Climatiser toute la France au niveau d’un pays comme le Japon arrivera de toute façon au cours des quinze prochaines années.
Quand il y aura trente jours de canicule par an, des écoles fermées, des morts qui s’accumulent dans les hôpitaux et les EHPAD, la résistance ne sera plus tenable.
Cela coûtera environ 150 milliards d’euros d’investissement, dont une cinquantaine pour les fabricants de matériel. Un marché colossal donc.
La France ne compte qu’un seul fabricant national de clim, Atlantic, et qui ne maîtrise pas les composants les plus technologiques, le compresseur inverter et l’électronique de puissance qui le pilote. D’où son partenariat de longue date avec le japonais Fujitsu. Le groupe pèse tout de même 2,8 milliards d’euros de chiffre d’affaires et emploie environ 6 000 personnes en France, réparties sur treize usines.
Manque de chance, vu le calendrier : Atlantic est en train de se faire racheter, par un ensemble nippo-américain, Paloma et Fujitsu côté japonais, Rheem côté américain. Le dossier est sur le bureau de Bercy, soumis au contrôle des investissements étrangers, et doit être tranché dans les prochains mois.
Pour quiconque a la tête sur les épaules, la solution est évidente : il faut conditionner l’autorisation du rachat à l’implantation en France d’une unité de R&D et de fabrication des composants critiques, compresseur inverter et électronique de puissance, opérée et dotée en personnel français formé par Fujitsu. Le bâton, c’est le feu vert de Bercy et la carotte, l’accès à un marché de plusieurs dizaines de milliards. Si nous validons le rachat sans négocier avant, nous perdons une occasion unique.
L’enjeu est de transférer le savoir-faire dans des têtes françaises. Quand des centaines d’ingénieurs et de techniciens sauront concevoir et industrialiser ces composants, la compétence pourra se diffuser dans tout l’écosystème. Ce n’est rien de plus que la bonne vieille technique utilisée par la Corée et la Chine pour remonter la filière.
Mais contrairement à la Chine, nous n’avons plus du tout le réflexe de nous demander comment nous ancrons tous les savoir-faire critiques sur notre territoire. Comment nous faisons en sorte que les dizaines de milliards que nous allons dépenser pour empêcher des petits vieux de mourir et des enfants de suffoquer en classe profitent à la reconstitution de notre tissu industriel et de notre prospérité.
Il est temps d’être beaucoup plus agressif dans notre politique industrielle et de mieux anticiper.
Il nous reste quelques mois.
Doing the most responsible thing an European AI labs can do after this weekend: shipping a blogpost. Why the EU can't into AI, how it's not about compute, but actual skill issue and failing for years to build an actual training ecosystem. https://t.co/Y8M7SJpGyT
@Dorialexander Brentano is also a major influence on modern philosophy of mind, and indirectly on some strands of cognitive science, especially on questions about how mental states represent states of affairs in the world through so-called "intentionality". :-) Can't recommend enough.
