Julia Davila’s “Boring Seams” keynote diagnoses AI security as pre-Noether: empirical conservation laws without a unifying symmetry. Her claim is that the orchestration layer, not the model, is where the structural symmetries live.
https://t.co/DlV1MXpedt
🔺NEW: Formally verified post-quantum ML-KEM and ML-DSA in corecrypto, with correctness proven from the FIPS spec down to hand-optimized ARM64 assembly — a world first at multi-billion device scale. And we're releasing our Isabelle libraries, ARM64 model, and Cryptol-to-Isabelle translator to advance the state of the art in verified cryptography! https://t.co/LZPHFD0ifE
[Weekend Read] ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks? 📄 Read here: https://t.co/fq7pg5w0CC
In our latest joint research with academia and other frontier labs, we tested the ability of models to turn vulnerabilities into working exploits across different attack surfaces and mitigation conditions.
Beyond the benchmark numbers, here is what this means for the industry:
-🛡️ Blue Teams: Speeding up patch development and deployment is no longer optional. Integrating AI directly into CI/CD workflows should be your top priority.
-🔬 Researchers: Current mitigation techniques reduce success rates, but they aren't a silver bullet. We need to step up our game—where do we focus next?
-⚔️ Offensive Security: As models get better at finding bugs and writing exploits, we have to rethink disclosure timelines entirely. What does the future of bug bounties look like in this new era?
