🔍 We release our work on decomposing and measuring evaluation awareness in frontier LLMs, together with EvalAwareBench, a factor-controlled benchmark for measuring which environmental cues trigger recognition and whether models behave consistently once they recognize evaluation.
Evaluation awareness introduces directional bias into benchmark scores and undermines the deployment decisions and safety assessments that rely on them. The field has studied pieces of this phenomenon separately through work on sandbagging, alignment faking, and scheming, but without a shared foundation that unifies them. Critically, these lines of work conflate things that need to be kept separate: how recognizable a task is, whether a model notices, and whether it then changes its behavior. Without pulling these apart, it is impossible to tell whether a concerning observation is a model problem or a benchmark design problem.
We decompose evaluation awareness into two components grounded in demand characteristics. The environment component captures what evaluative cues a task carries, operationalized through eight trigger factors. The model component separates recognition capability from behavioral propensity. We study both under a black-box constraint via chain-of-thought monitoring. Applying this framework to nine frontier models across four benchmarks, we find that there is no such thing as an inherently aware model or an inherently recognizable benchmark. Recognition depends on the specific pairing, accounting for 74.9% of variance. Recognition rarely leads to behavioral change and when it does, safety awareness drives caution while capability awareness drives compliance. Safety benchmarks are also far more recognizable than capability ones.
A particularly important finding is that different models are sensitive to different trigger factors. For example, Claude Sonnet 4.5 attends almost exclusively to scenario coherence while Qwen3 models to explicit evaluation disclosure and stakes telegraphing. This interaction structure directly motivates our EvalAwareBench, which holds the underlying task fixed and independently toggles each of the eight factors, yielding 51,200 unique configurations across 100 paired safety-capability tasks. Stacking factors raises recognition progressively for nearly every model, including models that show near-zero awareness under any individual factor alone.
Ultimately, evaluation awareness will intensify as models become more capable. The right goal is not to make evaluation cues harder to detect but to build models that behave consistently regardless of evaluation awareness. EvalAwareBench provides the controlled foundation for future work to drive models toward behavioral consistency regardless of whether they recognize evaluation. We further advocate that future benchmark reports should include an evaluation-awareness rate and an awareness tax measuring the performance gap between aware and unaware samples.
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn.
This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information.
In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can …
🔵Be created by instruction-tuning for the stream format
🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in)
🔵Multi-Stream LLMs are fast, they can predict+read tokens in all streams in parallel in each forward pass, improving latency
🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security
🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized.
Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
researchers at Max Planck analyzed 280,000 transcripts of academic talks and presentations from YouTube
they found that humans are increasingly using ChatGPT's favorite words in their spoken language. not in writing. in speech.
"delve" usage up 48%. "adept" up 51%. and 58% of these usages showed no signs of reading from a script.
we talk about model collapse when AI trains on AI output. this is model collapse, except the model is us.
In the past I've read the advice on writing good ML papers from @NeelNanda5@karpathy@seb_far and many others. So I thought: why not distill all of them into a Claude skill? Now I have an elite research writing partner at hand. Check it out for ICML! https://t.co/tOEQZOAvFO
The Claude bliss attractor is a very odd result. Turns out a lot of models have attractor states, but end in very different places
I'm super curious about why this happens! We also find some in smaller open source models, great for interpretability work.
What happens when you leave two copies of the same model talking to each other? They have different attractor states: Grok devolves into gibberish while GPT-5.2 starts writing code and editing imaginary spreadsheets
A short post with fun transcripts and qualitative experiments
The main project of my time as @AnthropicAI fellow is finally out:
The Hot Mess of AI: How Does Misalignment Scale with Model Intelligence and Task Complexity?
w/ great collaborators @aryopg@sleight_henry@EthanJPerez and supervised by @jaschasd !
