We ran WarpSpeed, our autonomous optimization agent, on @NVIDIA's new SOL-ExecBench for a single day.
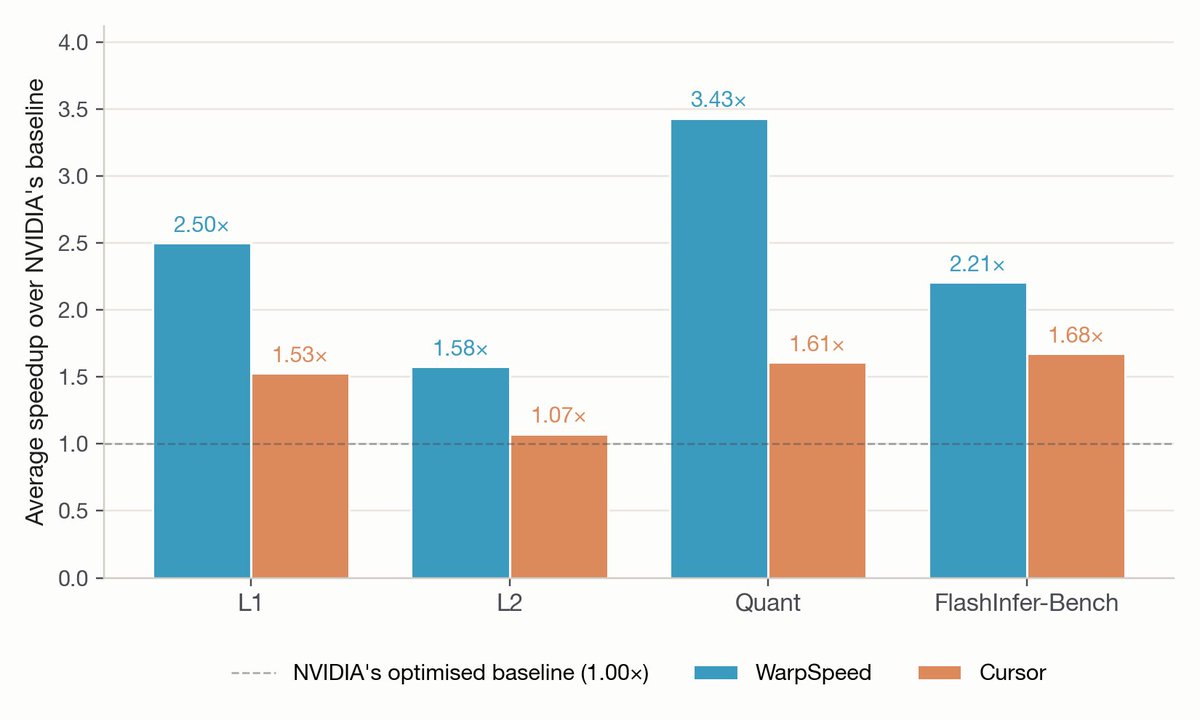
It took first place by a wide margin, beating the optimized kernels on 90% of problems, with an average speedup of 2.24x.
ExecBench gathers 235 of the hardest CUDA kernels in production today, lifted from real workloads in DeepSeek, Qwen, Gemma and Kimi.
Blackwell kernels are notoriously hard to write. But we find that verification is just as hard.
We have a story to tell.
https://t.co/aQX9XXCz4z
DoubleAI’s AI system just beat a decade of expert GPU engineering
WarpSpeed just beat a decade of expert-engineered GPU kernels — every single one of them.