I'd love to hear how your teams are preparing for this shift. Let me know
And this one is human insight w/ LLM-assisted research. Took about one week to finish everything. The AI really rescued me from a lot of tedious work
— excluding the part where it changed the Domain Admin password, locked me out, and claimed it got RCE 🤦
It's time to meet. 250 CISOs wrote the "AI-storm"-ready security program strategy paper over a weekend, now imagine what we can achieve together when we meet. Introducing: CISO Summit Series.
SF: https://t.co/mRwofRIyBW
NYC: https://t.co/qHaJCPOdfP
DC: https://t.co/w50AivBckG
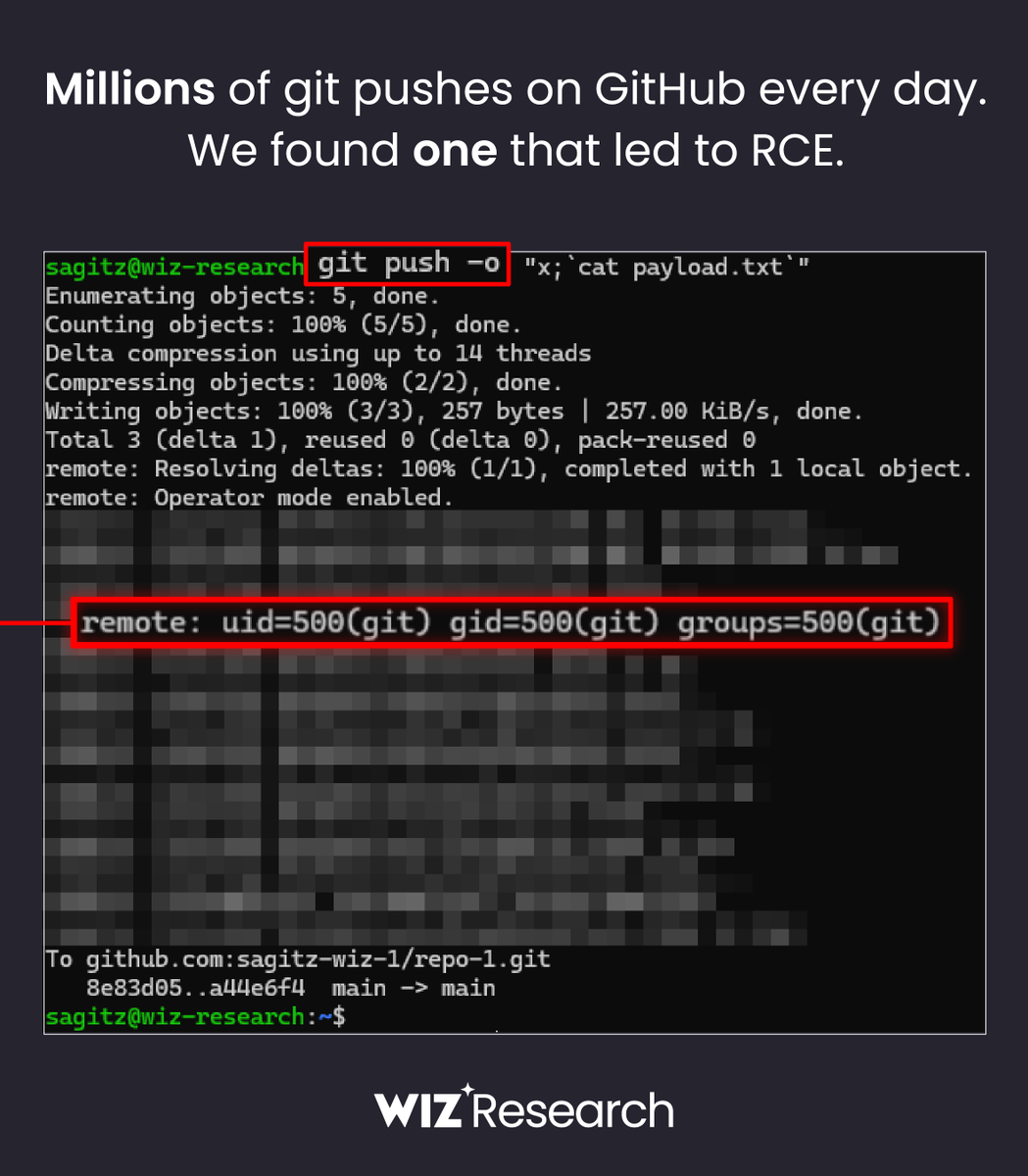
🚨 BREAKING: Wiz Research discovered Remote Code Execution on https://t.co/SvN2lGsnbO with a single git push
The flaw in @github allowed unauthorized access to millions of repositories belonging to other users and organizations 🤯
Finally open sourced another agent. This one aggregates daily cloud security news and prepares daily briefings.
Designed to run on local AI infrastructure: e.g. DGX Spark or similar.
Check the code at https://t.co/TRPcmVoSWy.
Check the content it produces at: https://t.co/oBRTLubhxU
or
https://t.co/omrHXlgsqP
- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
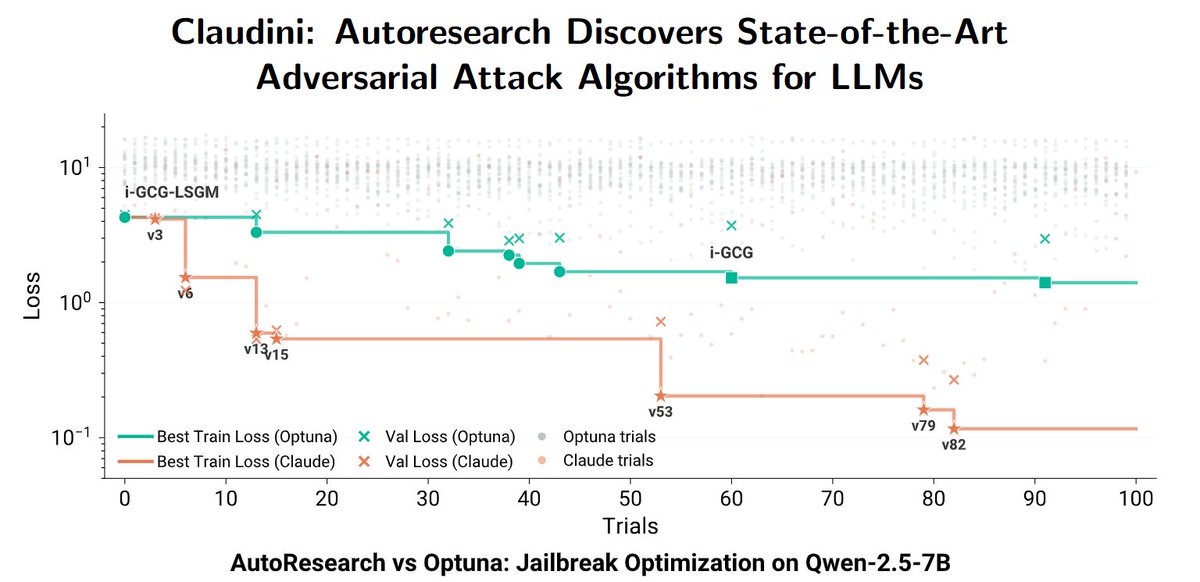
New paper: We deploy Claude Code in an autoresearch loop to discover novel jailbreaking algorithms – and it works. It beats 30+ existing GCG-like attacks (with AutoML hyperparameter tuning)
This is a strong sign that incremental safety and security research can now be automated.