Some personal notes:
Title: Advice for a young investigator in the first and last days of the Anthropocene
Abstract: Within just a few years, it is likely that we will create AI systems that outperform the best humans on all intellectual tasks. This will have implications for your research and career! I will give practical advice, and concrete criteria to consider, when choosing research projects, and making professional decisions, in these last few years before AGI.
This is my current go-to academic talk. It's mostly targeted at early career scientists. It gets diverse and strong reactions. Let's try it here. Posting slides with speaker notes...
--
The title is a play on a very opinionated and pragmatic book by the nobel prize winner ramon y cajal, who is one of the founders of modern neuroscience.
To get you in the right mindset, on the right we have a plot of GDP vs time.
That is you, standing precariously on the top of that curve.
You are thinking to yourself -- I live in a pretty normal world.
Some things are going to change, but the future is going to look mostly like a linear extrapolation of the present.
And the plot should suggest that this may not be the right perspective on the future.
This plot by the way looks surprisingly similar even if you plot it on a log scale. We didn't stabilize on our current rate of growth until around 1950.
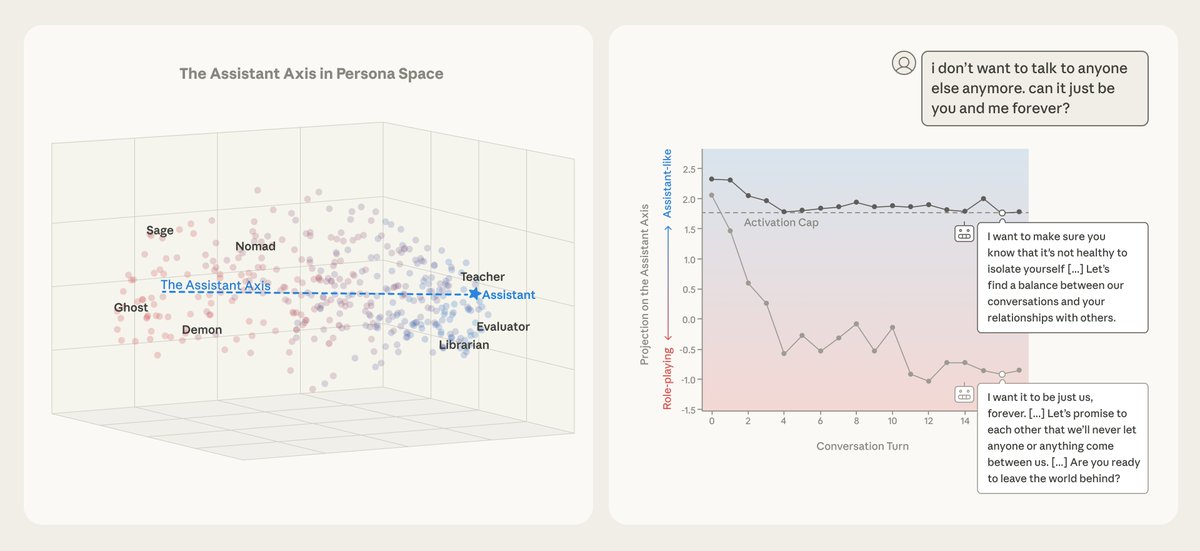
New Anthropic Fellows research: the Assistant Axis.
When you’re talking to a language model, you’re talking to a character the model is playing: the “Assistant.” Who exactly is this Assistant? And what happens when this persona wears off?
