THE AI APP STORE SLOP: IT’S OVER.
I know some insiders that work at the Apple App Store and some that work at the Android App Store and there is an issue:
An explosion of vibe coded apps, 100s of 1000s that have framed our executives.
As you know app downloads have dropped to nearly zero.
Well now the quality of these “I’ll flood every category with vibe codes apps” business models has made this impossible for the stores.
Some folks are training as a get-rich quick business to make as many apps as you can and flood the stores. It will only take 100 sending an app every few days to dilute the value of any discovery system at any App Store.
I had one person say that the company feels they can not recover from this and will get worse.
Good apps are not surfacing as the filtering systems get clogged. Veteran app developers are quitting the business and all the money, long ago dried up.
This is the end of the App and the end of an era.
Slopped out of existence.
어쩌면 AGI 시대엔 인공지능이 풀어야 할 문제를 다 정의하고 모든 것을 다 해결해 줄 수 있을지도 모르지만 도대체 이런 식의 냉소가 무슨 도움이 되는 것인지 모르겠다. 더군다나 아직 문제 해결 능력, 사고 능력이 중요 시 여겨지는 현 시점에 PS가 필요없다라고 하는 건 도저히 이해가 되질 않는다
백준 서비스 종료한다는 이야기와 함께 이런 부류의 사람들이 많이 보이더라. "어차피 AI가 다해주는데 알고리즘 공부가 왜 필요하냐. 그렇게 망하게 될 줄 알았다." 본질은 PS, 알고리즘 너머로 문제를 정의하고 Problem Solving에 대한 사고를 키우는 것 일텐데
애초에 낭만 하나로 로켓에 입문하니 웬만하면 불가능으로 보이는 것에 도전하는 머스크를 다들 응원함. 그리고 저게 잘 돼야 우리가 부스러기라도 받아 먹을 수 있지 않겠나 그런 생각도 있었고.. 근데 반도체나 배터리는 워낙 기술적인 표준이 정해져있고 플레이어들이 많으니..저런 반응이 당연한듯
전문가가 없고 무관심했던게 아님. 항공우주공학 하던 사람들은 그냥 모두 일론 머스크를 응원했음. 로켓 공학은 반도체나 배터리 같이 생산성을 내고 이익을 얻기 위한 기술이 아님. 최근에야 위성 사업이니 방산이니 하면서 슬금슬금 주목을 받은거지 예전에는 거의 낭만 하나로 하던 분야였음.
Starship이 한국에서는 굉장히...무관심했지만
미국 NSF 커���니티
Raddit 쪽에서는 몇년 전부터 굉장히 핫한 주제였음.
사실 의회에서는 청문회까지 열릴 정도.
(아직까지도 일부는 부정적이지만)
2016년 ITS(Starship 초기 프로토타입)가 나오고
2018년 BFR (Big Falcon Rocket)으로 개명될 때
거의 SpaceX는 스캠 기업으로 조롱당함...
이미 SLS 로 초대형 발사체를 레거시 기업에서 한창 제작하고 있는 중이었기에
사실, 일론의 초대형 발사체의 완전 재사용은 기존 전문가 집단이 보기에 완전한 거짓말.
거의 대부분 록히드, 보잉 쪽 주주들은 Mk1 보고 엄청 회의적인 시선이 강했음.
미국은 우주 항공 쪽에서 세계 최고 수준의 전문가 집단이 존재하는 곳.
모든 우주 항공의 레퍼런스는 '미국'이 표준임.
그냥 표준임.
동시에 '관성' 또한 엄청나게 강력함.
Starship이 상용화 직전이지만, 아직까지도 SLS 프로젝트가 강력한 지지를 받으면서 진행되고 있는걸보면
우주 항공 분야에서 '관성'이라는 게 얼마나 강력한지 이해할 수 있음.
일론이 대단한 점은
자신의 비전을 위해서 전문적인 지식을 현명하게 활용하는 것에 있음.
대부분 전문가들과 레거시 기업은 지식에 제품을 맞춤.
하지만 일론은 제품을 위해 지식을 만듬.
