La IA me recuerda constantemente algo interesante:
No se cobra por escribir código. Se cobras por entender problemas. El código era el cuello de botella.
Cada vez lo es menos. Aunque los tokens esten subvencionados
Behind every scalable system is a queue.
Behind every outage is one used wrong.
Queues are everywhere: background jobs, event streams, message brokers.
They’re the backbone of scalable systems, but they’re also a common source of outages.
Core Definitions:
1. Queue: A data structure or system for storing tasks/messages in FIFO order (First-In-First-Out).
2. Producer: Component that sends messages to a queue.
3. Consumer: Component that reads and processes messages from a queue.
4. Broker: Middleware managing queues (e.g., RabbitMQ, Kafka, SQS).
5. Acknowledgement (ACK): Signal that a message was processed successfully.
6. Dead Letter Queue (DLQ): Queue for failed/unprocessable messages.
7. Idempotency: Guarantee that reprocessing a message does not create duplicate side effects.
8. Visibility Timeout: Time during which a message is invisible to others while being processed.
Best Practices / Pitfalls:
- Use idempotent consumers → prevents double processing.
- Define retry policies (exponential backoff, max attempts).
- Monitor queue length & processing lag as health indicators.
- Use dead letter queues for failed messages.
- Ensure message ordering only when business-critical (ordering adds cost/complexity).
- Keep messages small & self-contained.
- Always include correlation IDs for traceability.
Performance Considerations:
For Throughput → Parallel consumers or partitions
For Durability → Persist if critical (trade-off: speed)
For Scalability → Auto-scale consumers
Patterns:
- Work Queue → Spread tasks across workers
- Pub/Sub → Broadcast to many subscribers
- Delayed Queue → Retry later or schedule tasks
- Priority Queue → Handle urgent first
Queues decouple systems, but they don’t manage themselves.
Get them wrong and you get outages.
Get them right and you unlock scalability, resilience, and speed.
AI in SRE is here! Google just open-sourced how they keep 5 billion people online.
This is Google SRE. The team that invented Site Reliability Engineering 20 years ago. Every major tech company copied their model. Now they just published exactly how they are rebuilding it with agentic AI.
Here is what their agents are doing inside Google right now:
→ When something breaks, AI agents pull observability data, run through playbooks and fix the issue autonomously before the on-call engineer even gets paged
→ AI agents monitor every live incident, write postmortems automatically and generate engineer handoff documents without a human touching anything
→ A system called AI Insights continuously reads every past Google incident ever recorded and feeds those lessons to agents so they get smarter after every single outage
→ Anomaly detection agents learn normal behavior patterns instead of using static thresholds and alert only when something actually looks wrong
→ Every agent has its own identity, its own permissions, its own reliability SLO and its own backup plan. Google treats AI agents exactly like human engineers.
They published the full architecture as a free white paper.
If Google is rebuilding a 20 year old discipline from scratch with agentic AI, every engineering team on earth is already behind and most do not know it yet.
Full playbook here:
https://t.co/qNDOaKORYA
HUGGING FACE DROPPED A FREE CONTEXT ENGINEERING COURSE
and the curriculum is stacked:
▫️ unit 1: agent skills + SKILL.md format
▫️ unit 2: MCP (model context protocol)
▫️ unit 3: plugins for tool distribution
▫️ unit 4: subagents + multi-agent workflows
▫️ unit 5: hooks to guard the agent lifecycle
▫️ bonus: build your own agent from scratch
https://t.co/1HjjaXVOek
Hoy he hablado de:
- Docker Sandboxes https://t.co/MXGsxJmT5r
- Docker Agents https://t.co/GpsTstsoW0…
Además de lo bueno que es nuestro agente Gordon. https://t.co/WIGcMM4i6x…
Encantado de resolveros cualquier de vuestras dudas.
#LechazoConf26
In a world where CEOs are pushing token maxxing, I decided to instaurate token fasting.
