Q1 earnings are in: 2026 is off to a terrific start.
Our AI investments and full stack approach are lighting up every part of the business: Search queries are at an all-time high with AI continuing to drive usage. Google Cloud revenue grew 63%, Gemini models have incredible momentum, and it was our strongest quarter ever for consumer AI subs, driven by @GeminiApp.
Thanks to our partners + employees around the world. Much more to share on our earnings call in 20 minutes… and at Google I/O in 20 days!
Our team ran a verifiable quantum algorithm that probes how parts of a quantum system interact, from molecules to magnets and beyond. On our Willow chip, it ran 13,000× faster than the best classical supercomputers. A first in quantum computing → https://t.co/j56g2M7gx0
Available now: Google’s official Agent Skills repository on @github!
Learn how to equip agents with additional, condensed expertise with Agent Skills—and stay tuned for additional skills in this repo in the coming weeks and months → https://t.co/K3CIaC5LTX
It was a huge honour to meet with President @Jaemyung_Lee in Seoul. Deeply appreciate and impressed by our thoughtful exchange about AI safety and the importance of using AI to advance science. Korea has a leading part to play in that, and we look forward to working together!
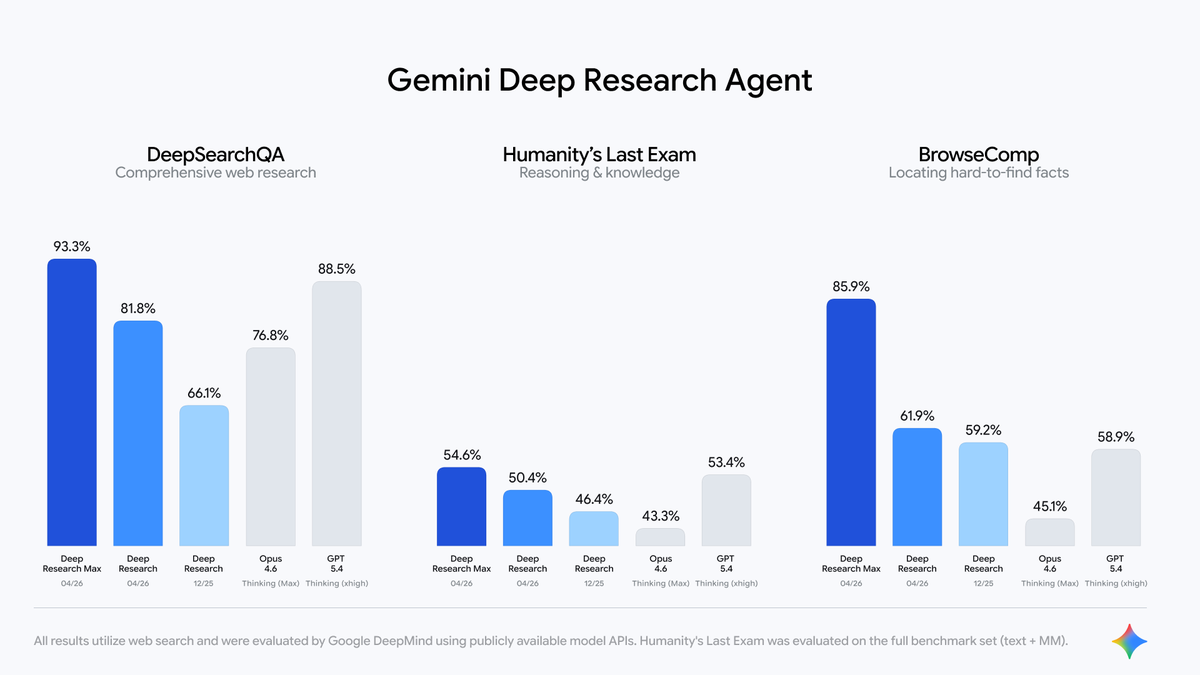
We are launching two powerful updates to Deep Research in the Gemini API, now with better quality, MCP support, and native chart/infographics generation.