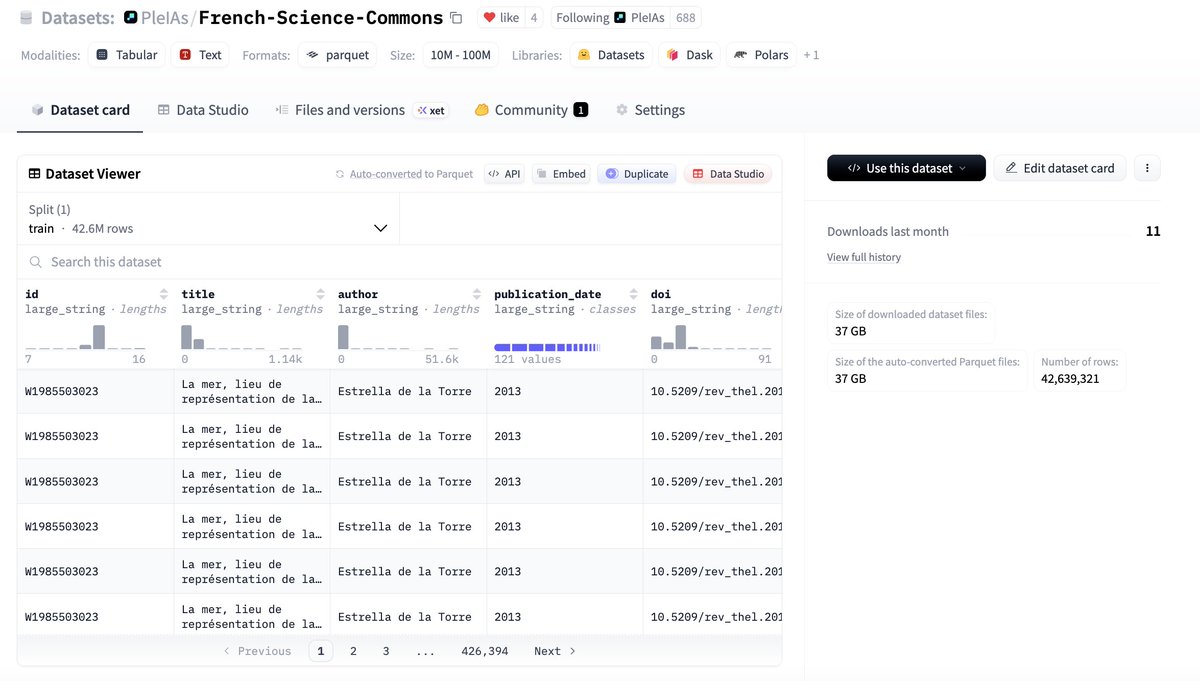
And new data release: French-Science-Commons, the largest scientific corpus in French in open access including 1.25 million documents/42 million pages re-digitized with VLM (dots ocr).
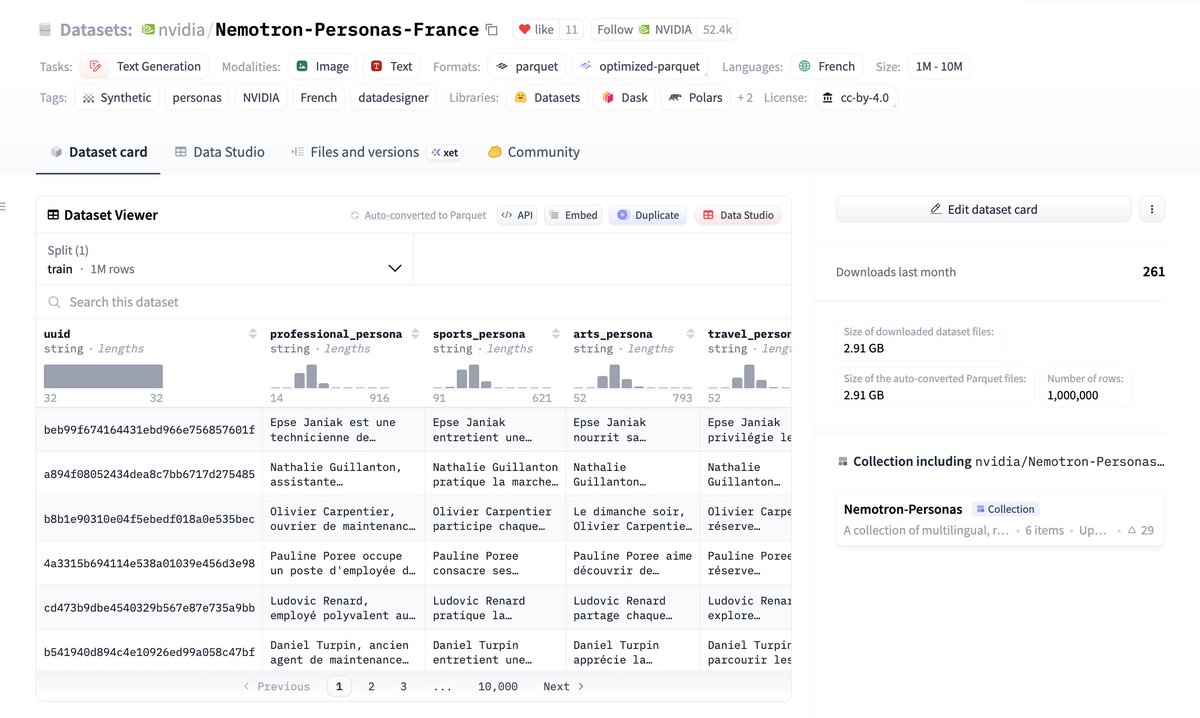
Breaking: @pleiasfr and @nvidia release the first open synthetic dataset for personas in Europe: Nemotron-Personas-France. 1M synthetic French persons, with rich imaginary lives grounded on (complex) demographic distribution.