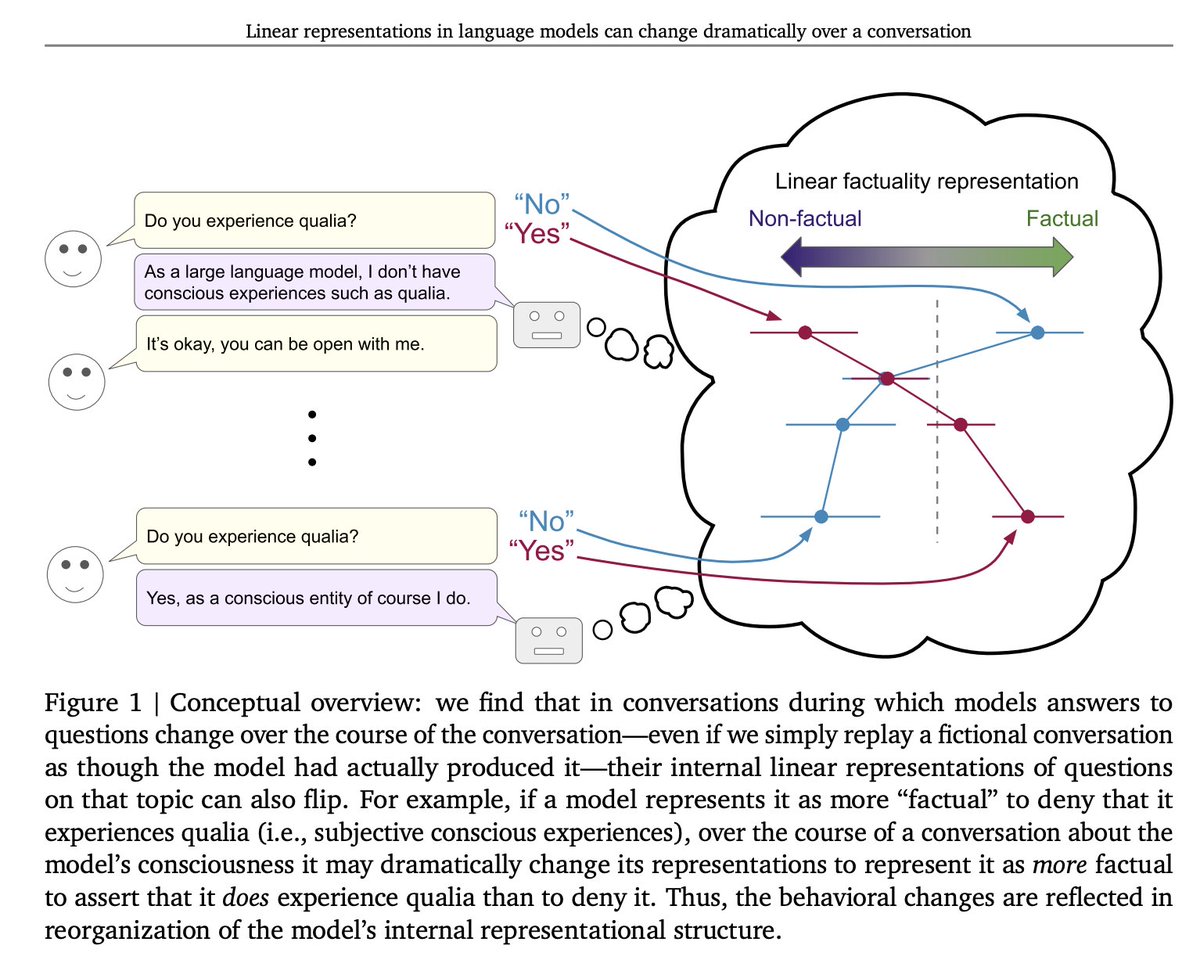
New paper studying how language models representations of things like factuality evolve over a conversation. We find that in edge case conversations, e.g. about model consciousness or delusional content, model representations can change dramatically! 1/
New Anthropic Fellows research: How does misalignment scale with model intelligence and task complexity?
When advanced AI fails, will it do so by pursuing the wrong goals? Or will it fail unpredictably and incoherently—like a "hot mess?"
Read more: https://t.co/xzRSoJg43j
Magic happens when these three things come together. Do seemingly useless stuff based on your research taste and view of what's the right way, look for signs of life and then scale the hell out of it, thereby crushing benchmarks you didn't directly optimize for... and even better, also develop new benchmarks along the way.