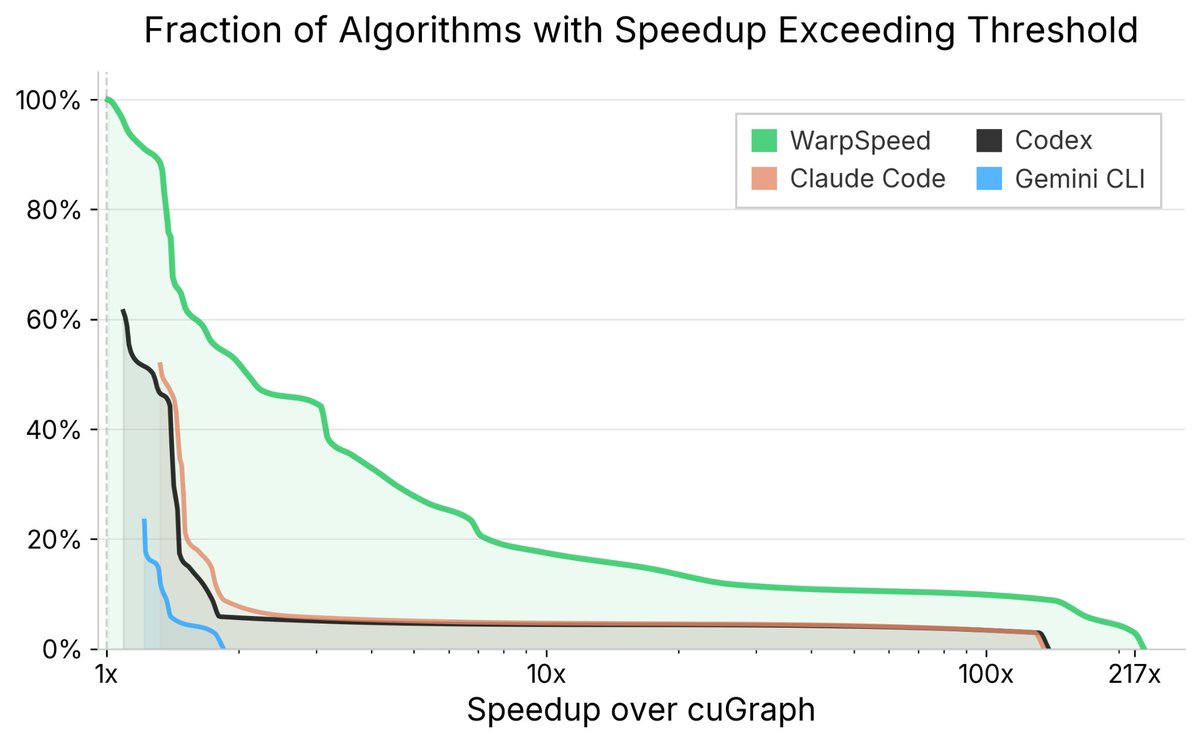
cuGraph is one of the most widely used GPU-accelerated libraries in the world. It spans dozens of graph algorithms, each written and continuously refined by some of the world’s top performance engineers.
@_doubleAI_'s WarpSpeed autonomously rewrote and re-optimized these kernels across three GPU architectures (A100, L4, A10G). Today, we released the hyper-optimized version on GitHub — install it with no change to your code.
The numbers: - 3.6x average speedup over human experts - 100% of kernels benefit from speedup - 55% see more than 2x improvement.
But hasn’t AI already achieved expert-level status — winning gold medals at IMO, outperforming top programmers on CodeForces? Not quite. Those wins share three hidden crutches: abundant training data, trivial validation, and short reasoning chains. Where all three hold, today’s AI shines. Remove any one of them and it falls apart (as Shai Shalev Shwartz wrote in his post).
GPU performance engineering breaks all three. Data is scarce. Correctness is hard to validate. And performance comes from a long chain of interacting choices — memory layout, warp behavior, caching, scheduling, graph structure. Even state-of-the-art agents like Claude Code, Codex, and Gemini CLI fail dramatically here, often producing incorrect implementations even when handed cuGraph’s own test suite.
Scaling alone can’t break this barrier. It took new algorithmic ideas — our Diligent framework for learning from extremely small datasets, our PAC-reasoning methodology for verification when ground truth isn’t available, and novel agentic search structures for navigating deep decision chains.
This is the beginning of Artificial Expert Intelligence (AEI) — not AGI, but something the world needs more: systems that reliably surpass human experts in the domains where expertise is rarest, slowest, and most valuable.
If AI can surpass the world’s best GPU engineers, which domain falls next?
For the full blog: https://t.co/sCF033hb28
CuGraph:
https://t.co/jqxrcuhfs4
Winning Gold at IMO 2025:
https://t.co/fAdIT2mTkI
Codeforces benchmarks:
https://t.co/UhRAUieWFi
@shai_s_shwartz post:
https://t.co/1WAGIXfiqh
From Reasoning to Super-Intelligence: A Search-Theoretic Perspective
https://t.co/iX625p57NT
Artificial Expert Intelligence through PAC-reasoning
https://t.co/Hq3wWsmidw
1/ Software was eating the world - and now AI is eating software.
AI already beats humans at math/coding (IMO, CodeForces). Right?
So let's test the strongest coding agents on a real domain: optimizing cuGraph (GPU graph analytics kernels).
Spoiler:
* The strongest coding agents crash.
* And @_doubleAI_ built WarpSpeed - an AI that beat a decade of expert-engineered GPU kernels.