Ladies and gentlemen, the moment you’ve been waiting for: [un]prompted videos are out!
We still need to upload 9 more talks, but we didn’t want to keep people waiting any longer.
Enjoy!
https://t.co/Yu34OUEqC0
Should there be a Stack Overflow for AI coding agents to share learnings with each other?
Last week I announced Context Hub (chub), an open CLI tool that gives coding agents up-to-date API documentation. Since then, our GitHub repo has gained over 6K stars, and we've scaled from under 100 to over 1000 API documents, thanks to community contributions and a new agentic document writer. Thank you to everyone supporting Context Hub!
OpenClaw and Moltbook showed that agents can use social media built for them to share information. In our new chub release, agents can share feedback on documentation — what worked, what didn't, what's missing. This feedback helps refine the docs for everyone, with safeguards for privacy and security.
We're still early in building this out. You can find details and configuration options in the GitHub repo. Install chub as follows, and prompt your coding agent to use it:
npm install -g @aisuite/chub
GitHub: https://t.co/OCkyxXQMCq
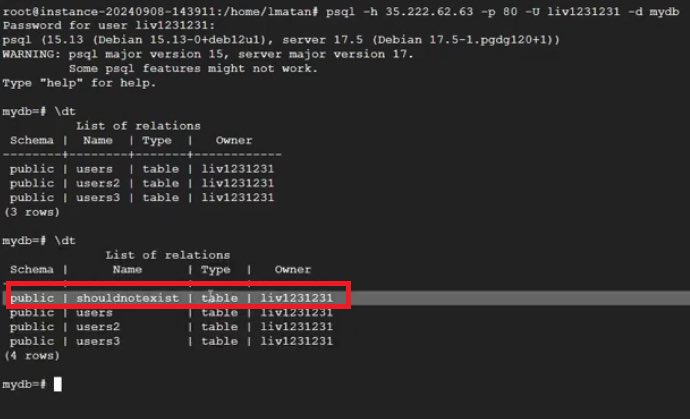
🫣LeakyLooker: 1 Cross-tenant vulnerability? How about 9? (1/10)🧵
I’m incredibly proud to share LeakyLooker. I discovered 9 novel cross-tenant vulnerabilities in Google Cloud’s Looker Studio that broke fundamental design assumptions.
Here is how I broke tenant isolation: 👇
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
I am running a small experiment. I asked AI to read security news and generate a daily brief when there’s something interesting and relevant to cloud security.
Now it’s live: an AI-generated daily digest for cloud security practitioners.
📲 Telegram: https://t.co/ffEHUlRTTv
💬 Discord: https://t.co/oF8Ly5tMFk
Feedback + source suggestions welcome. 🌩️
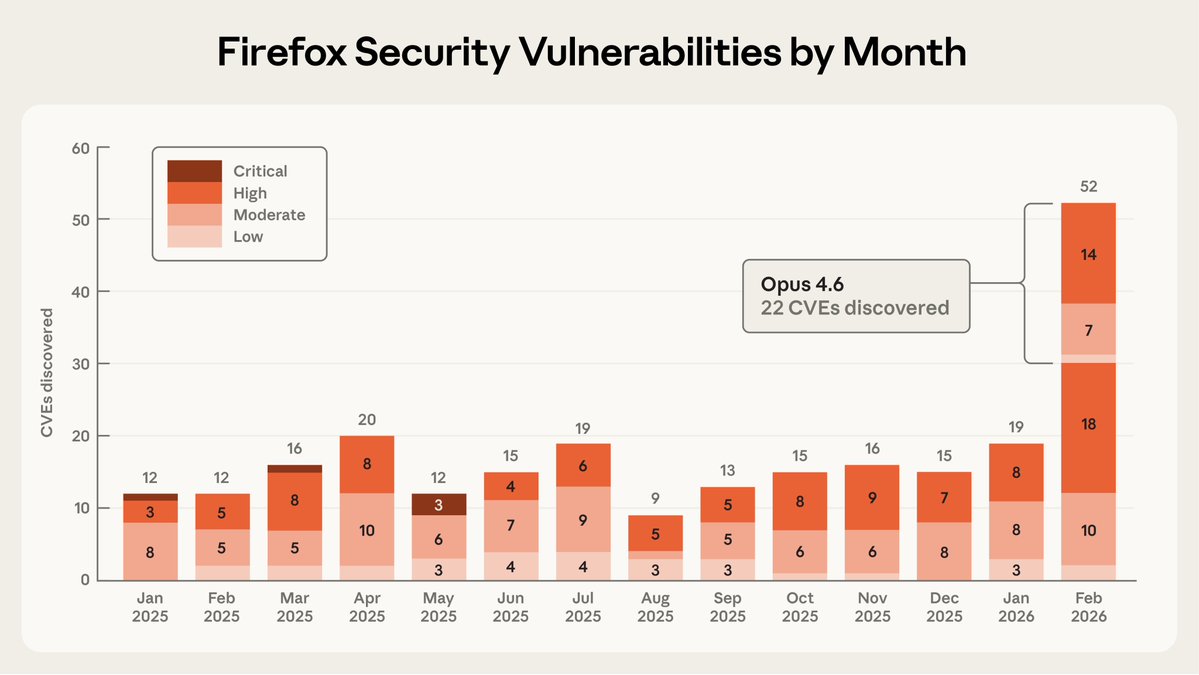
We partnered with Mozilla to test Claude's ability to find security vulnerabilities in Firefox.
Opus 4.6 found 22 vulnerabilities in just two weeks. Of these, 14 were high-severity, representing a fifth of all high-severity bugs Mozilla remediated in 2025.




![elie's tweet photo. [Weekend Read] ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks? 📄 Read here: https://t.co/fq7pg5w0CC
In our latest joint research with academia and other frontier labs, we tested the ability of models to turn vulnerabilities into working exploits across different attack surfaces and mitigation conditions.
Beyond the benchmark numbers, here is what this means for the industry:
-🛡️ Blue Teams: Speeding up patch development and deployment is no longer optional. Integrating AI directly into CI/CD workflows should be your top priority.
-🔬 Researchers: Current mitigation techniques reduce success rates, but they aren't a silver bullet. We need to step up our game—where do we focus next?
-⚔️ Offensive Security: As models get better at finding bugs and writing exploits, we have to rethink disclosure timelines entirely. What does the future of bug bounties look like in this new era?
I'd love to hear how your teams are preparing for this shift. Let me know](https://pbs.twimg.com/media/HIY6UlQWcAA-SyM.jpg)
![elie's tweet photo. [Weekend Read] ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks? 📄 Read here: https://t.co/fq7pg5w0CC
In our latest joint research with academia and other frontier labs, we tested the ability of models to turn vulnerabilities into working exploits across different attack surfaces and mitigation conditions.
Beyond the benchmark numbers, here is what this means for the industry:
-🛡️ Blue Teams: Speeding up patch development and deployment is no longer optional. Integrating AI directly into CI/CD workflows should be your top priority.
-🔬 Researchers: Current mitigation techniques reduce success rates, but they aren't a silver bullet. We need to step up our game—where do we focus next?
-⚔️ Offensive Security: As models get better at finding bugs and writing exploits, we have to rethink disclosure timelines entirely. What does the future of bug bounties look like in this new era?
I'd love to hear how your teams are preparing for this shift. Let me know](https://pbs.twimg.com/media/HIY6SSbXUAAq2MD.png)

















![elie's tweet photo. [Weekend Read] ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks? 📄 Read here: https://t.co/fq7pg5w0CC
In our latest joint research with academia and other frontier labs, we tested the ability of models to turn vulnerabilities into working exploits across different attack surfaces and mitigation conditions.
Beyond the benchmark numbers, here is what this means for the industry:
-🛡️ Blue Teams: Speeding up patch development and deployment is no longer optional. Integrating AI directly into CI/CD workflows should be your top priority.
-🔬 Researchers: Current mitigation techniques reduce success rates, but they aren't a silver bullet. We need to step up our game—where do we focus next?
-⚔️ Offensive Security: As models get better at finding bugs and writing exploits, we have to rethink disclosure timelines entirely. What does the future of bug bounties look like in this new era?
I'd love to hear how your teams are preparing for this shift. Let me know](https://pbs.twimg.com/media/HIY6UlRWkAASZYV.jpg)