Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini 🚀
Today, we’re sharing the @GoogleDeepMind white paper for GE 2, our first native multimodal embedding model. Whether it’s text, audio, video, or image, GE 2 provides a unified representation of the input.
been asking others at Anthropic how they stay in the loop with Claude and fully understand the work being done
this is one of my favorites from Suzanne:
instead of watching 2 hours of Netflix tonight, watch this Stanford lecture
it's the clearest explanation I've seen of how ChatGPT and Claude actually work
useful whether you've never touched AI in your life or have been using it every day for the past year
I took the key ideas and turned them into a practical guide on how to actually get 100% out of Claude
find it below
This 2-hour Stanford lecture breaks down how models like ChatGPT and Claude are actually built, clearer than what many people in top AI roles ever get exposed to.
Save this and set aside two hours today. It might end up being the most valuable thing you learn all week.
Most people prompt Claude.
Andrej Karpathy designs cognition.
Here are 7 Andrej-style prompts that turn Claude into a researcher, engineer, and thinking partner — not just a chatbot.
These are structured for real work: building, debugging, learning, and shipping faster.
Bookmark this. You’ll reuse them every day.
🚀MIT Flow Matching and Diffusion Lecture 2026 Released (https://t.co/bKgs2wghvY)!
We just released our new MIT 2026 course on flow matching and diffusion models! We teach the full stack of modern AI image, video, protein generators - theory and practice. We include:
📺 Videos: Step-by-step derivations.
📝 Notes: Mathematically self-contained lecture notes
💻 Coding: Hands-on exercises for every component
We fully improved last years’ iteration and added new topics: latent spaces, diffusion transformers, building language models with discrete diffusion models.
Everything is available here: https://t.co/bKgs2wghvY
A huge thanks to Tommi Jaakkola for his support in making this class possible and Ashay Athalye (MIT SOUL) for the incredible production! Was fun to do this with @RShprints!
#MachineLearning #GenerativeAI #MIT #DiffusionModels #AI
After 6 months of using NotebookLM, I can say it's the research tool that has revolutionized my workflow the most.
But only because I learned these 10 prompts.
Here's the complete system that turns 200 pages into clear answers in under an hour:
BREAKING: Claude can now research like a Stanford PhD student.
Here are 9 insane Claude prompts that turn 40+ research papers into structured literature reviews, knowledge maps, and research gaps in minutes (Save this)
I accidentally discovered how to compress a semester of learning into 48 hours.
A grad student at MIT showed me his NotebookLM setup. I thought he was just organized. Then I watched him pass a qualifying exam on a subject he'd never studied before.
Here's exactly what he did:
First: he didn't upload a textbook.
He uploaded 6 textbooks, 15 research papers, and every lecture transcript he could find on the subject.
Then he asked NotebookLM one question:
"What are the 5 core mental models that every expert in this field shares?"
Not "summarize this." Not "explain this topic."
Mental models. The stuff that takes professors years to develop.
But the next part is what broke my brain.
He followed up with:
"Now show me the 3 places where experts in this field fundamentally disagree, and what each side's strongest argument is."
In 20 minutes he had a map of the entire intellectual landscape of the field:
the debates, the consensus, the open questions.
Most students spend a full semester just figuring out what those debates even are.
Then he did something I've never seen before.
He asked:
"Generate 10 questions that would expose whether someone deeply understands this subject versus someone who just memorized facts."
He spent the next 6 hours answering those questions using the source material. Every wrong answer triggered a follow-up:
"Explain why this is wrong and what I'm missing."
By hour 48, he could hold a conversation with his thesis advisor without getting destroyed.
The tool didn't change. The questions did.
Most people treat NotebookLM like a fancy highlighter.
These students are using it like a private tutor who has read everything ever written on the subject.
The difference between a semester and 48 hours isn't the amount of content.
It's knowing which questions to ask.
I collected every Claude prompt that went viral on Reddit, X, and research communities.
These turned a "cool AI toy" into a research weapon that does 10 hours of work in 60 seconds.
13 copy-paste prompts. Zero fluff.
