@polikarn@thatplguy But! You may (correctly) say: people don't like to write specifications OR types.
One of my other favorite papers is by Ras Bodik (again), about using machine learning to automatically mine specifications from program behavior.
https://t.co/MHioeEKpHk
6/
I'm joining forces with @mikeknoop to start Ndea (@ndeainc), a new AI lab.
Our focus: deep learning-guided program synthesis. We're betting on a different path to build AI capable of true invention, adaptation, and innovation.
The Kalman filter is a widely used algorithm for estimating the hidden states of a dynamic system from a series of noisy measurements. It works by recursively predicting the system's state using a dynamic model, and then updating this prediction with new measurement data. Some key points about the Kalman filter:
- It is an optimal estimator for linear systems with Gaussian noise, minimizing the mean squared error of the estimated state. [2]
- It consists of two main steps: prediction and update. In the prediction step, it estimates the current state based on the previous state and the system dynamics. In the update step, it incorporates a new measurement to correct the prediction. [3]
- It accounts for both process noise (uncertainty in the system dynamics) and measurement noise (errors in the sensor data). [1]
- It requires a mathematical model of the system dynamics (state transition matrix) and the measurement process (measurement matrix). [3]
- The filter is recursive, meaning it only needs the current measurement and the previous state estimate to compute the new state estimate, without requiring storage of the entire measurement history. [2]
- It has found widespread applications in areas like navigation, object tracking, signal processing, and control systems due to its effectiveness and computational efficiency. [2]
The Kalman filter provides an elegant and powerful solution for state estimation problems involving noisy sensor data and uncertain system dynamics, making it a fundamental tool in many engineering and scientific fields. [1][2][3]
The problem with this popular tweet is that DeepSeek is NOT actually a capability improvement per se.
It’s an efficiency improvement; those two are not the same.
here are my notes on @fchollet's neat explanation of the differences between deep learning and program synthesis, and the advantages and disadvantages of each, and how they'd fit together to build AGI.
in deep learning, your underlying model is a differentiable curve; in program synthesis, your model is a discrete graph of operators – you’re picking from a set of operators and structuring that into a program.
this has implications for the amount of compute and data needed for each:
- in deep learning your learning engine is gradient descent, which is very compute efficient – you have a very informative feedback signal about where the solution is. but it's very data inefficient — you need a dense sampling of the data distribution.
- in program synthesis, your learning engine is combinatorial search. this is extremely data efficient (I believe because the problem space is inherently more constrained?), but it’s extremely compute inefficient (because the search space is massive).
how does this apply to AGI? deep learning is great for system 1 thinking; discrete program search is great for system 2 thinking. AGI will likely require a combination of both approaches. Chollet expects that an AGI system would have an outer program that does program synthesis and it will use deep learning to assist it.
I believe that program synthesis will solve reasoning. And I believe that deep learning will solve program synthesis (by guiding a discrete program search process).
But I don't think you can go all that far with just prompting a LLM to generate end-to-end Python programs (even with a verification step and many samples). That won't scale to very long programs.
We have to take the LLMs to school.
