Excited to share that ThunderAgent has been integrated into NVIDIA Dynamo as an experimental router for agentic workloads!
ThunderAgent was designed to schedule at the granularity of agent runs, making agentic serving/rl upto 4x faster!
Huge thanks to @0xishand , @KranenKyle , and the Dynamo team. They have been exceptionally efficient and proactive — the team had already started pushing this forward even before I officially joined @nvidia .
Looking forward to seeing ThunderAgent ideas further evolve within Dynamo. And thanks for the help from @togethercompute
Link: https://t.co/CzteUYO0JD
@simran_s_arora@Chenfeng_X@_weilix@yinfang_chen
#AI #MLsys #Agent #Nvidia
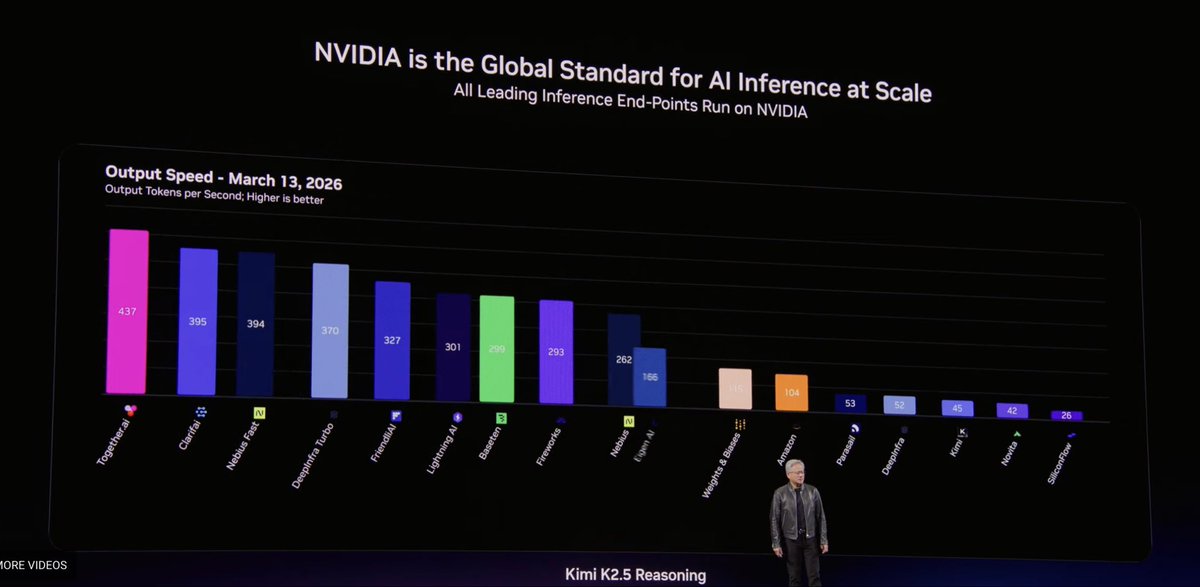
Our inference stack, optimized for Blackwells, with a novel attention kernel and many new optimizations has started rolling out!
It's already charting on Artificial Analysis, eg: #1 speed and latency for @Kimi_Moonshot Kimi 2.6. #1 on latency on @MiniMax_AI, and miles ahead of other GPU endpoints.
https://t.co/Yx6rIcZPyk
https://t.co/AdORQ3GLu9
LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).
Thanks @SemiAnalysis_ for featuring our work on distribution-aware accelerated RL rollout
TLDR
> identify problems are tend to require more thinking & rollout tokens
> allocate more speculative decoding budget to problems that cause bottleneck
> use adaptive speculator to maintain high acceptance length due to policy changing over time (can be anything but in this case we show the use of suffix tree speculator which is lightweight and can adapt fast over narrower data distributions)
> speeding up rollout without changing quality due to the verification nature of spec decoding
We’ll be doing an oral presentation next week at MLSys
The long-tail distribution of rollout lengths causes one of the most critical inefficiencies in RL training.
To mitigate this issue, researchers proposed draft model techniques to boost throughput, e.g. Eagle, MTP, and DFlash.
Distribution-Aware Speculative Decoding for RL Training proposes a draft model that adapts to the distribution of token prediction and token length.