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
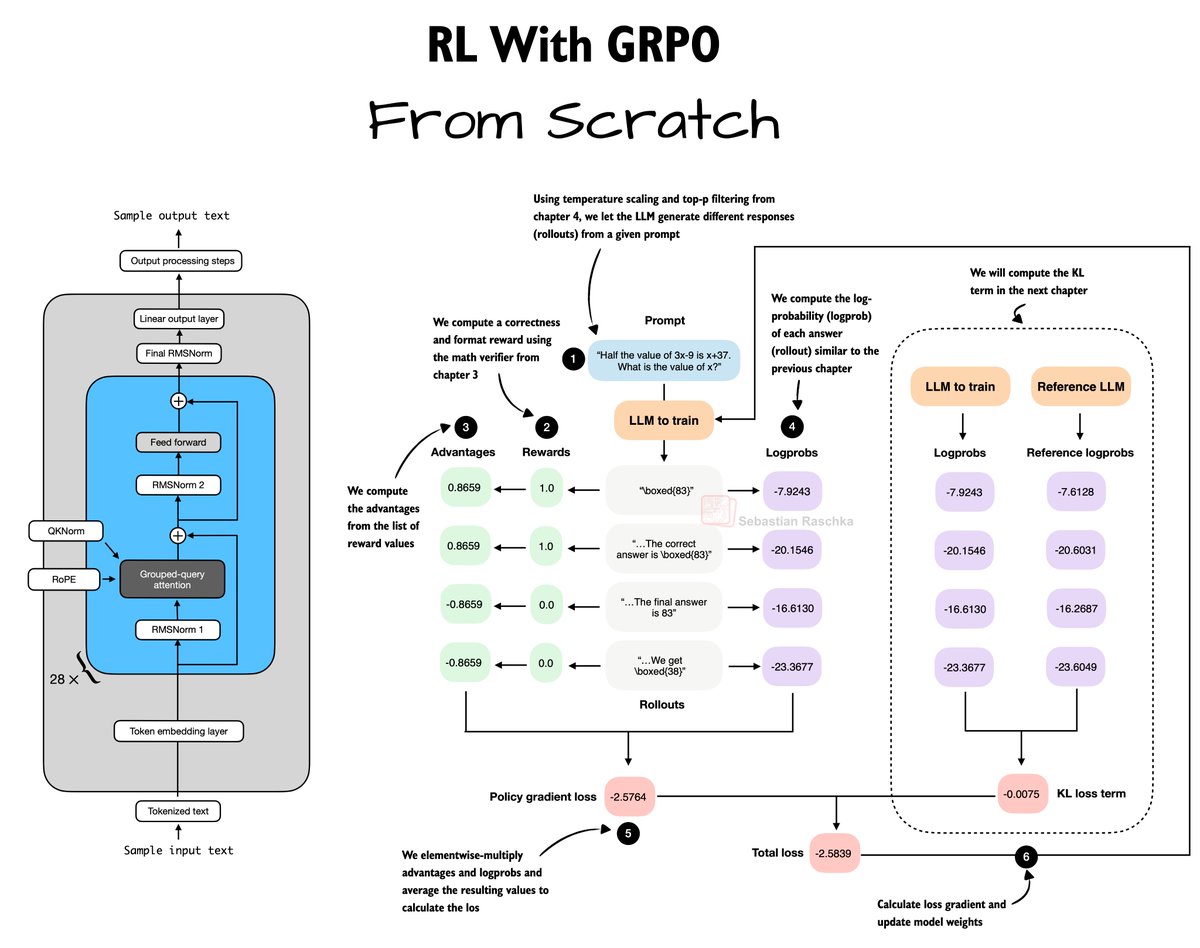
I have been pretty heads-down this year to finish Chapter 6 on implementing reinforcement learning with verifiable rewards from scratch (using GRPO). I just finished it this weekend, and I'd say it's the best (or at least my favorite) chapter yet!
The goal of this chapter is to explain and implement GRPO from the bottom up. This means coding and walking through each GRPO step one by one (advantages, rewards, logprobs, and loss) and then training a 0.6B base model on the 12k examples from the MATH training set.
(This takes the model from 15% to 47% accuracy on the MATH-500 test set, which is about as good as the official Qwen3 reasoning model of similar size.)
The focus is on readability and understanding GRPO, but the supplementary materials also contain scripts to run it in a multi-GPU setting.
The code notebook is already available on GitHub if you want to take a look: https://t.co/SM58MXjf8V.
(And the full chapter should make it to the early access version of the book at https://t.co/vzCr5sTjrf soon!)
PS: The next chapter will introduce additional tips and tricks to improve the GRPO algorithm for better and more stable training behavior.
Google trained a model on millions of users' messages.
Without ever seeing a single message.
It's called Federated Learning. Google, Apple, Meta, and every major tech company use it.
Let me explain how it works:
Imagine you want to build a keyboard that predicts what users type next.
The best training data? Actual messages from millions of phones. But you can't collect it. It's private, sensitive, and users would revolt.
Federated learning flips the script. Instead of bringing data to the model, you bring the model to the data.
Here's how:
"Send the model out."
Your phone downloads a small neural network. It lives locally on your device.
→ This is the global model W
"Train where the data lives."
As you type, your phone quietly learns your patterns. "omw" → "be there in 10". It calculates how the model should improve.
→ These are local gradients ΔW
"Send back only the learnings."
Your phone sends weight updates to the server. Not your messages. Not your typing history. Just math.
→ This is the update aggregation step
"Average across thousands of devices"
The server combines updates from thousands of phones. Common patterns reinforce. Individual quirks cancel out.