A product that (almost) everyone uses from mid-sized tech companies and up but I rarely hear talked about: Grafana
In The Pragmatic Engineer 2025 survey, it had more mentions than Cursor, and dominates as the answer to "how do you turn information into graphs"
This is Grafana:
@0xblacklight@aidan_mclau Actual philosophers of cognitive science have a diversity of views. Some even defend the idea that experience doesn't exist. Some are among the most important ones in recent history (e.g., Dennett).
https://t.co/YOWJ9h4eO3
See also eliminative materialism
https://t.co/1kKPxG7oZJ
I’m thrilled to share that the Second Edition of The Book of Why will be released at the end of this year. It will include brief discussions of recent breakthroughs in causal inference, as well as some aspects of LLMs.
Join me on this next journey into the land of causality — the very heart of scientific thinking.
The final version of this paper has now been published in open access in the Journal of Memory and Language (link below). This was a long-running but very rewarding project. Here are a few thoughts on our methodology and main findings. 1/9
seven years after an initial meeting in seattle in march 2018, the results of the @ArcCogitate adversarial collaboration on theories of consciousness have just been published in @Nature. congratulations to the whole cogitate team! https://t.co/QIiHUxLM68
For my classification tutorial, I labeled 20,000 complex STEM scientific article titles and abstracts according to an elaborate proprietary taxonomy of about 1200 classes. To do that, I called 5 top non-reasoning LLMs for each document via @openrouter and took the majority label. The total labeling cost is about $100.
Doing the labeling by hand would be close to impossible due to the high complexity of the texts that would require very expensive experts to label them. And even if I had such experts, they would have to keep in mind too many classes (knowing by heart their definitions) to choose from. An enterprise like this, before LLMs, would cost hundreds of thousands of dollars.
LLMs have use cases that are absolutely revolutionary. But the cardboard influencers don't talk about them because they don't create anything. They only consume and regurgitate lies flowing from CEO social accounts.
If your input text is smaller than 512 tokens and you need a fast text classifier, fine-tuning a RoBERTa model (an encoder) generally gives a better classification result compared to a decoder LM of a larger size.
There’s currently a newer reincarnation of BERT, called ModernBERT, using rotary positional embeddings (RoPE), FlashAttention, and supporting sequences of up to 8192 tokens: https://t.co/RBjtlsGxFR
By the way, if you have a lot of labeled examples (and getting them by asking an LLM to label them is fast and cheap), you should always try training a CNN and bag-of-word-based shallow models. They might outperform transformers in text classification. (The readers of my LM book already know this, since text classification was one of the running examples in the book.)
I’m currently working on the text classification tutorial I promised to write a week ago. The results will be very unexpected to someone who learned about AI two years ago and believes that decoder LLMs are the ultimate architecture for NLP.
That's actually a crucial philosophical question there. Do embeddings contain representations? Meaning accuracy conditions against which they can be evaluated. Looks like the compositional logic happens one step above. Like network activations vs. "mental states" in the brain.
Neural networks don't have "representations"
They have embeddings, or meaningful patterns of neuron activation
They're meaningful in the sense of enabling us to do certain things
Differences that make a difference (to us)
They don't copy, reflect, or re-present the world