We believe adaptive draft model techniques is still ripe for innovation.
https://t.co/hYhnS0VE6X
Authors: @tri_dao, @percyliang, @AlpayAriyak, @ben_athi, @yiying__zhang, @Chenfeng_X, @XiaoxiaWShirley, @QingyangWu1, @Ameen_ml (1/4)
We’re launching @JudgmentLabs today and announcing $32M in funding.
As AI agents take on more of the work that creates economic value, they generate massive amounts of production data: the clearest record of how they behave with users, software, and the real world.
Judgment builds infrastructure for improving AI agents from production data.
We push Prefill/Decode disaggregation beyond a single cluster: cross-datacenter + heterogeneous hardware, unlocking the potential for significantly lower cost per token.
This was previously blocked by KV cache transfer overhead. The key enabler is our hybrid model (Kimi Linear), which reduces KV cache size and makes cross-DC PD practical.
Validated on a 20x scaled-up Kimi Linear model:
✅ 1.54× throughput
✅ 64% ↓ P90 TTFT
→ Directly translating into lower token cost.
More in Prefill-as-a-Service: https://t.co/If8fA3t9Og
🤔The more I studied diffusion language models, the more I came to appreciate the simplicity of autoregressive (AR) language models. AR models are trained to agree with what they generate, and their serving stacks are built to preserve that structure. DLMs often do neither: they lack introspective consistency, and high TPF does not necessarily translate into high real-world TPS.
We propose Introspective Diffusion Language Model (I-DLM), which unifies introspection and generation in a single pass:
1. 🧑🎓I-DLM brings introspective consistency to DLMs with only 5B training tokens, achieving AR-thinking-level quality.
2. 🚀 I-DLM carefully trades compute for higher TPF while converting that advantage into real TPS under high-concurrency serving.
📖Website: https://t.co/826V7d49mA
⌨️Code: https://t.co/MPuy6rAXbq
Overall we're heading towards a multi-agent future
> through evolution, organisms evolve to specialize
> energy/food are a constraints, so organisms evolve to be efficient
> brain capacity is also a constraint -- being experts in all tasks is hard and suboptimal for survival from an energy perspective
> the same will apply for LLMs
> strong generic models are used for the hardest tasks that require strong judgment and critical thinking
> sub-tasks can easily be allocated to less capable and more effective subagents
> specialized agents have much higher intelligence-per-joule for subtasks
> given global compute constraint, inference optimization such as multi-agent framework will be one of the biggest and most impactful research fields
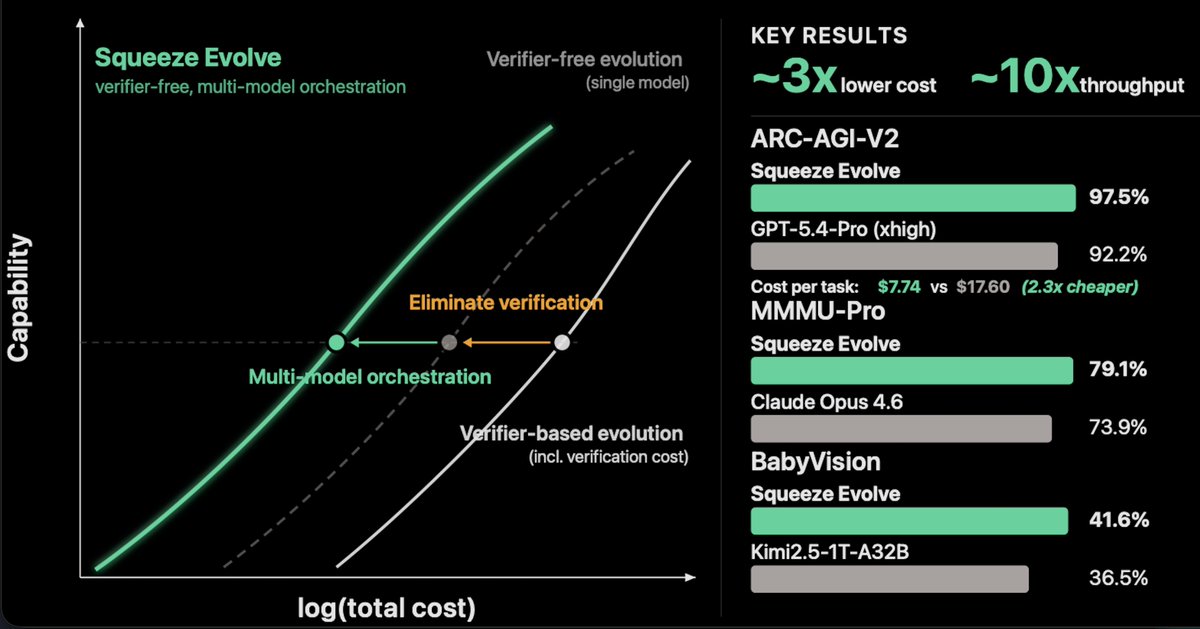
We're sharing an important progress in evolution via an efficient framework Squeeze Evolve
> not only improving capabilities, achieving SOTA @ 97.5% on ARC-AGI v2
> but also resulting in cost effectiveness (~3x lower than other methods)
> the key to this is using a multi-model framework
> multiple models bring diversity to sample solutions
> as well as allowing the use of smaller models on easier evolutionary steps
> verifier-free, which is crucial for tasks where verification is time-consuming
> a unified framework that combines all previous methods (Alpha Evolve, majority voting, self-refinement, RSA, and Mixture of Agents)
Super excited to Introduce our latest work: Squeeze Evolve.