At least once a week, we code by hand. Just fingers and brain madly dancing together once again. And it rhymes. Not only that, quarantined one of the most delicate organs in the whole beast: Handinger’s harness.
Why?
1. Because humans are tactile animals. This is why we take notes in school and learn to drive in an actual car. I need us to understand the codebase in our bones. The dependencies, the seams, the bugs and dreams. And it rhymes again.
Reviewing generated code gives you the dangerous feeling of understanding. But it is mostly shallow. You nod along, accept the diff, and walk away convinced you know what happened.
2. Humans already have a disease: when solving problems, we add things instead of removing them (there is a famous study about it, go read it!). Clankers do this 100x worse. They feel no pain, so they add forever. Another file. Another method. Another “helper” that, honestly, could have been inlined. A growing pile of computational debris.
In some areas of the product, I don’t mind. CRUDs, APIs, UI. Fine. But a harness is a zero-sum domain. Every new tool, prompt, and abstraction has a cost. It decreases margins and effecteviness while increasing latency. This is why, paradoxically, Claude Code has now turned into a mediocre harness for their own models.
I'm not being anti-AI, but everything interesting in the universe (like life itself) tends to happen in between.
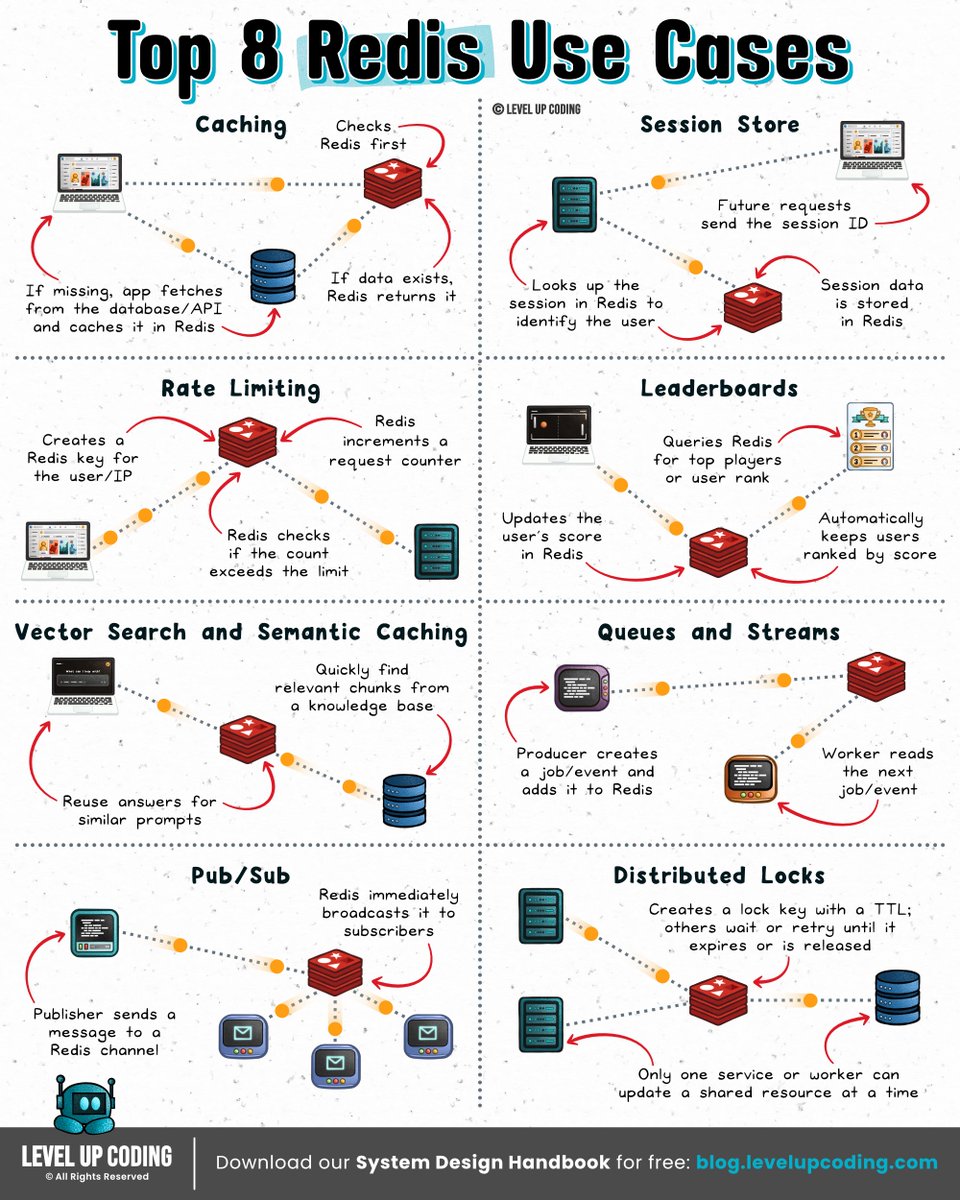
Top 8 Redis Use Cases.