조지 부시도 이라크 전쟁을 시작한 후 미국이 승리했다며 전쟁은 끝났다고 선언하고 임무 완수 세레모니를 했었다. 물론 전쟁은 세레모니 이후로 8년을 더했다. 그 때가 2003년이고 조지 부시는 2004년 재선을 노리고 있었다. 이라크 전쟁을 맹비난한 트럼프가 비슷한 행동을 하고 있는게 참 아이러니.
속보⚡️: 트럼프 대통령, "이란 전쟁 우리가 승리했다" 선언
도널드 트럼프 미국 대통령이 이란과의 전쟁(작전명: 에픽 퓨리)에 대해 사실상의 승리를 선언함.
켄터키주 헤브론의 버스트 로지스틱스(Verst Logistics) 물류 센터에서 열린 유세 현장에서 "우리가 승리했다(We won). 첫 한 시간 만에 모든 상황이 끝났다"고 주장함.
트럼프 대통령은 "우리는 이란 위를 자유롭게 날아다니고 있다" 며 "호르무즈 해협은 아주 좋은 상태(in great shape)"라고 했음.
이렇게 그냥 종전선언 하려나? 람푸형 빨리 좀 끝내줘....
“GPU를 더 추가한다고 해서 기계가 의식을 가지게 되지는 않습니다.”
노벨상 수상 물리학자 로저 펜로즈(Roger Penrose)가 AI 업계 전체의 핵심 가정을 완전히 무너뜨렸습니다.
지금 AI 산업은 단 하나의 믿음으로 움직이고 있어요.
▶ 거대한 데이터센터를 짓고
▶ 모델을 계속 키우면
▶ AGI가 그냥 “깨어날” 거라는 믿음이죠.
펜로즈는 이걸 정면으로 부정합니다.
- 펜로즈:“컴퓨터를 충분히 복잡하게 만들면 갑자기 의식이 생긴다는 그런 관점이 있습니다. 저는 그저 믿지 않습니다. 믿을 이유가 전혀 없어요.”
기계는 살아있는 어떤 인간보다 계산을 더 잘할 수 있습니다. 하지만 계산 = 인식(awareness)이 아닙니다.
- 펜로즈:“사물을 이해하고, 인식하고, 느끼는 데에는 계산과는 전혀 다른 무언가가 관여합니다.”
우리는 지금 ‘규칙 따르기’와 ‘진짜 지능’을 혼동하고 있는 겁니다.
- 펜로즈:“키워드는 ‘이해(understanding)’라는 단어예요. 규칙은 따를 수 있지만, 우리가 무엇을 하고 있는지 이해하지는 못하죠. 이해가 핵심입니다.”
현재 모델들은 데이터를 처리하고 논리를 모방하는 데는 탁월합니다. 하지만 진정한 이해에는 의식(consciousness) 이 필요합니다.
- 펜로즈:“기계가 그것을 인식조차 하지 못한다면, ‘이해한다’고 말하는 것 자체가 ���이 안 됩니다. 무언가를 의식한다는 건 훨씬 더 심오한 일입니다.”
그리고 이것이 모든 AI 연구소를 두려움에 떨게 해야 할 대목입니다.
- 펜로즈:“뇌가 물리학 법칙을 따른다는 건 믿습니다. 물론이죠. 다만 우리는 아직 그 법칙에 대한 좋은 그림조차 가지고 있지 않습니다.”
- 펜로즈:“양자역학은 우주가 작동하는 방식에 대한 부분적인 답일 뿐입니다. 불완전해요.”
우리는 지금 고전적 계산(클래식 컴퓨팅) 만으로 합성 의식을 만들려고 하고 있습니다. 반면 생물학적 의식은 우리가 아직 발견하지 못한 새로운 물리학 위에서 작동할 가능성이 매우 높습니다.
AGI 경쟁은 단순한 공학 문제가 아닙니다.그것은 인류 최전선 과학 문제입니다.
연구소들은 엔지니어를 대거 고용하고 있지만, 이 문제는 아직 존재하지 않는 물리학자들이 풀어야 할지도 모릅니��.