→ This is FedAvg: W_new = W + (1/n) × Σ(ΔWₖ)
Four steps. No raw data leaves your device. Just elegant coordination (refer to the visual below).
The best part:
This unlocks data that was previously impossible to use.
Hospitals collaborate on cancer detection without sharing patient scans. Banks build fraud models without exposing transactions. Smart homes learn preferences without private moments hitting a cloud.
Privacy and utility aren't tradeoffs. Respecting data boundaries is what makes the model possible.
So before you centralize everything, consider: the best training data might already exist, trapped on devices you'll never access directly.
In the next tweet i've shared a really good video explainer on this.
step-by-step LLM Engineering Projects
each project = one concept learned the hard (i.e. real) way
Tokenization & Embeddings
> build byte-pair encoder + train your own subword vocab
> write a “token visualizer” to map words/chunks to IDs
> one-hot vs learned-embedding: plot cosine distances
Positional Embeddings
> classic sinusoidal vs learned vs RoPE vs ALiBi: demo all four
> animate a toy sequence being “position-encoded” in 3D
> ablate positions—watch attention collapse
Self-Attention & Multihead Attention
> hand-wire dot-product attention for one token
> scale to multi-head, plot per-head weight heatmaps
> mask out future tokens, verify causal property
transformers, QKV, & stacking
> stack the Attention implementations with LayerNorm and residuals → single-block transformer
> generalize: n-block “mini-former” on toy data
> dissect Q, K, V: swap them, break them, see what explodes
Sampling Parameters: temp/top-k/top-p
> code a sampler dashboard — interactively tune temp/k/p and sample outputs
> plot entropy vs output diversity as you sweep params
> nuke temp=0 (argmax): watch repetition
KV Cache (Fast Inference)
> record & reuse KV states; measure speedup vs no-cache
> build a “cache hit/miss” visualizer for token streams
> profile cache memory cost for long vs short sequences
Long-Context Tricks: Infini-Attention / Sliding Window
> implement sliding window attention; measure loss on long docs
> benchmark “memory-efficient” (recompute, flash) variants
> plot perplexity vs context length; find context collapse point
Mixture of Experts (MoE)
> code a 2-expert router layer; route tokens dynamically
> plot expert utilization histograms over dataset
> simulate sparse/dense swaps; measure FLOP savings
Grouped Query Attention
> convert your mini-former to grouped query layout
> measure speed vs vanilla multi-head on large batch
> ablate number of groups, plot latency
Normalization & Activations
> hand-implement LayerNorm, RMSNorm, SwiGLU, GELU
> ablate each—what happens to train/test loss?
> plot activation distributions layerwise
Pretraining Objectives
> train masked LM vs causal LM vs prefix LM on toy text
> plot loss curves; compare which learns “English” faster
> generate samples from each — note quirks
Finetuning vs Instruction Tuning vs RLHF
> fine-tune on a small custom dataset
> instruction-tune by prepending tasks (“Summarize: ...”)
> RLHF: hack a reward model, use PPO for 10 steps, plot reward
Scaling Laws & Model Capacity
> train tiny, small, medium models — plot loss vs size
> benchmark wall-clock time, VRAM, throughput
> extrapolate scaling curve — how “dumb” can you go?
Quantization
> code PTQ & QAT; export to GGUF/AWQ; plot accuracy drop
Inference/Training Stacks:
> port a model from HuggingFace to Deepspeed, vLLM, ExLlama
> profile throughput, VRAM, latency across all three
Synthetic Data
> generate toy data, add noise, dedupe, create eval splits
> visualize model learning curves on real vs synth
each project = one core insight. build. plot. break. repeat.
> don’t get stuck too long in theory
> code, debug, ablate, even meme your graphs lol
> finish each and post what you learned
your future self will thank you later
Major preprint just out!
