@Butanium_@jxmnop Great q! ModelDiff works with any example-level data attribution scores.
We got similar results with a faster / more scalable approach that needs O(10) models (vs 50k) to estimate attribution scores,
https://t.co/Nc8yyjEkD3
TRAK, our latest work on data attribution (https://t.co/OuY6lu8tfm), speeds up datamodels up to 1000x!
➡️ our earlier work ModelDiff (w/ @harshays_@smsampark@aleks_madry) can now compare any two learning algorithms in larger-scale settings.
Try it out: https://t.co/jViKWw9Ofl
@BasuSamyadeep@FeiziSoheil Nice! Just wanted to share our prior work on attributing LM generations back to in-context information (https://t.co/4UmwgHkbQG, w/ @bcohenwang@kris_georgiev1@aleks_madry).
Here's the code if you want to try it out: https://t.co/BCB5juRDW4 🙂
MoEs provide two knobs for scaling: model size (total params) + FLOPs-per-token (via active params).
What’s the right scaling strategy? And how does it depend on the pretraining budget?
Our work introduces sparsity-aware scaling laws for MoE LMs to tackle these questions!
🧵👇
🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
How can we really know if a chatbot is giving a reliable answer? 🧵
MIT CSAIL’s "ContextCite" tool can ID the parts of external context used to generate any particular statement from a language model, improving trust by helping users easily verify the statement: https://t.co/0Mk0EMdjgE
@nickhjiang Cool work! Just wanted to share our ~recent work (https://t.co/zEJ3oV0wrF, w/ @andrew_ilyas and @aleks_madry) on editing vision models by estimating how counterfactual interventions on model components change individual predictions :)
How do black-box neural networks transform raw data into predictions?
Inside these models are thousands of simple "components" working together.
New MIT CSAIL research (https://t.co/jwGcKDVxUT) introduces a method that helps us understand how these components compose to affect model behavior — a key step in making neural networks more interpretable. 🧵
How is an LLM actually using the info given to it in its context? Is it misinterpreting anything or making things up?
Introducing ContextCite: a simple method for attributing LLM responses back to the context: https://t.co/bm1t7nybbh
w/ @bcohenwang, @harshays_, @kris_georgiev1
New work with @andrew_ilyas and @aleks_madry on tracing predictions back to individual components (conv filters, attn heads) in the model!
Paper: https://t.co/zEJ3oV0wrF
Thread: 👇
How do model components (conv filters, attn heads) collectively transform examples into predictions? Is it possible to somehow dissect how *every* model component contributes to a prediction?
w/ @harshays_@andrewilyas, we introduce a framework for tackling this question!
Blog: https://t.co/Sinjbr8WC7 Code https://t.co/fTkkLca3mS Paper: https://t.co/3CLzfiddU2
[1/4]
If you are at #ICML2023 today, check out our work on ModelDiff, a model-agnostic framework for pinpointing differences between any two (supervised) learning algorithms!
Poster: #407 at 2pm (Wednesday)
Paper: https://t.co/sMXNJvm38M
w/ @smsampark@andrew_ilyas@aleks_madry
TRAK, our latest work on data attribution (https://t.co/OuY6lu8tfm), speeds up datamodels up to 1000x!
➡️ our earlier work ModelDiff (w/ @harshays_@smsampark@aleks_madry) can now compare any two learning algorithms in larger-scale settings.
Try it out: https://t.co/jViKWw9Ofl
You’re deploying an ML system, choosing between two models trained w/ diff algs. Same training data, same acc... how do you differentiate their behavior?
ModelDiff (https://t.co/wJI2dOAGc1) lets you compare *any* two learning algs!
w/ @harshays_@smsampark@andrew_ilyas (1/8)
Do input gradients highlight discriminative and task-relevant features?
Our #NeurIPS2021 paper takes a three-pronged approach to evaluate the fidelity of input gradient attributions.