We unify test-time scaling methods into one evolutionary framework — then orchestrate many models across it.
3x lower cost. 10x throughput. 97.5%(SoTA) on ARC-AGI-V2. No verifier required.
Framework: https://t.co/5hmOyZvSKU
New from Together Research: Aurora.
Speculative decoding that adapts to shifting traffic in real time — and keeps improving the longer it runs.
Open-source, RL-based, 1.25x faster vs. a well-trained static speculator with no offline retraining pipeline.
Thread 🧵
The frontier has increasingly shifted to hybrid models - from Qwen to Kimi-Linear and now with NVIDIA's Nemotron-3 Super - that rely on a strong linear sequence model. Today we release Mamba-3, the most powerful linear model to date.
https://t.co/OpMmqEWMkP
Glad to be highlighted during the GTC keynote.
We’re building the systems that bring frontier research to production and accelerate inference (and beyond). Come join us at Together!
@NVIDIAAI@togethercompute
https://t.co/3KeWBqBrjR
https://t.co/jxIr8sMk5S
Introducing v2 of our Open Deep Research app!
Generate detailed reports on any topic with open source LLMs. Fully free & open source.
We're releasing everything: evaluation dataset, code, app, and blog 🔥
Amazing @togethercompute conference bringing *together* the AI native community💫
Insane growth over 3 years & major milestones:
✅Flash Attention-4, Atlas-2, ThunderAgent
✅Trillions of tokens served per day
✅250MW+ of compute & counting
just getting started 🔥
The FA4 paper is finally out after a year of work. On Blackwell GPUs, attention now goes about as fast as matmul even though the bottlenecks are so different! Tensor cores are now crazy fast that attn fwd is bottlenecked by exponential, and attn bwd is bottlenecked by shared memory bandwidth.
Some fun stuff in the redesigned algorithm to overcome these bottlenecks: exponential emulation with polynomials, new online softmax to avoid 90% of softmax rescaling, 2CTA MMA instructions that allow two thread blocks to share operands to reduce smem traffic.
Really great work from Together research team on accelerating inference! @tanishqkumar07@avnermay@tri_dao
TL;DR - why run draft and verifier sequentially where you can run them in parallel?! The trick is that since we don't know what tokens will be accept, we start doing speculation for all possible accepted tokens. This leads to very low drafting time (due to the overlap), hence a significant speedup.
After a certain point scaling with TP doesn't increase TPS anymore, so this is a great way to add hardware and accelerate speed.
ps. We are hiring exceptional research engineers for Core ML team -- please consider joining us https://t.co/HvwHQyJd89
I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao@avnermay. Details in thread.
Pretty excited about this data release and thanks @percyliang for the project guidance.
We built a large-scale, test-verified trajectory pipeline across 51K tasks and 1,655 repos, then filtered down to 258K trajectories (155K passing).
The 59.4% pass@1 on SWE-bench Verified from a 32B model, with data built from our scaffolding.
Next step is scaling the data collection: more tasks, more scaffolds/tools, more diversity — and then moving beyond SFT into agentic RL.
These days, I'm much more excited about dataset releases than model releases. Models come and go and don't compose, whereas good datasets are more enduring and can be studied, used, revised to create better models more broadly. Excited about these 155K coding agent trajectories...just SFT'ing on this data improves SWE-bench Verified massively (23% -> 59.4%).