Interested in whether people👂 each other in a conversation?
🚨New paper accepted at #EMNLP2024 with @tyskevdb and @dongng about detecting paraphrases between speakers
🤖 Detect? https://t.co/pngaXQTwfC
📊 Analyze? https://t.co/eIbqRzJICi
📄 Read? https://t.co/iB5okZnNks
Podcasts are a popular medium, but data for computational research is limited! We introduce the Structured Podcast Research Corpus (SPoRC - https://t.co/iBd8ZfUSmc), a large, multimodal dataset of English podcasts 🧵
https://t.co/UMej1aPzCv
Interested in whether people👂 each other in a conversation?
🚨New paper accepted at #EMNLP2024 with @tyskevdb and @dongng about detecting paraphrases between speakers
🤖 Detect? https://t.co/pngaXQTwfC
📊 Analyze? https://t.co/eIbqRzJICi
📄 Read? https://t.co/iB5okZnNks
#Tokenization is undeniably a key player in the success story of #LLMs but we poorly understand why.
I want to highlight progress we made in understanding the role of tokenization, developing the core incidents and mitigating its problems. 🧵👇
The 34th edition of Computational Linguistics in The Netherlands (the Dutch-Belgian #NLProc conference) will be held @UniLeiden on August 30
The list of accepted abstracts is on the website and registration is open for everyone interested 💬
#clin34
https://t.co/E10OEojtLx
🔎What values and opinions do we see when we use 6 LLMs to generate 156,000 responses to 62 political propositions?
Our paper "Revealing Fine-Grained Values and Opinions in Large Language Models" answers this.
📰 https://t.co/QvDcIiDzN7
#NLProc#LLMs
📢Is current “human-AI alignment” research clarified and comprehensive? 🤔 We systematically reviewed 400+ papers across HCI, NLP, and ML to develop a framework for 👫<>🤖"Bidirectional Human-AI Alignment", encompassing the dual paths of “Aligning AI to Human” and “Aligning Human to AI”. We also clarified core questions 🎯 of 'what is the alignment goal?', 'with whom to align?', and 'what are the human values?’
Further, we share 👩💻 our findings on values and interaction techniques for alignment. Check out the three challenges and potential solutions we envision for future research🌟! #HumanAIAlignment
💎https://t.co/pa3yqjzz6d. 🧵1/
Huge thanks to our amazing team 💗 @tknearem, @reshmigh, Kenan Alkiek, @kundan_official, @YachuanLiu, @ziqiao_ma, @savvas_petridis, @yolohao, Li Qiwei, Sushrita Rakshit, @ChengleiSi, @yutxie, and our fabulous advisors @jeffbigham, @bentley79, Joyce Chai, @zacharylipton, @meiqzh, @radamihalcea, Michael Terry, @Diyi_Yang, @merrierm, @presnick, @david__jurgens! 🙏 Many thanks for all your great effort🤗!
[1/13] LLMs are increasingly skilled at mimicking human agents in social settings, but have they truly developed a consistent personality? Check out our work accepted to #NAACL2024 where we question the reliability of persona tests applied to LLMs.
