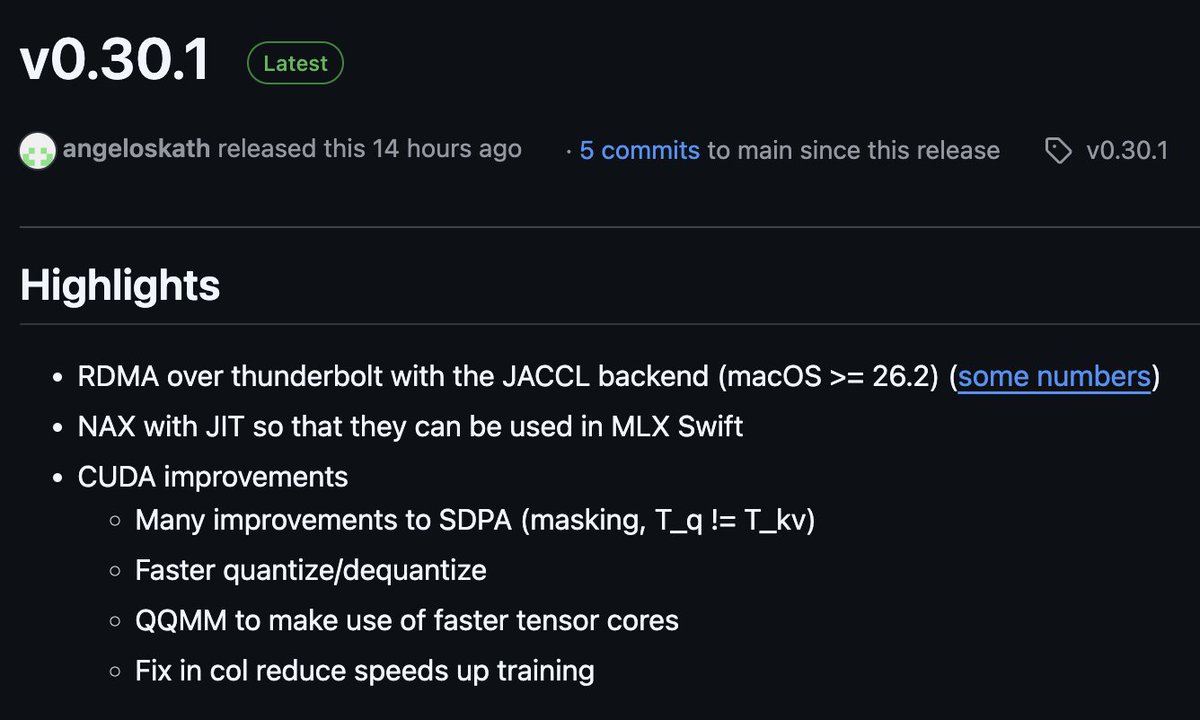
The latest MLX is out!
And it has a new distributed back-end (JACCL) that uses RDMA over TB5 for super low-latency communication across multiple Macs.
Thanks to @angeloskath
LLMlet: P2P distributed LLM inference on browsers with Wasm-compiled llama.cpp + WebRTC
Repo: https://t.co/v0pJciWWxt
Demo: https://t.co/Zq3jCj7fMa
A model can't fit in a tab can be split and run on multiple browsers. Still experimental and missing parallelism and TURN service.
Wrapping up my nearly five-year journey at Gitpod today! Grateful for all the experiences and the amazing people I've met along the way.
On to the next chapter! 🚀
NVIDIA sent us 2 DGX Sparks.
For a while we wondered what we would do with them.
The memory bandwidth is 273GB/s making it 3x slower than an M3 Ultra (819GB/s) for batch_size=1 inference. But it has 4x more FLOPS (100 TFLOPS compared to 26 TFLOPS).
So we thought, what if we could combine the DGX Spark & M3 Ultra, and make use of both the massive compute on the DGX Spark and the massive memory-bandwidth on the M3 Ultra.
We came up with a way to split inference across both devices and achieve a speedup of up to 4x for long prompts compared to the M3 Ultra on its own.
Full details in the blog post linked below.
Qwen3-Next, or to say, a preview of our next generation (3.5?) is out!
This time we try to be bold, but actually we have been doing experiments on hybrid models and linear attention for about a year. We believe that our solution shoud be at least a stable and solid solution to new model architecture for super long context!
GDN plus hybrid is based on a lot of trials and errors, and the implementation of attention gate is something just like a free lunch to get benefits.
Moreover, we continue our research on MoE and carefully further increase the sparsity to make it more efficient and effective!
What makes us suffer a lot is that you need to run the whole process of training to evaluate new model architecture, which means pre-training + post-training (notably reinforcement learning). We have proven it working and we release the instruct and thinking models both after RL.
Nevertheless, as this is for the first time that we release something totally new, we are still unsure about what we have done right or wrong, and we need the support from the community. Specifically, many thanks to Hugging Face, vLLM, and SGLang. They have done quite a lot of efforts helping us deliver this new model to you all! Welcome to try and send us feedback!
Hope it is a good start of a new journey 🚗
Linear scaling achieved with multiple DeepSeek v3.1 instances. 4x macs = 4x throughput.
2x M3 Ultra Mac Studios = 1x DeepSeek @ 14 tok/sec
4x M3 Ultra Mac Studios = 2x DeepSeek @ 28 tok/sec
DeepSeek V3.1 is a 671B parameter model - so at its native 8-bit quantization, it requires ~700GB of memory to run the model. EXO puts half of the layers on each device, combining their memory. EXO uses MLX distributed with TB5 interconnect, optimized for Apple Silicon.