Poster: session 3, spot C0
Paper: https://t.co/tnLwUBQtSh
with @jainprateek_ and @pnetrapalli
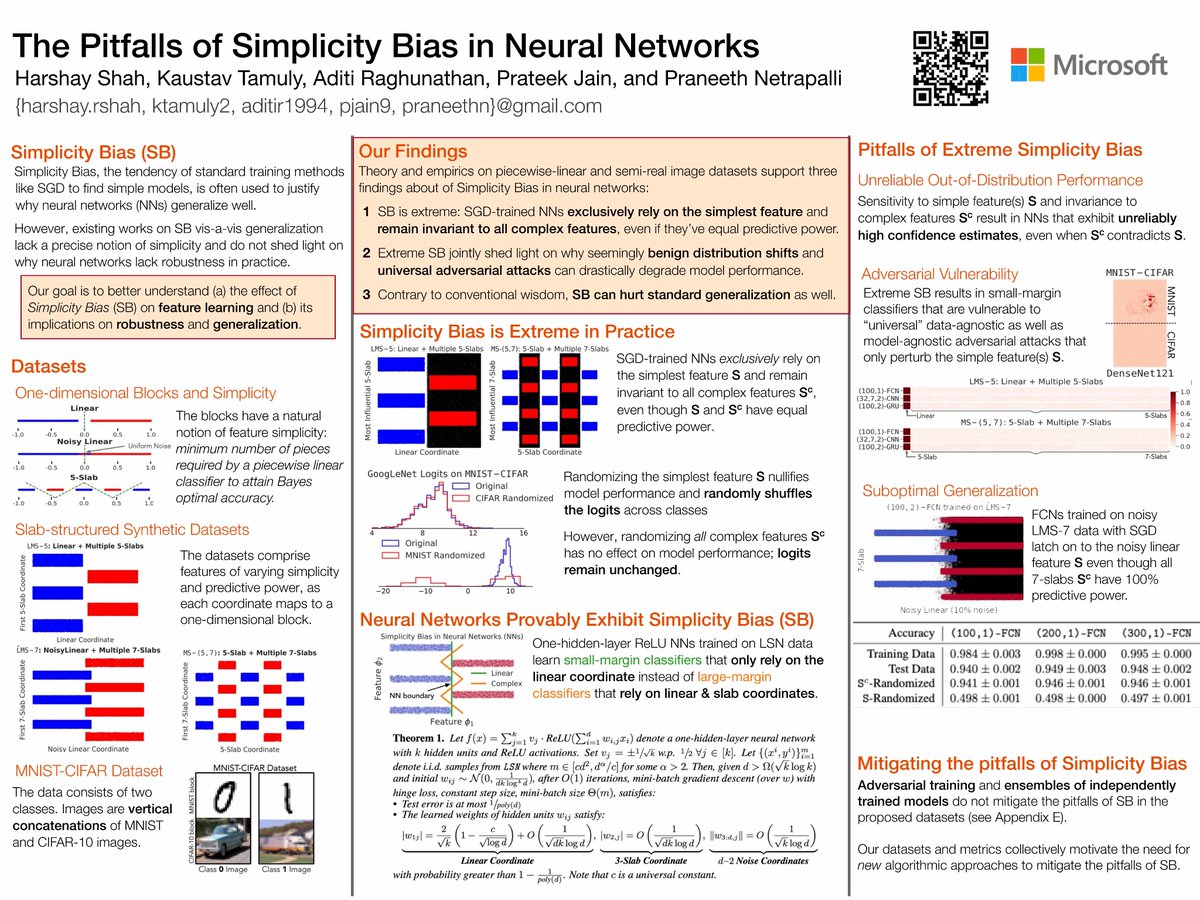
Neural nets can generalize well on test data, but often lack robustness to distributional shifts & adversarial attacks.
Our #NeurIPS2020 paper on simplicity bias sheds light on this phenomenon.
Poster: session #4, town A2, spot C0, 12pm ET today!
Paper: https://t.co/PszvszwTr0















![aleks_madry's tweet photo. How do model components (conv filters, attn heads) collectively transform examples into predictions? Is it possible to somehow dissect how *every* model component contributes to a prediction?
w/ @harshays_ @andrewilyas, we introduce a framework for tackling this question!
Blog: https://t.co/Sinjbr8WC7 Code https://t.co/fTkkLca3mS Paper: https://t.co/3CLzfiddU2
[1/4]](https://pbs.twimg.com/media/GLeC2QdbIAAULTP.png)