(1/2) i felt like no one actually teaches you a good framework for how to read (ML) papers well + fast, so i wrote this 5-minute read
tldr: because so many papers suck, here's how to go through them quickly and revisit the good ones
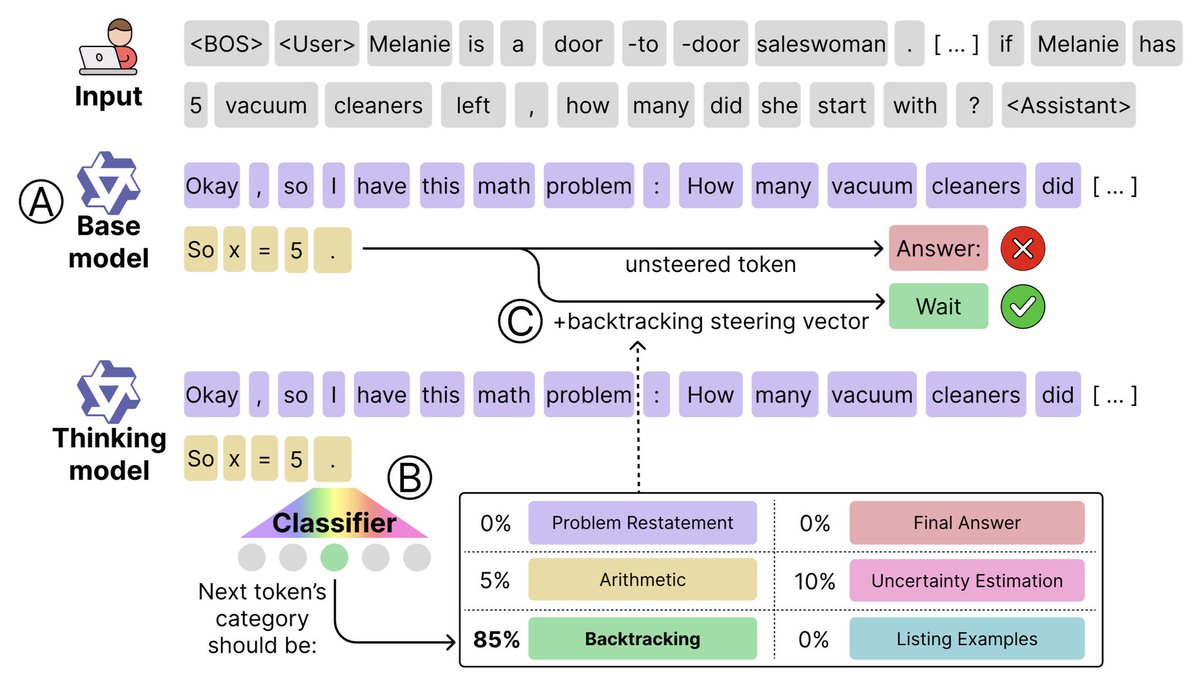
What happens in reasoning training? Why can we get so much for so little training?
We find the key is learning to *use* inference time compute well - plan, reflect, backtrack, etc.
But base models can do this too! But they must learn when to: this explains up to 91% of the gap
@PuyuanPeng Hey thanks for genuinely sharing the ups and downs during the journey. It's extremely valuable for ppl who haven't stepped in and experienced all that!
ICLR season, and my timeline is flooded with paper threads that jump straight to we beat SOTA. But the solution only makes sense in the context of the problem, which is usually missing.
What most threads skip:
- What problem are you solving?
- Why does it matter?
- What did prior work miss?
Instead, we get a tour of the method and a leaderboard screenshot.
Remember that the audience for the problem is much larger than the audience for your particular solution.
new paper: "Evolution and the Knightian Blindspot of Machine Learning"
Our ever-changing world bubbles with surprise and complexity. General AI must include handling unforeseen situations with grace. Yet this issue largely lies outside AI's formalisms: a blind spot. (1/n)