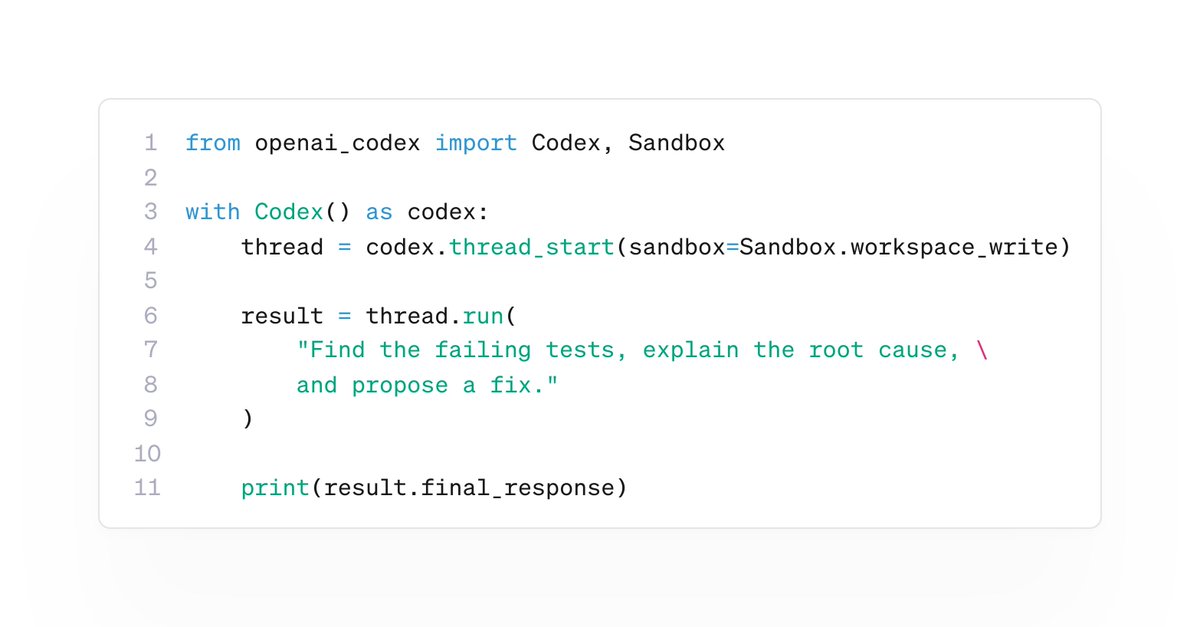
We just released the Codex Python SDK 🔥
You can now embed Codex directly into your Python apps and workflows!
> Start threads
> Run turns
> Stream progress
> Resume sessions
> Pass images
> Control sandbox access
All whilst reusing your existing Codex auth.
pip install openai-codex
Go build with it!!
Tengo 15 años y me he propuesto destruir el monopolio de las calculadoras escolares (TI/Casio).
Hoy @david_bonilla cuenta mi historia en @labonilista frente a 16.000 ingenieros, pero aquí os traigo el detrás de las cámaras de cómo he metido un motor CAS en un chip de 5€.
1/n
Microsoft acaba de desvelar SkillOpt. ¿Qué es?
Agent Skills que evolucionan en tiempo real
Aprenden de los errores, se reescriben solos y acepta cambios si pasan la validación.
Mejora modelos como GPT y Qwen hasta un ~20%.
Después de gastar billones de tokens, creo que ya puedo sacar una conclusión bastante clara:
La gente está optimizando el coste equivocado.
He probado decenas de modelos, editores y agentes:
Codex, Claude Code, Cursor, OpenCode, Codex Cloud, múltiples providers y configuraciones.
Llevo desde gpt-3.5 usando IA para programar.
Al principio como asistente y desde diciembre del año pasado, no escribo código manualmente: programo exclusivamente con IA.
Además lo he hecho en proyectos reales. En productos en producción con millones de usuarios, como Calisteniapp.
Me costó todo este tiempo darme cuenta de qué es lo realmente importante a la hora de elegir modelos y tools.
La mayoría mira únicamente el precio por millón de tokens, o el uso que tiene incluido en la suscripción de turno, y la calidad del resultado.
Tienden a usar el mejor modelo calidad/precio que se pueden permitir.
Pero esta métrica, aislada, no significa nada.
Porque el verdadero coste no son los tokens. Es el efecto compuesto:
- el número de iteraciones,
- el tiempo humano,
- la carga mental,
- la pérdida de flow,
- y el coste de revisar trabajo mediocre.
