My typical day as a Member of Technical Staff at OpenAI:
[9:00am] Wake up
[9:30am] Commute to Mission SF via Waymo. Grab avocado toast from Tartine
[9:45 am] Recite OpenAI charter. Pray to optimization Gods. Learn the Bitter Lesson
[10:00am] Meetings (Google Meet). Discuss how to train larger models on more data
[11:00am] Write code to train larger models on more data. pair=@hwchung27
[12:00pm] Lunch at the canteen (vegan, gluten-free)
[1:00pm] Actually train large models models on more data
[2:00pm] Debug infra issues (why the fck did I pull from master?)
[3:00pm] Babysit model training. Play with Sora
[4:00pm] Prompt engineer aforementioned large models trained on more data
[4:30pm] Short break, sit on avocado chair. Wonder how good Gemini Ultra actually is
[5:00pm] Brainstorm potential algorithmic improvements for models
[5:05pm] Conclude that algorithmic changes are too risky. Safer to just scale compute and data
[6:00pm] Dinner. Clam chowder with Roon
[7:00pm] Commute back home
[8:00pm] Have a wine and get back to coding. Ballmer’s peak is coming
[9:00pm] Analyze experimental runs. I have a love/hate relationship with wandb
[10:00pm] Launch experiments to run overnight and get results by tomorrow morning
[1:00am] Experiments actually get launched
[1:15am] Bedtime. Satya and Jensen watch from above. Compression is all you need. Good night
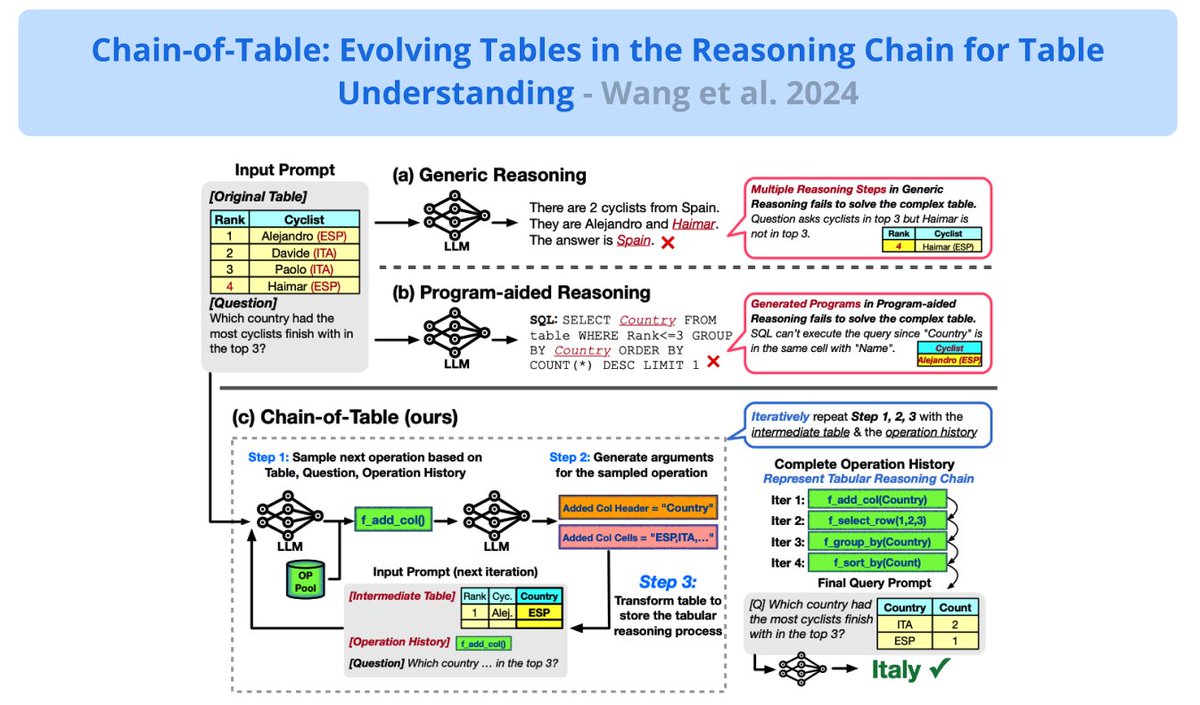
Chain-of-Table ⛓️📊: use LLMs to understand tabular data step-by-step
Even the best LLMs have a hard time understanding tabular data:
🚫 Dumping the table in the prompt doesn’t work given attention limits
🚫 Text-to-SQL is flaky / inflexible.
That’s when we discovered the chain-of-table framework, proposed by @zlwang_cs 💡- form a chain of tables through step-by-step reasoning + planning with a limited set of tabular operations.
Do any of the following operations in sequence: adding a column, selecting a row, groupby, sorting, etc. It’s similar to how a data scientist would transform the table into a concise/readable representation.