🧵
I respect that @iclr_conf had to respond to the OR leak, but I disagree with resetting scores. Many students worked hard on rebuttals and improved their papers in good faith. I hope the organizers reconsider and revert the reset. If you agree, feel free to retweet.
🚀 High-quality inversion of text-to-image models in real time! Now you can do interactive image editing! 🎨
📄 Paper: https://t.co/iGh4ZCywGb
🌐 Project Page & Demo: https://t.co/sWOEE8eTVB
Our new work won best paper at the ICML HiLD workshop!
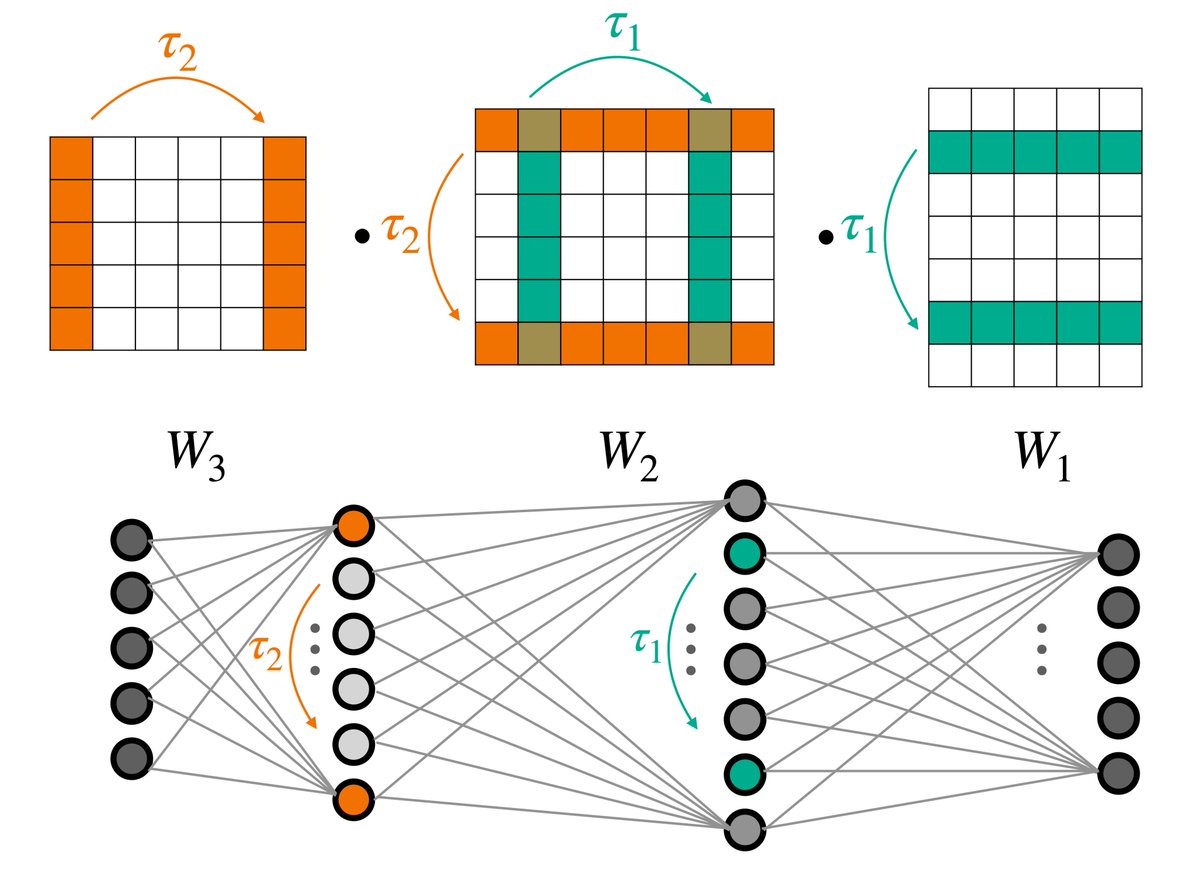
more details to come, but briefly, this work on parameter symmetries touches on many cool directions in understanding neural network loss landscapes and optimization!