Redis is often introduced as a cache, but real systems use it for much more than speeding up database reads.
That same need for fast, real-time data access is also why Redis is expanding further into AI infrastructure with Redis Iris, a context engine for AI agents that acts as a context and memory retrieval system.
Learn more here → https://t.co/0HHupzAdPS
1) 𝗖𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store hot data close to the application to reduce database load and latency.
2) 𝗦𝗲𝘀𝘀𝗶𝗼𝗻𝘀
↳ Keep per-user or per-agent state in Redis so application servers can remain stateless.
3) 𝗥𝗮𝘁𝗲 𝗹𝗶𝗺𝗶𝘁𝗶𝗻𝗴
↳ Track request counts across distributed services, API calls, tool usage, and model calls.
4) 𝗟𝗲𝗮𝗱𝗲𝗿𝗯𝗼𝗮𝗿𝗱𝘀
↳ Use sorted sets to maintain live rankings without recomputing results.
5) 𝗩𝗲𝗰𝘁𝗼𝗿 𝘀𝗲𝗮𝗿𝗰𝗵 & 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗰𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store embeddings, retrieve semantically similar data, and reuse responses across similar AI queries.
6) 𝗤𝘂𝗲𝘂𝗲𝘀 & 𝗦𝘁𝗿𝗲𝗮𝗺𝘀
↳ Queue work, process events asynchronously, coordinate agent tasks, and track consumer progress.
7) 𝗣𝘂𝗯/𝗦𝘂𝗯
↳ Fan out real-time messages when durability and replay aren’t required.
8) 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗹𝗼𝗰𝗸𝘀
↳ Prevent multiple workers or agents from modifying the same resource at the same time.
Redis has quietly evolved from “just a cache” into infrastructure for real-time coordination, retrieval, streaming, memory, and increasingly AI workloads.
That evolution is reflected in their new context engine launch, focused on delivering live, agent-ready context for AI systems operating across fragmented data sources.
Explore it here → https://t.co/exhl6y42kZ
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @Redisinc for sponsoring this post.
➕ Follow me ( Nikki Siapno ) + turn on notifications.
Oracle has always been a dinosaur, too uptight, and enterprise-focused.
But now they are killing it with AI, and their 26ai version is light-years ahead of anything else.
I spent a day with the @OracleDevs team looking into everything they are shipping. They flew me there (thanks!), but they aren't paying me to say this.
Some of the things that impressed me the most:
1. You can run an LLM and an Embedding model directly from your database. This is huge because you don't need to send your data anywhere else.
2. You can now run hybrid vector searches: semantic and keyword searches directly in the database.
3. There's a new concept called JSON Relational Duality views where you can see your data in both JSON or relational form. It's cool because you can stick to a relational model but take advantage of the flexibility of JSON.
4. They built-in code generation tools you can use to write SQL code on your database.
These are just the ones I remember from the top of my head.
All of these features are in the new version of Oracle.
Cuando programo con IA a menudo me veo indicándole al agente en qué capa de abstracción colocar cada cosa.