Con modelos baratos tipo Kimi K2.6, para una misma tarea, normalmente necesito 1 o 2 iteraciones más que con GPT-5.5 o modelos sota.
Sí, el modelo barato cuesta 2-3 veces menos por token.
Pero si necesito:
- más prompts,
- más revisiones,
- más contexto,
- más correcciones,
- y más tiempo pensando…
Entonces el modelo "barato" termina siendo más caro.
Porque no estás pagando solo tokens.
Estás pagando tiempo humano y carga cognitiva.
Y el tiempo humano de un programador senior no vale precisamente poco.
Tomemos un baseline conservador: 40 céntimos por minuto.
Si un modelo mediocre me hace perder 10 minutos extra revisando, iterando o corrigiendo, ya he gastado 4€ invisibles.
Ese es el coste oculto de usar modelos "calidad/precio".
Y esto se vuelve todavía más evidente usando modos xhigh o max. Mucha gente piensa: no compensa, consume demasiados tokens.
En mi experiencia, la mayoría de las veces ocurre exactamente lo contrario.
Los modos de razonamiento profundo suelen ser más baratos en coste total real porque:
- resuelven mejor,
- hacen menos errores,
- necesitan menos iteraciones,
- y llegan mucho más cerca del one-shot.
A veces gastas más tokens. Pero menos tiempo humano. Y eso es lo importante.
Pero hay otro factor más que la gente subestima y que casi nadie mide:
La velocidad de inferencia.
Hay tareas donde no necesitas el modelo más inteligente del planeta.
Por ejemplo:
- commits,
- pushes,
- tareas mecánicas,
- scripting simple,
- operaciones repetitivas.
Pero ahí tampoco compensa necesariamente usar modelos lentos y baratos.
Compensa usar modelos suficientemente inteligentes… pero absurdamente rápidos.
Modelos como GLM 4.7 o GPT OSS 120B en providers optimizados pueden trabajar a cientos o incluso miles de tokens por segundo.
¿Resultado?
Tareas que antes tardaban 2 minutos pasan a tardar 10 segundos.
Y otra vez: el ahorro no está en tokens. Está en no romper el flow.
Dos minutos esperando un commit automático son dos minutos donde tu cerebro sale del contexto.
Son dos minutos de tu tiempo que cuestan mucho más que esos tokens.
Te sugiero cambiar el chip:
- No optimizar €/millón de tokens.
- Sino optimizar coste total cognitivo y operativo.
Si te interesa saber qué modelos y configuraciones uso, en mi perfil tienes un repo abierto con todo.
Si piensas diferente, me gustaría conocer tu opinión.
Agent 365 is now generally available!
We’re extending the systems customers already use for identity, security, governance, and management to every AI agent and their interactions across the enterprise. https://t.co/7skXvhIwYB
🚀 Big news! Agent Evaluation in Microsoft Copilot Studio is now Generally Available 🤖
Built-in, no-code testing at scale — create test sets with AI, evaluate quality/safety/reliability, and get auditable results.
Ensure your agents are production-ready!
#Copilot#Microsoft365
https://t.co/XIgzQWKtvv
🌍 Una comunidad en español para aprender, compartir y crecer en el mundo de los datos e IA.
Súmate a nuestro canal 👉 https://t.co/4NSpQ7nHEi
📊 Power BI | 🤖 IA | 🔗 Fabric
¡Tu próximo proyecto comienza aquí!
#Comunidad#MicrosoftFabric#IA
Echa un vistazo al último artículo de mi newsletter: «Tu plataforma de datos no está preparada para la IA (y no se arregla solo con más datos)» https://t.co/uNkC7MbAha a través de @LinkedIn
El 18/03 estaré en #ASLAN2026 con la sesión “Controlando nuestros datos en la era de los agentes”.
Observabilidad + gobierno + trazabilidad para anticipar incidentes antes de que impacten en negocio.
Después seguimos la conversación en el stand de @WeAreAltia
I just open sourced my #AzurePolicy IaC solution that works on both #AzureDevOps and #GitHubActions. This is something I have spent last 4-5 years perfecting it. I named it #AzPolicyFactory. Read my blog post here: https://t.co/OFfU9pThsQ
No puedo estar más de acuerdo!! Tanto en el fondo,como en la predicción de lo que se avecina «El mundo se divide entre dos tipos de personas: los que venden cosas y los que creen que no lo están haciendo.» Oda a los (buenos) comerciales (vía @bonilista) 💸 https://t.co/J7cqlEVrln