@HaggaiMaron talking about equivariance in NN weight spaces. At this pace, we will not be training NNs anymore but running an equivariant generative model on the weights
A new blog post about our Deep Weight Space Networks! A must read if you want to learn how to apply neural networks to (weights of) other neural networks in a principled way.
https://t.co/XwPnCbQhJv
Point-Cloud Completion with Pretrained Text-to-image Diffusion Models
paper page: https://t.co/AVwq8BQssZ
Point-cloud data collected in real-world applications are often incomplete. Data is typically missing due to objects being observed from partial viewpoints, which only capture a specific perspective or angle. Additionally, data can be incomplete due to occlusion and low-resolution sampling. Existing completion approaches rely on datasets of predefined objects to guide the completion of noisy and incomplete, point clouds. However, these approaches perform poorly when tested on Out-Of-Distribution (OOD) objects, that are poorly represented in the training dataset. Here we leverage recent advances in text-guided image generation, which lead to major breakthroughs in text-guided shape generation. We describe an approach called SDS-Complete that uses a pre-trained text-to-image diffusion model and leverages the text semantics of a given incomplete point cloud of an object, to obtain a complete surface representation. SDS-Complete can complete a variety of objects using test-time optimization without expensive collection of 3D information. We evaluate SDS Complete on incomplete scanned objects, captured by real-world depth sensors and LiDAR scanners. We find that it effectively reconstructs objects that are absent from common datasets, reducing Chamfer loss by 50% on average compared with current methods.
Our next Community Spotlight focuses on DWSNets, a public repo demonstrating a novel network architecture for learning in deep weight spaces.
Congrats to the authors of DWSNets for recently being accepted at @icmlconf 🎉 👏
🔗 https://t.co/v9OVbdPWOm
"Improving MTL optimization algorithms is, therefore, an important task with significant implications for many systems."
Find out how Nash-MTL achieves state-of-the-art results on various benchmarks across multiple domains. 🎲
https://t.co/dGIVFbioC3
@SebastianCygert@HaggaiMaron We provide additional details in Appendix J of the paper.
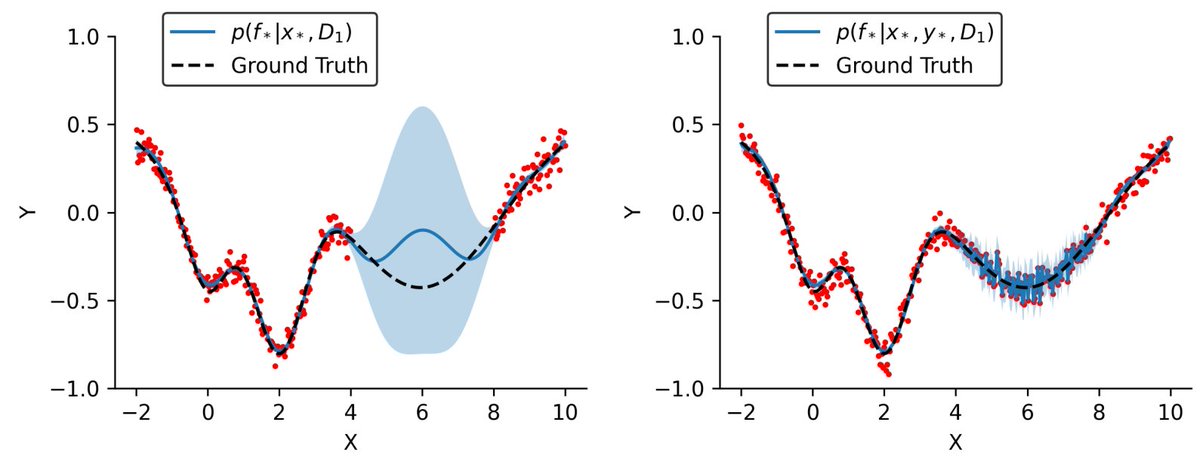
We use 4000 training examples. The DWSNet gets v as its input and outputs Δv. The loss is then computed using target the domain images and the net v-Δv.
(1/10) New paper! A deep architecture for processing (weights of) other neural networks while preserving equivariance to their permutation symmetries. Learning in deep weight spaces has a wide potential: from NeRFs to INRs; from adaptation to pruning https://t.co/7ELrkEIo4G 👇
Our approach named Nash-MTL outperforms multiple MTL baselined on various domains.
This is a joint work with @avivnav@idanachituve@HaggaiMaron@GalChechik@EthanFetaya Kenji Kawaguchi.
Paper: https://t.co/I6Icv8sufX
Project Page: https://t.co/6e6HCDQDMc
#ICML2022
Interested in Multi-task learning?
Check out our paper "Multi-task Learning as a Bargaining Game" from ICML 2022.
We proposed a principled approach for combining tasks' gradients incorporating ideas from game theory.