If we need higher throughput, adding two more devices lets us serve more users at once. @exolabs handles all of this seamlessly - adding more devices to the cluster for linear scaling as we need it.
The new EXO 1.0 will be open-source soonTM
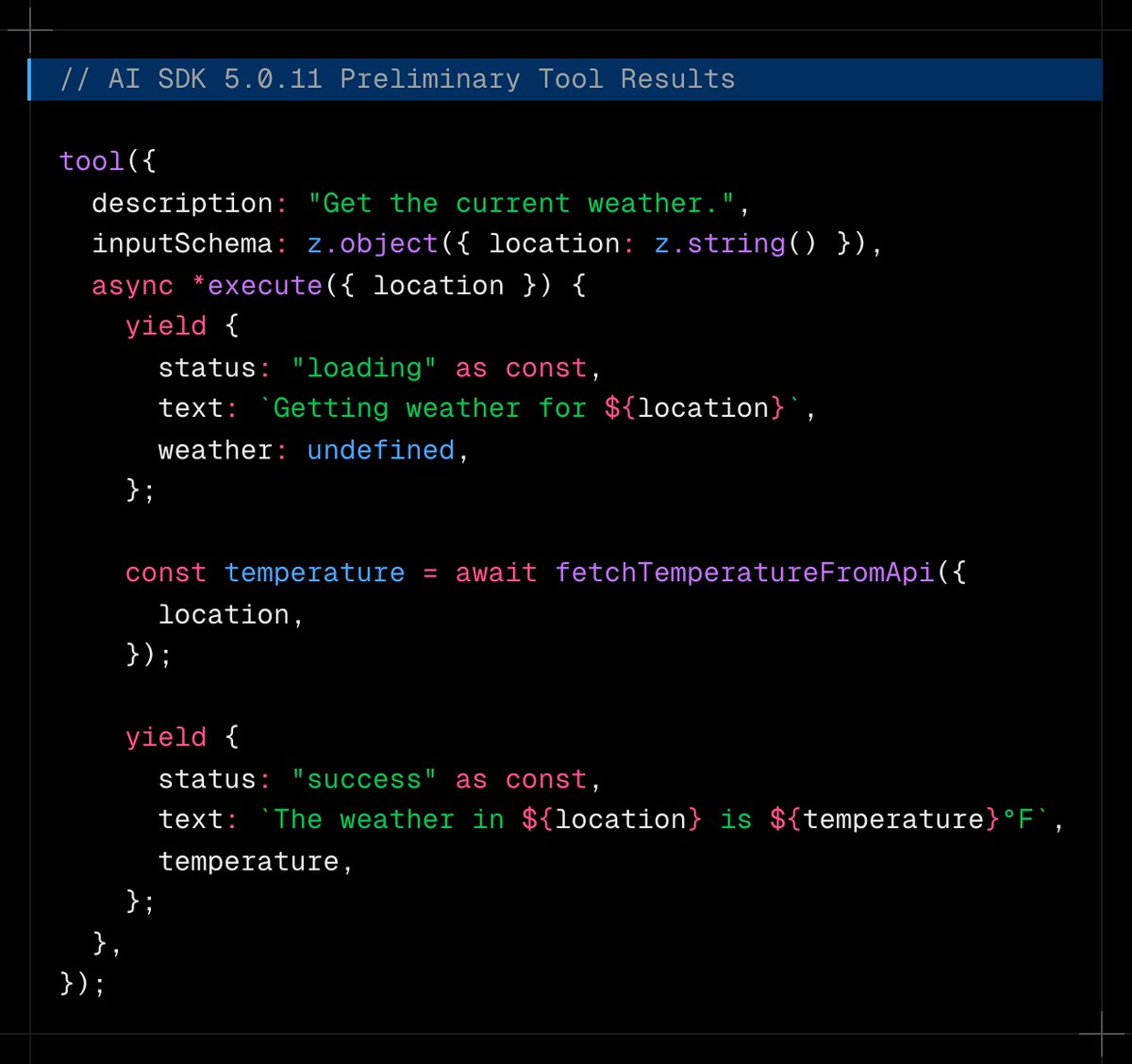
Got inspired so I recreated a demo of this w/ Claude Code & Vercel Sandbox
Each thread gets their own sandbox to develop in, but if you wanted to they could all use the same sandbox via worktrees
🚀 Amazing community project!
vLLM CLI — a command-line tool for serving LLMs with vLLM:
✅ Interactive menu-driven UI & scripting-friendly CLI
✅ Local + HuggingFace Hub model management
✅ Config profiles for perf/memory tuning
✅ Real-time server & GPU monitoring
✅ Error logs & recovery
📦 Install in one line:
pip install vllm-cli
GitHub: https://t.co/FnfE0dtZ03
👉 Would you like to see these features in vLLM itself? Try it out & share feedback!
Something deeply ironic: how startups asking for devs to put in 6+ days per week, 80+ hour per weeks are... AI startups
You'd assume that the value add of AI could be humans needing to do less work! So devs could spin off agents, go home and sleep. But no, doesn't work like this
We'll continuously enhance the qwen code (cli tool) based on your feedback and even release improved qwen-coder (model)! Our goal is to match Claude Code's performance while remaining fully open-source!