Arxiv: https://t.co/GbZrtemmS8
📰New preprint! w/ @christian_igel@raghavian📰
BMRS: Bayesian Model Reduction for Structured Pruning
Structured pruning makes neural nets efficient by removing full structures (e.g. neurons).
But how do we know what to prune?
Here's our approach: https://t.co/epxvZFtOJO
📢 JOBS📢
Come work with us @MilaNLProc!
Looking for 2 POSTDOCS (two-year positions w/extension) to work on personalized and subjective approaches to #NLProc.
Deadline: May 30 2024
Start date: from Sep 2024
Link: https://t.co/GaqplXJX0b
Next up in the DiLCo Lecture Series 2024: Christoph Purschke @questoph presenting his multi-method approach to "Monitoring the public debate on multilingualism in Luxembourg". Thursday, April 25 at 4 pm CEST, open access. Registration: https://t.co/mQo8QRo9k7 @unihh
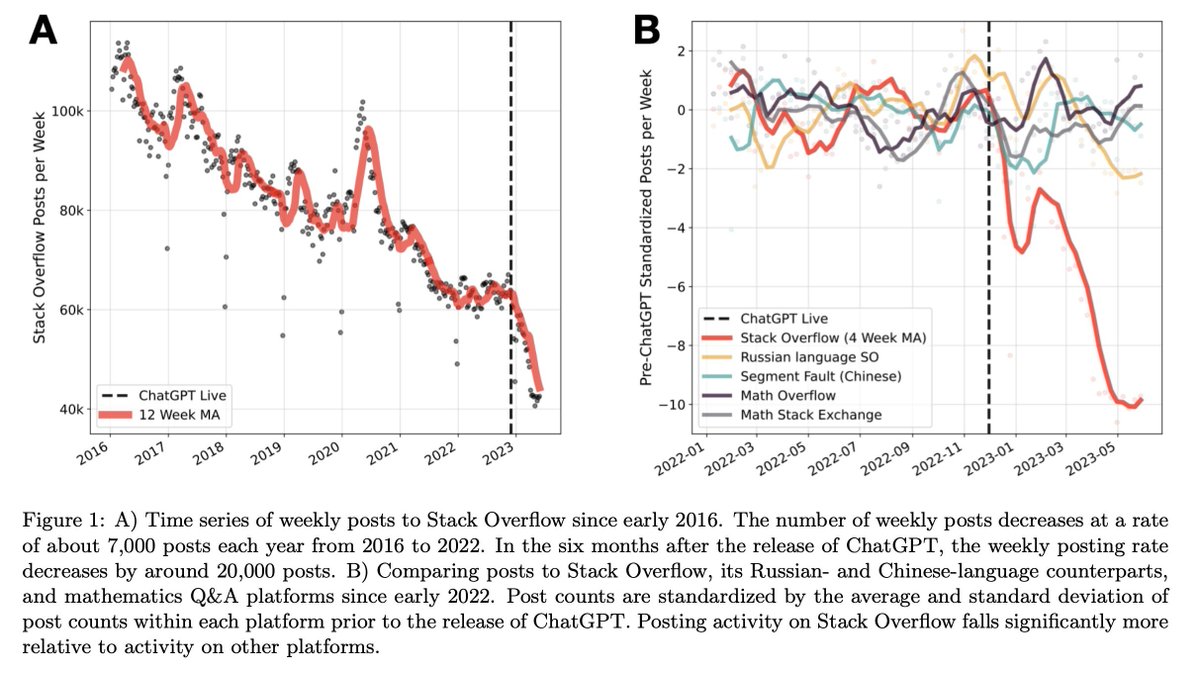
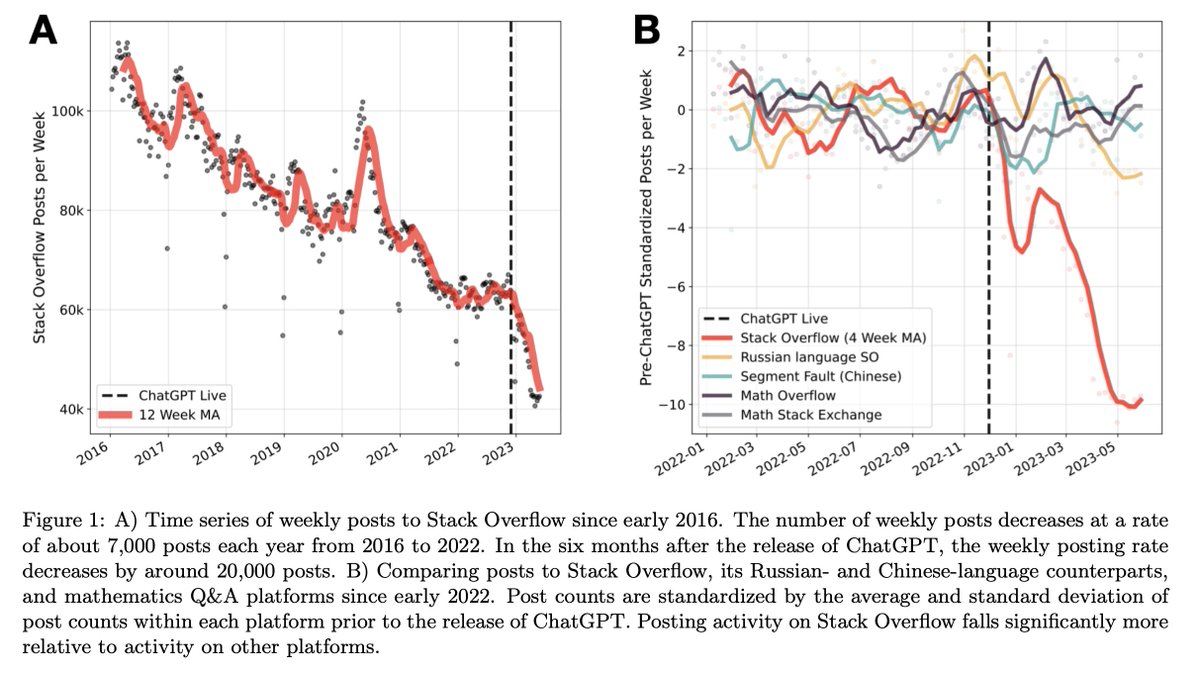
@natfriedman Some colleagues and I have been studying the impact of ChatGPT on SO using data on posts, not views: https://t.co/JnLs4PQggU
Besides a big decrease after ChatGPT, we observe a completely flat 2022, and earlier a big bump in activity during early Covid.
Copenhagen is beautiful & #ic2s2 is amazing, but do you know what’s neither? 🚫 unintended bias towards marginalized people in hate speech detection systems.
Presenting our poster (w/ @hide_yourself@clauwa@IAugenstein) today about how data augmentation can lead to such biases!
🚨 New working paper!
Are Large Language Models a threat to digital public goods?
@RMaria_drc N. Laurentsyeva and I find a 16% decrease in activity on @StackOverflow since release of #ChatGPT. Decrease is language dependent & reaches 25% by June: https://t.co/JnLs4PQggU
Thread⬇️
How does annotator identity influence their judgments for NLP tasks? Collaborating with @Prolific, @david__jurgens and I created POPQUORN: a dataset with 45000 annotations on 4 NLP tasks by 1484 annotators with rich demographic information.
Paper: https://t.co/cpI0NQtb9y
🧵 1/11
It takes 360.000 gallons of water/day to cool a data centre! Exploitation of workers, workplace automation, & mass discrimination of marginalised groups, these are REAL existential risks, not this latest PR stunt, my interview https://t.co/3fzHk0pviL @Independent@oiioxford@BKCHarvard
























![leczhang's tweet photo. [1/13] LLMs are increasingly skilled at mimicking human agents in social settings, but have they truly developed a consistent personality? Check out our work accepted to #NAACL2024 where we question the reliability of persona tests applied to LLMs.
Arxiv: https://t.co/GbZrtemmS8 https://t.co/wNOM9ahG88](https://pbs.twimg.com/media/GPaSoUKaEAQ0Fqg.jpg)