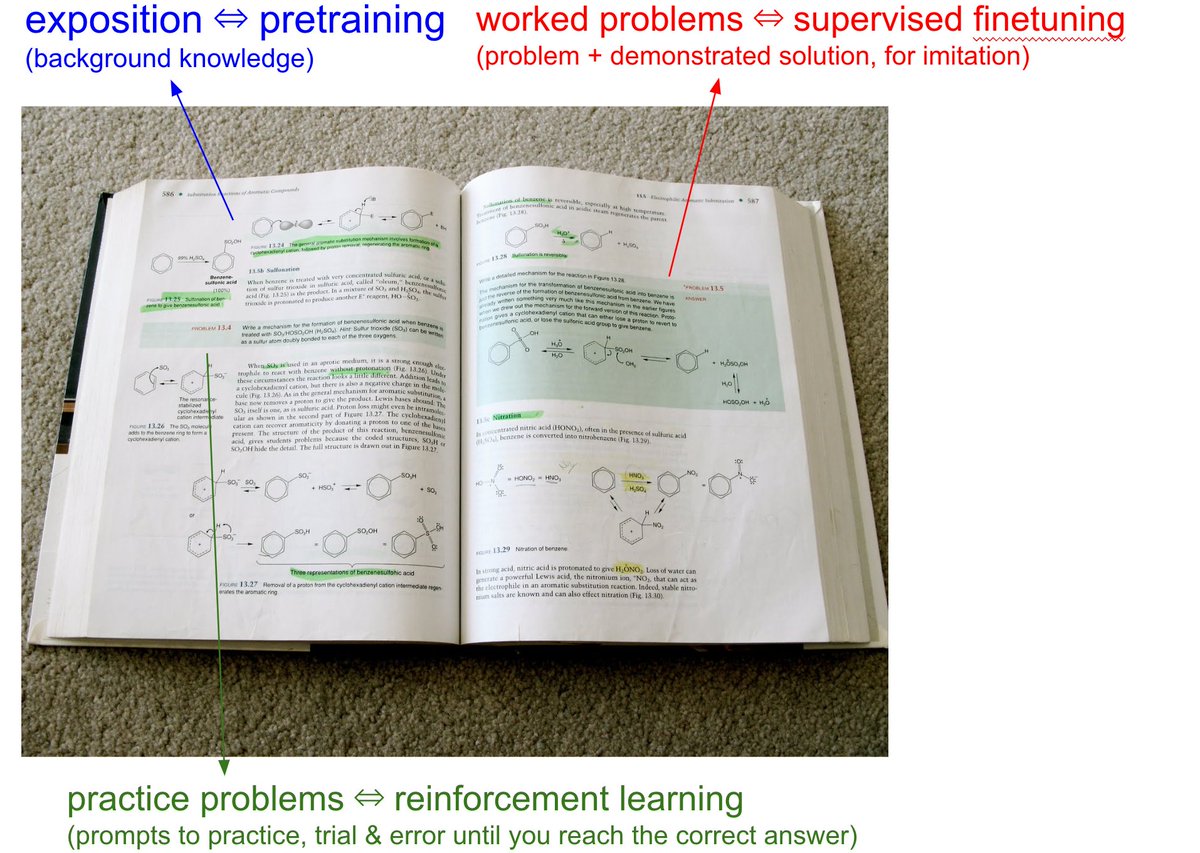
When you open any textbook, you'll see three major types of information:
1. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge.
2. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans.
3. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning.
We've subjected LLMs to a ton of 1 and 2, but 3 is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these 3 types of data. They have to read, and they have to practice.
This might help
https://t.co/T9cz0Wjaow
Also this
https://t.co/U17J9esBhP
Researchers don't actually know. I'm feeding a number of research papers on the topic into notebooklm, to see if it can understand how it behaves.
I have a feeling a user interaction with say Grok, doesn't have the same weight of trained data. So may not force it into new thought processes. Maybe to avoid brainwashing?
want to get into program synthesis but don't know how to started? I wrote a minimalist intro to modern program synthesis that can help you -- from problem formulation to generating code by fine-tuning llm on huggingface.
https://t.co/tzPHmzoQh3



































![burny_tech's tweet photo. The Kalman filter is a widely used algorithm for estimating the hidden states of a dynamic system from a series of noisy measurements. It works by recursively predicting the system's state using a dynamic model, and then updating this prediction with new measurement data. Some key points about the Kalman filter:
- It is an optimal estimator for linear systems with Gaussian noise, minimizing the mean squared error of the estimated state. [2]
- It consists of two main steps: prediction and update. In the prediction step, it estimates the current state based on the previous state and the system dynamics. In the update step, it incorporates a new measurement to correct the prediction. [3]
- It accounts for both process noise (uncertainty in the system dynamics) and measurement noise (errors in the sensor data). [1]
- It requires a mathematical model of the system dynamics (state transition matrix) and the measurement process (measurement matrix). [3]
- The filter is recursive, meaning it only needs the current measurement and the previous state estimate to compute the new state estimate, without requiring storage of the entire measurement history. [2]
- It has found widespread applications in areas like navigation, object tracking, signal processing, and control systems due to its effectiveness and computational efficiency. [2]
The Kalman filter provides an elegant and powerful solution for state estimation problems involving noisy sensor data and uncertain system dynamics, making it a fundamental tool in many engineering and scientific fields. [1][2][3]](https://pbs.twimg.com/media/GLfmpxJWYAAh_uv.jpg)