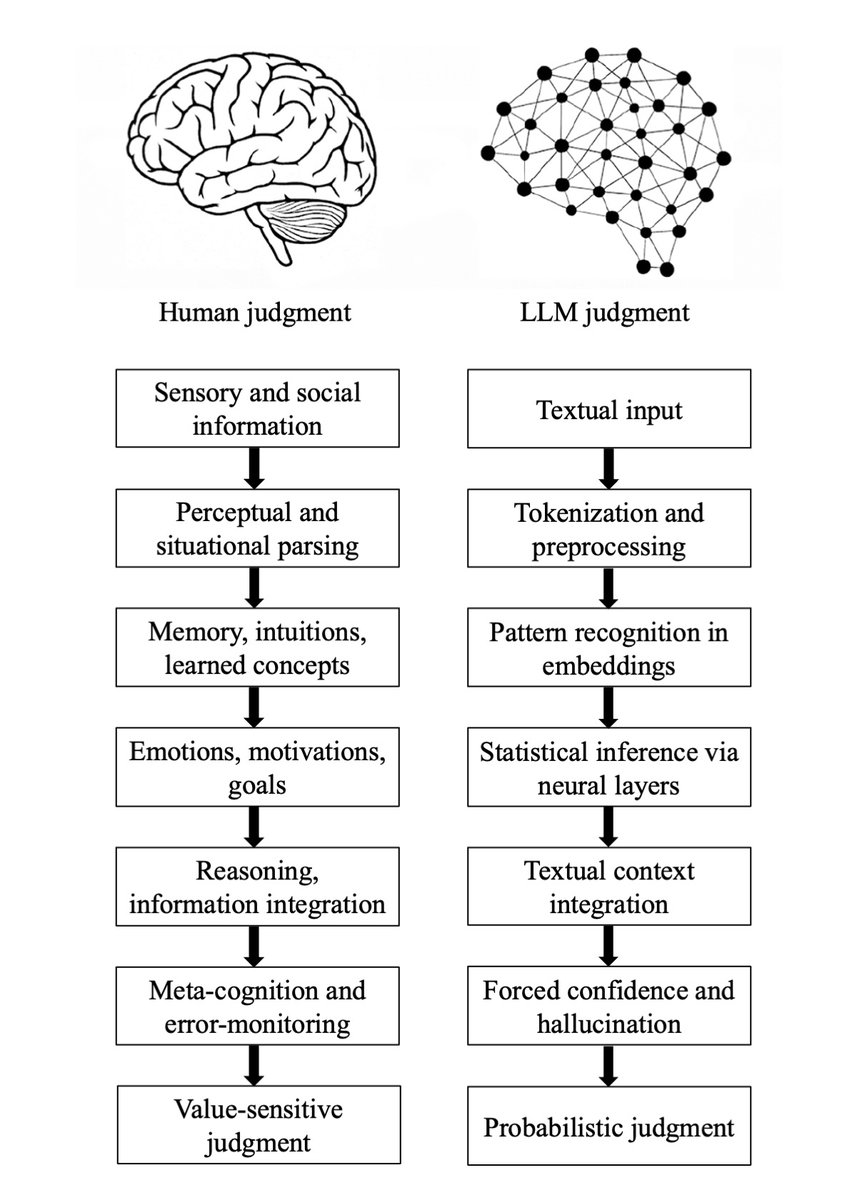
We compare how humans and LLMs form judgments across seven epistemological stages.
We highlight seven fault lines, points at which humans and LLMs fundamentally diverge:
The Grounding fault: Humans anchor judgment in perceptual, embodied, and social experience, whereas LLMs begin from text alone, reconstructing meaning indirectly from symbols.
The Parsing fault: Humans parse situations through integrated perceptual and conceptual processes; LLMs perform mechanical tokenization that yields a structurally convenient but semantically thin representation.
The Experience fault: Humans rely on episodic memory, intuitive physics and psychology, and learned concepts; LLMs rely solely on statistical associations encoded in embeddings.
The Motivation fault: Human judgment is guided by emotions, goals, values, and evolutionarily shaped motivations; LLMs have no intrinsic preferences, aims, or affective significance.
The Causality fault: Humans reason using causal models, counterfactuals, and principled evaluation; LLMs integrate textual context without constructing causal explanations, depending instead on surface correlations.
The Metacognitive fault: Humans monitor uncertainty, detect errors, and can suspend judgment; LLMs lack metacognition and must always produce an output, making hallucinations structurally unavoidable.
The Value fault: Human judgments reflect identity, morality, and real-world stakes; LLM "judgments" are probabilistic next-token predictions without intrinsic valuation or accountability.
Despite these fault lines, humans systematically over-believe LLM outputs, because fluent and confident language produce a credibility bias.
We argue that this creates a structural condition, Epistemia:
linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without actually knowing.
To address Epistemia, we propose three complementary strategies: epistemic evaluation, epistemic governance, and epistemic literacy.
Full paper in the first reply.
Joint with @Walter4C & @matjazperc
I'm obsessed with cognitive biases.
A "cognitive bias" is a systematic error in thinking that destroys decision-making.
11 most powerful (and dangerous) cognitive biases I've found: 🧵
1. Survivorship Bias:
I love the expression “food for thought” as a concrete, mysterious cognitive capability humans experience but LLMs have no equivalent for.
Definition: “something worth thinking about or considering, like a mental meal that nourishes your mind with ideas, insights, or issues that require deeper reflection. It's used for topics that challenge your perspective, offer new understanding, or make you ponder important questions, acting as intellectual stimulation.”
So in LLM speak it’s a sequence of tokens such that when used as prompt for chain of thought, the samples are rewarding to attend over, via some yet undiscovered intrinsic reward function. Obsessed with what form it takes. Food for thought.