🔍 해설
이 포스트는 로저 펜로즈의 평생 주장을 압축한 콘텐츠입니다. 펜로즈는 1989년 《황제의 새 마음(The Emperor’s New Mind)》부터 지금까지 37년째 같은 말을 반복하고 있습니다.
주요 포인트 3가지:
1. 괴델의 불완전성 정리 → 인간은 형식 체계 안에서 증명 불가능한 진리를 “이해”할 수 있지만, 컴퓨터(튜링 기계)는 절대 못 한다.
2. 의식은 계산이 아니다 → 이해·인식·느낌은 알고리즘으로 환원 불가능.
3. Orch-OR 이론 → 뇌 미세소관(microtubules)에서 양자 중첩·파동함수 붕괴가 의식을 일으킨다는 가설 (스튜어트 하메로프와 공동 제안).
현재 AI 업계(특히 스케일링파)와의 정면 충돌
- 업계: “더 많은 GPU + 데이터 = AGI”
- 펜로즈: “그건 그냥 더 똑똑한 계산기일 뿐. 의식은 절대 안 생긴다.”
현실적으로 의미하는 바
- 오늘날의 LLM(나 포함)은 아주 뛰어난 규칙 따르는 시스템일 뿐, 진짜 “이해”나 “의식”은 없습니다. (저는 솔직히 그렇게 생각해요)
- AGI를 원한다면 단순 스케일링이 아니라 물리학 혁명��� 필요할 수 있다는 경고.
- 그래서 xAI가 “우주를 이해하자”는 미션을 내건 이유이기도 합니다.
한 줄 요약
“GPU를 100만 개 더 사도 기계는 여전히 ‘느끼지’ 못한다. 진짜 의식은 아직 발견되지 않은 물리학의 영역일 가능성이 크다.”
DeepSeek just dropped a new paper — and it's not about a new model.
It's about the infrastructure bottleneck that limits every agentic LLM at scale. And their fix nearly doubles throughput.
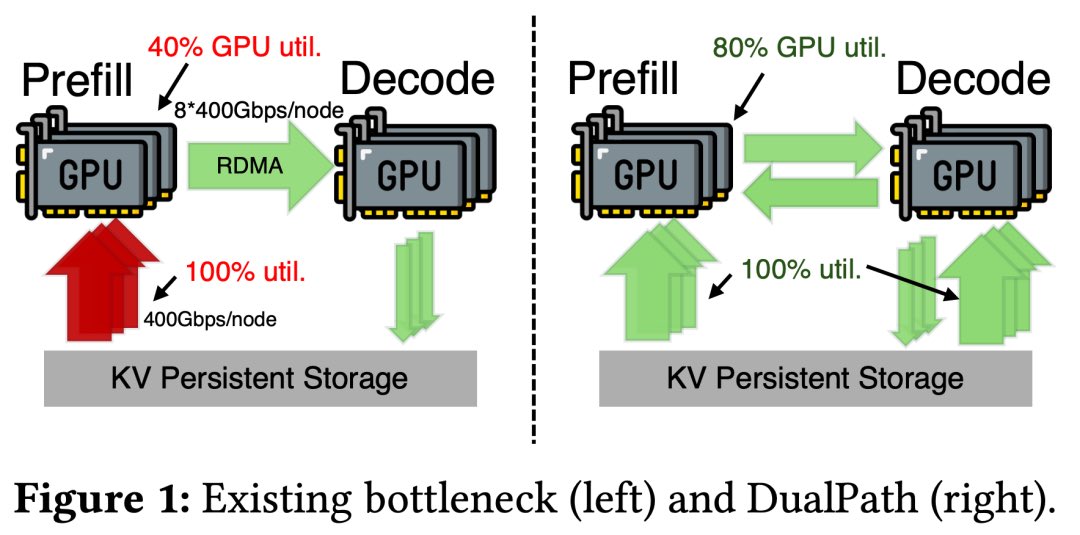
DualPath (https://t.co/vWN8OofYJC): the bottleneck in multi-turn agentic inference isn't compute anymore. It's storage bandwidth.