Use Deep Research when you want speed and efficiency, and use Max when you want the highest quality context gathering & synthesis using extended test-time compute — achieving 93.3% on DeepSearchQA and 54.6% on HLE.
London, we’re taking the next step! 🚙 We’re officially beginning autonomous driving with a trained specialist behind the wheel. We can’t wait to offer Londoners a quiet, convenient, and magical way to connect to the Tube, bus, or their final destination later this year.
Lyria 3 Pro’s enhanced customization offers more space to experiment and play with longer tracks, so you can now add more details to bring your full vision to life in Gemini.
"Applying AI in the physical world will be transformative".
This collaboration unites GDMs cutting-edge Gemini Robotic AI models into Agile robots scalable industrial robotics platforms.
Lock in.
Google DeepMind 🤝 Agile Robots
Our new research partnership will integrate the Gemini foundation models with their hardware to help build the next generation of more helpful and useful robots.
Find out more → https://t.co/dptWjeZwya
Woah, this is incredible!
TurboQuant is a compression method that achieves a high reduction in model size with zero accuracy loss, making it ideal for supporting both key-value (KV) cache compression and vector search.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Introducing the 𝗚𝗲𝗺𝗶𝗻𝗶 𝗮𝗱𝘃𝗮𝗻𝘁𝗮𝗴𝗲 in Google Marketing Platform. Our best AI for your best ROI
Experience unified inventory, accelerated performance, and ease of use. All in one place.
To all the Firebase developers exploring new AI workflows: welcome! 🤝
Import your Firebase Studio projects into Antigravity to pick up where you left off. You'll have access to Gemini models, Agent Skills, and a built-in Browser Agent.
Antigravity supports core Firebase services including Auth, Firestore, and Hosting via the Firebase MCP server. It also adds new integrations like Google Search and Nano Banana, with the flexibility to run locally or over SSH to a VM.
For a fast model, Gemini 3 Flash offers incredible performance, allowing us to provide frontier intelligence to everyone globally. Try the 'fast' mode from the model picker in the @GeminiApp - it’s shockingly speedy AND smart. Best pound-for-pound model out there ⚡️⚡️⚡️
Our TPUs are headed to space!
Inspired by our history of moonshots, from quantum computing to autonomous driving, Project Suncatcher is exploring how we could one day build scalable ML compute systems in space, harnessing more of the sun’s power (which emits more power than 100 trillion times humanity’s total electricity production).
Like any moonshot, it’s going to require us to solve a lot of complex engineering challenges. Early research shows our Trillium-generation TPUs (our tensor processing units, purpose-built for AI) survived without damage when tested in a particle accelerator to simulate low-earth orbit levels of radiation. However, significant challenges still remain like thermal management and on-orbit system reliability.
More testing and breakthroughs will be needed as we count down to launch two prototype satellites with @planet by early 2027, our next milestone of many. Excited for us to be a part of all the innovation happening in (this) space!
Another great @GoogleDeepMind paper.
Shows how to speed up LLM agents while cutting cost and keeping answers unchanged.
30% lower total cost and 60% less wasted cost at comparable acceleration.
Agents plan step by step, so each call waits for the previous one, which drags latency.
Speculative planning fixes that by having a cheap draft agent guess next steps while a stronger agent checks them in parallel.
Fixed guess lengths backfire, small guesses barely help, big guesses waste tokens when a check disagrees.
Dynamic Speculative Planning learns how far to guess, then stops early to avoid wasted calls.
A tiny online predictor learns how many steps will be right using reinforcement learning.
1 knob lets teams bias for speed or cost, either by skewing training or adding a small offset.
If a guess is wrong, extra threads stop and execution resumes from the verified step.
Across OpenAGI and TravelPlanner, the dynamic policy matches the fastest fixed policy while spending fewer tokens
The result is clear, faster responses, lower bills, and 0 loss in task quality.