We were excited to implement this as a LlamaPack in @llama_index! 🦙📦
LlamaPack: https://t.co/kqPgCAv44R
Notebook: https://t.co/13zlcf4n73
ArXiv: https://t.co/sHhiXnL4nx
Sparrow is a neat tool to extract JSON data from any scanned documents/images, using LLMs + other AI models.
Super useful for a lot of enterprise data use cases - forms, invoices, receipts, and more 📑
Check out @andrejusb's fantastic video tutorial on how to use @OLLAMA + @llama_index + Sparrow to process invoices, and have it run all on your laptop!
Sparrow repo: https://t.co/dGrsk05S9Y
Video: https://t.co/bYnaPhAcmY
Wrote a post walking you through building a super minimal in-memory storage engine for MySQL/MariaDB in 218 lines of C++.
And took time again to reflect on the limitations of custom storage engines and how MySQL compares to Postgres internally here.
https://t.co/nImUC36DPs
Prompting LLMs for Table Understanding
A new framework to improve understanding of tabular information with LLMs.
Inspired by Chain-of-Thought prompting, it instructs LLMs to dynamically plan a chain of operations that transforms a complex table to reliably answer the input question.
An LLM is used to iteratively generate operations, step-by-step, that will perform necessary transformations to the table (e.g., adding columns or deleting info).
Looks like a nice approach to improve the reasoning, accuracy, and reliability of LLMs when dealing with more structured information like tables. Looks very promising.
I wonder how this would look for graph structures? Or there is probably a paper out that I missed.
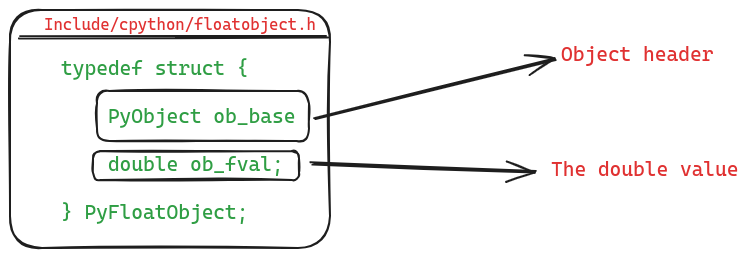
First article is out. It covers the internals of object system in CPython. Usually objects are implemented using interfaces and polymorphism, but C does not have those. CPython uses a little trick to achieve this, which involves the PyObject struct.
The PyObject struct is defined in the file Include/object.h, and it is also referred to as the object header. The following image shows how it looks like.
The trick for emulating inheritance and polymorphism is simple. The struct definition for every object in CPython needs to include PyObject as its first field. For instance following figure shows the definition of the float type.
What does this achieve? By embedding PyObject as the first field in every object's definition, CPython ensures that all these objects have a uniform beginning in the memory which is formed by the PyObject struct. This is why PyObject is also called the object header. The following image shows how objects look like in memory.
Now, emulating inheritance simply requires us to switch the interpretation of these bytes in memory from the child type to the parent type, i.e., PyObject.
What about polymorphism? The PyObject struct includes a field called ob_type. It points to a structure of type PyTypeObject. This is a very large structure and stores all the type related information about the object, which includes type name, size etc.
PyTypeObject also includes a table of function pointers which define the behavior of the type. For instance, functions for add, subtract, multiply, divide, repr, len etc. This is also called the method table. Each object type implements these functions and populates this table.
During execution of instructions, the CPython VM is always working with objects of type `PyObject *` and it delegates the execution of any type specific to the concrete implementation within the types via the method table without every knowing about the concrete type of the object.
This is just an overview, the article goes in much more depth and shows how all of this plays out by showing code from the CPython VM. Check it out and subscribe: https://t.co/9SnepbQAsA
#Surge08's @sachinjain024@RequestlyIO documented his entire Surge experience 🙌
If you're a founder thinking of applying, you can read details about the program, community & more - all from a founders pov. 👇
https://t.co/c4EfBjWNAG
Applications for #Surge09 close Sept 15
Today I had the pleasure of hosting @lexfridman at #sapienship HQ, for an extensive conversation on a wide range of big topics. Stay tuned for his podcast episode very soon.
#longformcontent
Gen Bipin Rawat was an outstanding soldier. A true patriot, he greatly contributed to modernising our armed forces and security apparatus. His insights and perspectives on strategic matters were exceptional. His passing away has saddened me deeply. Om Shanti.
We have sourced supplies for Oxygen concentrators of different sizes while we place the order using our own money. We want you to join hands in solving #OxygenShortage .
Donate here https://t.co/YlBF6S4c2p and we will match your contribution and use it to source OCs.
Also, do RT
The COVID resurge is wreaking havoc across India. With > 300,000 cases/day, 2000 deaths/day, and a struggling health infrastructure, India needs immediate help. Please join me in raising money for Sewa International. Sachin and I will match up to $50,000
https://t.co/KFveJ9xSWQ
With 450+ million users performing half a billion actions across our apps daily, you're probably wondering how we consume this #data in a scalable manner that allows us to give users relevant information in near real-time.
Follow us to find out! 👀 #BigData#MachineLearning