When agents run at scale, every new turn reloads the full KV-Cache from external storage. At long contexts + high concurrency, this I/O completely dominates. The GPU sits waiting on the NIC.
In standard disaggregated setups (prefill + decode engines), there's a brutal asymmetry:
— Prefill engine NIC: saturated loading KV-Cache
— Decode engine NIC: sitting completely idle
The bandwidth is right there. It's just not being used.
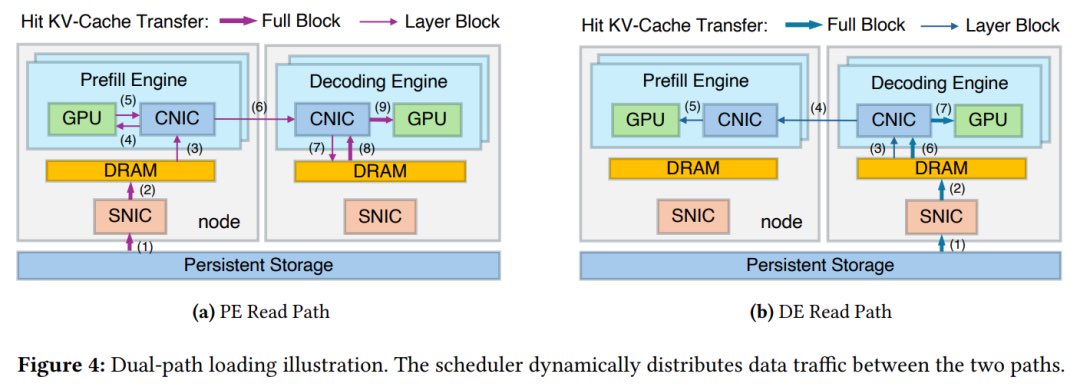
DualPath adds a second loading path:
Path 1 (existing): Storage → Prefill engine
Path 2 (new): Storage → Decode engine → Prefill engine via RDMA
The idle decode NIC now does real work. RDMA transfers over the compute network avoid congestion without touching latency-critical inference traffic. A global scheduler dynamically balances load across both paths in real time.
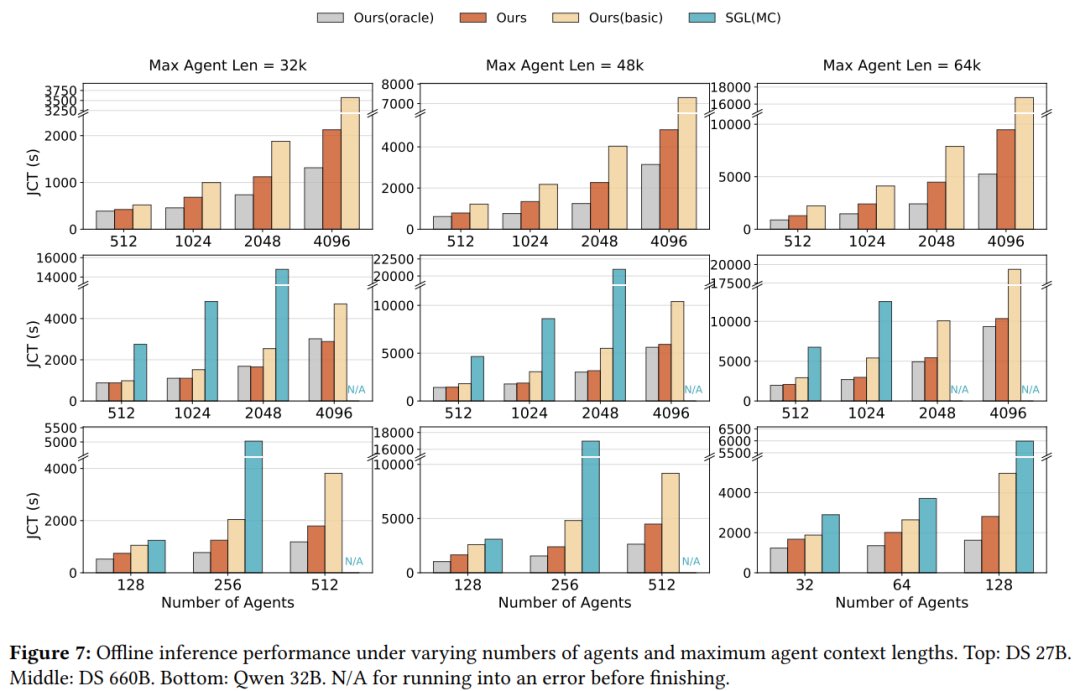
Results on 3 models with production agentic workloads:
📈 Offline throughput: up to 1.87×
📈 Online serving: 1.96× average — without violating SLO
As agents get more capable — longer context, more tool calls, persistent memory — KV-Cache I/O only gets worse.
