@brianryhuang Sorry I'm not following. What's the mechanism here that encourages hallucinations? If the answer is correct regardless of the post-hoc reasoning chain (because the model has memorized it), then it seems like RL wouldn't push the reasoning chain to do anything in particular?
Popular reasoning benchmarks just reward correct answers (they don't penalize guessing). This incentivizes models that guess when they're not sure which (beyond hurting usability) seems like it would encourage hallucinations more broadly. Is this why o3 etc. hallucinate a lot?
@brianryhuang Interesting--would this *encourage* hallucinations? It seems like it just wouldn't penalize hallucinations in post-hoc reasoning. I think as long as hallucinations aren't encouraged, they can be mitigated through, e.g., factuality RL (if they are encouraged, you get a tradeoff).
It can be helpful to pinpoint the in-context information that a language model uses when generating content (is it using provided documents? or its own intermediate thoughts?). We present Attribution with Attention (AT2), a method for doing so efficiently and reliably! (1/8)
@ko175041@YungSungChuang@aleks_madry Thanks! A two layer NN does a little better than a coefficient for each head, but not enough to make the added complexity worth it! Another potential axis for improvement is to add additional attention features besides just the "first-order" attention weights.
AT2 makes it practical to, for example, produce citations for an existing RAG system.
Check out our demo which uses AT2 for citations in an LLM-powered search tool: https://t.co/nxnkEkYUFM (7/8)
Increasingly, LLMs cite sources for claims they make, but are the sources they cite actually what they are using?
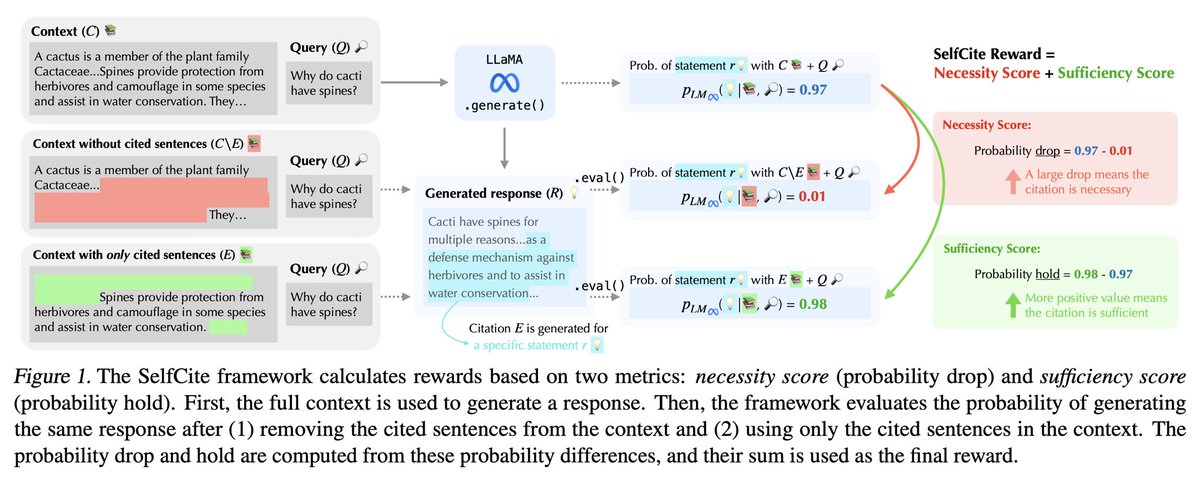
In work led by @YungSungChuang, we design a reward to quantify this, and use this reward to (automatically) improve citation quality!
🧵
(1/5)🚨LLMs can now self-improve to generate better citations✅
📝We design automatic rewards to assess citation quality
🤖Enable BoN/SimPO w/o external supervision
📈Perform close to “Claude Citations” API w/ only 8B model
📄https://t.co/FHj54HiC6i
🧑💻https://t.co/nQa87KkYMo
We introduce ContextCite, a tool that can help us understand when and how an LLM uses in-context information!
w/ @harshays_, @kris_georgiev1, @aleks_madry
Check out our demo:
https://t.co/9sV2jCEwAO
Thread ⤵️
How is an LLM actually using the info given to it in its context? Is it misinterpreting anything or making things up?
Introducing ContextCite: a simple method for attributing LLM responses back to the context: https://t.co/bm1t7nybbh
w/ @bcohenwang, @harshays_, @kris_georgiev1
@feng_jiahai@harshays_@kris_georgiev1@aleks_madry Great point, yeah! For k=1 we're pretty much at this optimal log-prob drop (we'll include a formal evaluation in the paper, but you can already see for k=1 things look pretty saturated as we increase the number of ablations in the plots in the blog post).
@xilinniao@harshays_@kris_georgiev1@aleks_madry Hi great question! This is definitely possible (this type of approach is usually called "leave-one-out"). We've tried this and it works reasonably well but is a lot more expensive than ContextCite. ContextCite only needs a small number of ablations due to sparsity (see our blog).