Le pido una funcionalidad en un buscador, y me escribe un módulo fabuloso de cientos de líneas, que funciona perfectamente.
Yo lo veo, horrorizado, y le digo:
—Payo, ¡así no! Consulta la documentación de la base de datos y mira si puedes delegarle esa complejidad.
Entonces me responde:
—Tienes razón, ¡buen cambio de rumbo!
Y borra el módulo de cientos de líneas que escribió en el paso anterior.
Ahora, más que nunca, programar es entender qué va en cada capa de abstracción. Delegar todo lo posible en el DOM, en el JavaScript moderno, en la base de datos, en el protocolo… Y luchar contra la complejidad artificial que trata de introducir la IA.
El mérito nuca fue conseguir que funcione.
El mérito es que la complejidad del proyecto crezca linealmente cuando la funcionalidad que proporciona crece exponencialmente.
According to @unclebobmartin, “duplication is the primary enemy of a well-designed system” (Clean Code, 2008). This problem seems to become less important when code management is delegated to AI agents. Updating multiple places in a codebase simultaneously is no longer a difficult task for them. It was for us, but it’s not for them.
Qué bonito y que simple es K3s para clusters de Kubernetes on-premise o homelabs incluso.
Empiezas con un solo máster con SQLite. Creces tranquilo hasta que quieres hacer algún trabajo que necesite HA
Y de un solo camandazo pasas de SQLite a etcd replicado puedes meter los másters que te dé la gana (mínimo 3 por quórum)
Recuerdo cuando me tocó administrar el primer cluster de K8s onpremise hace 7/8 años creo y tocó hacer este mismo proceso… menudo dolor, muerte y destrucción había que hacer ahí 😂
I strongly believe there are entire companies right now under heavy AI psychosis and its impossible to have rational conversations about it with them. I can't name any specific people because they include personal friends I deeply respect, but I worry about how this plays out.
I lived through the great MTBF vs MTTR (mean-time-between-failure vs. mean-time-to-recovery) reckoning of infrastructure during the transition to cloud and cloud automation. All those arguments are rearing their ugly heads again but now its... the whole software development industry (maybe the whole world, really).
It's frightening, because the psychosis folks operate under an almost absolute "MTTR is all you need" mentality: "its fine to ship bugs because the agents will fix them so quickly and at a scale humans can't do!" We learned in infrastructure that MTTR is great but you can't yeet resilient systems entirely.
The main issue is I don't even know how to bring this up to people I know personally, because bringing this topic up leads to immediately dismissals like "no no, it has full test coverage" or "bug reports are going down" or something, which just don't paint the whole picture.
We already learned this lesson once in infrastructure: you can automate yourself into a very resilient catastrophe machine. Systems can appear healthy by local metrics while globally becoming incomprehensible. Bug reports can go down while latent risk explodes. Test coverage can rise while semantic understanding falls. Changes happens so fast that nobody notices the underlying architecture decaying.
I worry.
Con financiación y un equipo atacaría sistemáticamente todos los campos de conocimiento y sacaría un producto/proceso por semana ad eternum, el 20% de ellos darían dinero.
Antes de la IA, tenías una idea y sabías que el cuello de botella era la ejecución.
Hoy en día, esa ejecución la realizan agentes programables: 'Programar' una empresa/equipo con un cometido puede ser cuestión de horas, por eso es tan divertido.
Las ideas llevan la batuta ahora. La agencia nace de las mismas.
Mi libro Menos software, más impacto está cerca. Junio 2026 en español, poco después en inglés.
He preparado una web con recursos por capítulos (https://t.co/LwaEyfU1TR) y un Substack específico para el lanzamiento, con cadencia muy baja: https://t.co/hEO4JLLSC2
Modernizing legacy #Java feels like opening a closet you've been avoiding for years 🧹
We just dropped a 9-part series on doing it for real with #GitHub Copilot - assessment, upgrades, databases, containerization, and full portfolio scaling.
Watch: https://t.co/UfBxaCOIuV