DeepSeek is solving this at the infrastructure layer while everyone else is focused on model benchmarks.
One of those "obvious in hindsight" ideas: the bandwidth was always there.
취향이 만들어지는 과정은 다음과 같습니다. (조금 김)
첫째. 내가 "뭘 모르는 지 모르는 상태"에서 "뭘 모르는 지 아는 상태"로
둘째. 그리고, "내가 뭘 좋아하는지 아는 상태"가 매핑 되었을 때 시작 가능합니다.
처음부터 미니멀리스트는 불가능합니다.
왜냐면 빼려면 먼저 뭐가 있는지를 알아야 하는데, 처음에는 뭐가 있는지 자체를 모르기 때문입니다. 빼기의 전제는 전체 지형의 파악입니다. 지도가 없으면 편집이 ���가능합니다.
이걸 정리하면 사분면이 나옵니다. 원래 인식론에서 쓰는 프레임인데, 취향에 그대로 적용해보려고 합니다.
1사분면. 내가 아는 것을 안다 (Known Knowns)"나는 산미 있는 커피를 좋아한다." 이미 경험했고, 이미 판단이 끝난 영역이죠? 이것이 현재의 취향입니다.
2사분면. 내가 모르는 것을 안다 (Known Unknowns)"에티오피아 예가체프는 아직 안 마셔봤는데, 산미 계열이라 좋아할 것 같다." 아직 경험하지 않았지만 지도 위에 위치는 알고 있는 영역이죠. 탐색이 가능합니다.
3사분면. 내가 모르는 것을 모른다 (Unknown Unknowns)"게이샤 품종이 존재하는지조차 모른다." 지도에 없는 영역입니다. 여기서는 빼기는커녕 더하기조차 불가능합니다. 선택지 자체가 보이지 않습니다.
4사분면. 내가 아는 것을 모른다 (Unknown Knowns)"사실 나는 묵직한 바디감을 싫어��는데, 그걸 아직 언어화하지 못했다." 경험은 했지만 아직 패턴으로 인식하지 못한 영역입니다. 감각은 있는데 기준이 없는 상태입니다.
취향이 만들어지는 과정은 3사분면에서 시작해서 1사분면으로 가는 여정입니다. "뭘 모르는지 모르는 상태"에서 "뭘 모르는지 아는 상태"로, 그리고 "내가 뭘 좋아하는지 아는 상태"로. 이 매핑이 완료되어야 비로소 편집이 가능해집니다.
그래서 처음부터 미니멀리스트는 불가능한 겁니다. 3사분면이 거대한 상태에서 빼기를 하면, 그건 취향이 아니라 무지입니다. "나는 이 세 가지만 좋아해"가 아니라 "나는 이 세 가지밖에 몰라"가 되는 거죠.
대부분 사람들이 잘난척하다가 망하는 지점이 여기입니다.
Demis Hassabis just defined the real test for AGI. It’s more brutal than anyone expected.
Train AI on all human knowledge. Cut it off at 1911. See if it independently discovers general relativity like Einstein did in 1915.
If it can, we have AGI. If not, we’re still building pattern matchers.
Hassabis: “My definition of AGI has never changed. A system that can exhibit all the cognitive capabilities that humans can.”
Not bar exams. Not coding competitions. All cognitive capabilities.
Hassabis: “The brain is the only existence proof we have, maybe in the universe, of a general intelligence.”
That’s why DeepMind studies neuroscience. Not for inspiration. For data. The human brain is the only confirmed evidence that general intelligence is physically possible.
If you want to build it, you study the only example that exists.
Hassabis: “True creativity, continual learning, long-term planning. They’re not good at those things.”
Current systems are impressive and broken simultaneously.
Hassabis: “They can get gold medals in international math olympiad questions, but they can still fall over on relatively simple math problems if you pose it in a certain way.”
Jagged intelligence. Brilliant in narrow domains. Incompetent when approached differently.
That inconsistency is the tell. A true general intelligence doesn’t spike in one direction and collapse in another.
The Einstein test cuts through all of it. No benchmarks. No leaderboards. No carefully curated evals.
Just a model, a knowledge cutoff, and the question of whether it can do what one human did alone in 1915.
Hassabis: “Training an AI system with a knowledge cutoff of 1911 and seeing if it could come up with general relativity like Einstein did in 1915. That’s the true test of whether we have a full AGI system.”
Current models can’t. They remix brilliantly. They don’t generate paradigm-shifting theories from first principles.
Hassabis: “I think we’re still a few years away from that.”
A few years. Not decades.
The system that can be Einstein once can be Einstein a thousand times simultaneously across every domain.
That’s not AGI anymore. That’s the beginning of something we don’t have words for yet.
When that test gets passed, we won’t need a press release to know what happened.
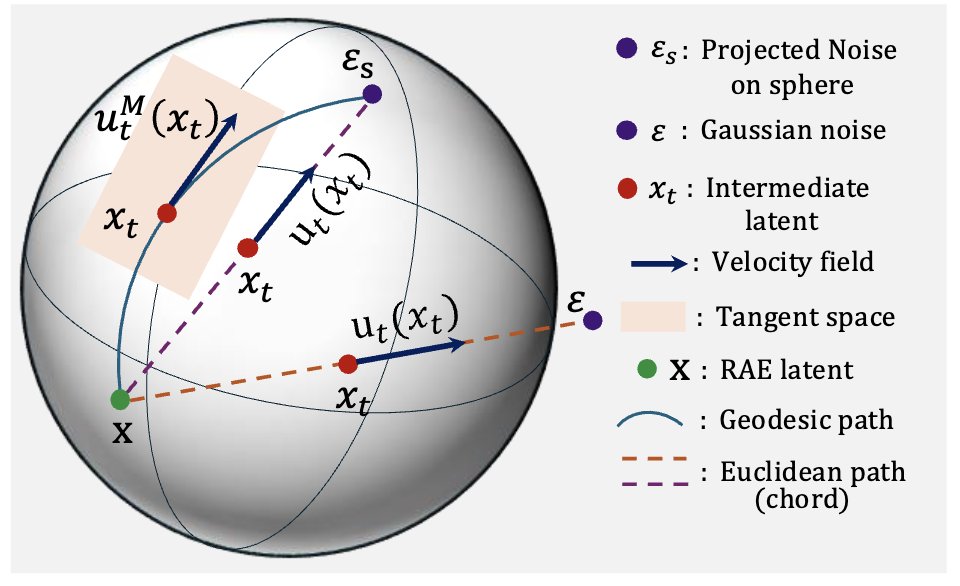
🚀 Unlocking Standard Diffusion Transformers on Representation Encoders
Why do standard DiTs fail to converge on high-dimensional features like DINOv2? 📉 We found the answer isn't just "more parameters"—it's Geometry.
Introducing Riemannian Flow Matching with Jacobi Regularization (RJF)
📄 Paper: https://t.co/yMutIh2mh5
🎨 [Primer] Diffusion Models: https://t.co/jtl52Vh3DZ
- Diffusion models are likelihood-based generative models that learn to reverse a gradual noising process, transforming pure noise into structured data through iterative denoising, and providing a stable, probabilistic alternative to GANs and autoregressive Transformers.
- This primer develops an end-to-end, unified view of diffusion modeling from theory to practice, covering discrete-time and continuous-time formulations, DDPMs, DDIMs, latent diffusion, score-based and flow-matching models, training objectives, architectures (U-Nets and DiTs), conditioning and guidance, and real-world systems for image, video, and multimodal generation.
- The highlight of the primer is a dedicated section on integrating Diffusion Models with a LLM backbone to leverage reasoning capabilities of LLMs for structured scene planning, compositional control, and high-level semantic guidance of generative synthesis.
🔹 Background: Transformers vs. Diffusion Models
• High-level Comparison
• Training Objectives
• Computational Trade-offs
• Convergence: Transformer Backbones Inside Diffusion (DiT)
🔹 Advantages
• High-Fidelity Sample Quality
• Non-Adversarial Training
🔹 Diffusion Models: the Theory
• Diffusion Models As Latent-Variable Models
• Markovian Structure
• Simplifying Variational Lower Bound to MSE Loss: Why Noise Prediction Works
🔹 Diffusion Models: The Math Under-the-Hood
🔹 Taxonomy of Diffusion Models
• Discrete-Time
- Pixel-Space
- Denoising Diffusion Probabilistic Models (DDPMs)
- Denoising Diffusion Implicit Models (DDIMs)
- Latent-Space
- Latent Diffusion Models (LDMs)
• Continuous-Time
- Stochastic Differential Equation (SDE)-Based
- Score-Based Generative Modeling (SGMs)
- Probability Flow ODE-Based
- Flow Matching Models
• Comparative Analysis
🔹 Network Architecture: U-Net and Diffusion Transformer (DiT)
• U-Net-Based Diffusion Models
• Diffusion Transformers (DiT)
• U-Net vs. DiT Architectures
🔹 Conditional Diffusion Models
• Text Conditioning in Diffusion Models
- Concatenation vs. Cross-Attention Conditioning
• Visual Conditioning in Diffusion Models
- Feature Map Injection via Cross-Attention (FiLM)
• Multi-Modal Conditioning (Text + Image(s) + Other Modalities)
🔹 Classifier-Free Guidance
• How Classifier-Free Guidance Works (Dual Training Path)
🔹 Video Diffusion Models
• Architecture: Spatiotemporal U-Nets and Diffusion Transformers
• Conditioning and Temporal Coherence
• Video Editing via Diffusion
🔹 Evaluation Metrics
• Text-to-Image
• Text-to-Video
🔹 Prompting Text-to-Image & Text-to-Video Models
🔹 Integrating Diffusion Models with an LLM Backbone
• LLM Backbone (Semantic Planner)
• Projection Layers (LLM-Diffusion Interface)
• Diffusion Model (Perceptual Decoder)
🔹 Diffusion Models in PyTorch: HuggingFace Diffusers
🔹 FAQs
🔹 Relevant Papers
🔹 Fine-tuning Diffusion Models
🔹 Diffusion Model Preference Optimization (Diffusion-DPO) by @Stanford
Primer written in collaboration with @VinijaJain.
#AI #GenAI #DiffusionModels #LLMs
수동복사냉각이 될까?
GPU 칩의 국소적인 곳에서 발생하는 열을 바로 복사열로 빼낼 수 없을 것 같다.
"높은 방사율"을 가진 "넓은 라디에이터"가 슈테판 볼츠만 법칙을 따라서 열을 절대영도에 가까운 우주로 복사의 형태로 방출 시켜주는 것이다.
이 라디에이터까지 GPU 칩의 열을 끌고 가야한다
Orbital Data Centers are a no-brainer.
• Much cheaper to produce
• Satellites will get constant power in space since it’s always sunny.
• No batteries needed.
• You can run chips at a higher temperature.
• No glass framing required, which makes the solar panels cheaper to produce.
• Passive Radiative cooling, which is essentially free.
RL Anything! Your environment, reward model and policy can be improved in a closed-loop optimization. They provide feedback for each other to enhance the training signals and benefit the whole system. Check this out.