Assuming all this is true and emergency policy levers like export controls were necessary to avert disaster, all sides should be calling on Congress to pass sensible legislation. An ad hoc mess is good for nobody.
I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
"a month ago it was too dangerous to release but now all safety concerns have been addressed"
"The anjin says he secured ten of billions of funding in inference compute"
… any proposal like this is likely to quickly descend into tribalism over preemption and a ton of other issues unrelated to catastrophic risk, and we’re probably too close for the midterms to get anything done.
The Trahan-Obernolte draft is the most serious federal AI proposal to date. Certainly imperfect, but the auditing regime it proposes would be a meaningful step towards continuous assurance/accountability for frontier risks. Unfortunately….
Many developers have suspected for months that GPT-5.5 outperforms Claude Sonnet for coding. But SWE-Bench reported near-parity, and it made people question what they’d been seeing in practice.
DeepSWE aligns more closely with that day-to-day experience: GPT-5.5 scores 70% versus Claude Sonnet at 32%. That difference is substantial.
DeepSWE focuses on what tends to matter in real workflows: whether an agent can take a short behavioral prompt, locate the correct area of the codebase, and implement the change cleanly - without needing you to enumerate files, modules, and functions. SWE-Bench often fails to capture that, due to dataset contamination and weaker verification.
https://t.co/C3s80xfDkk
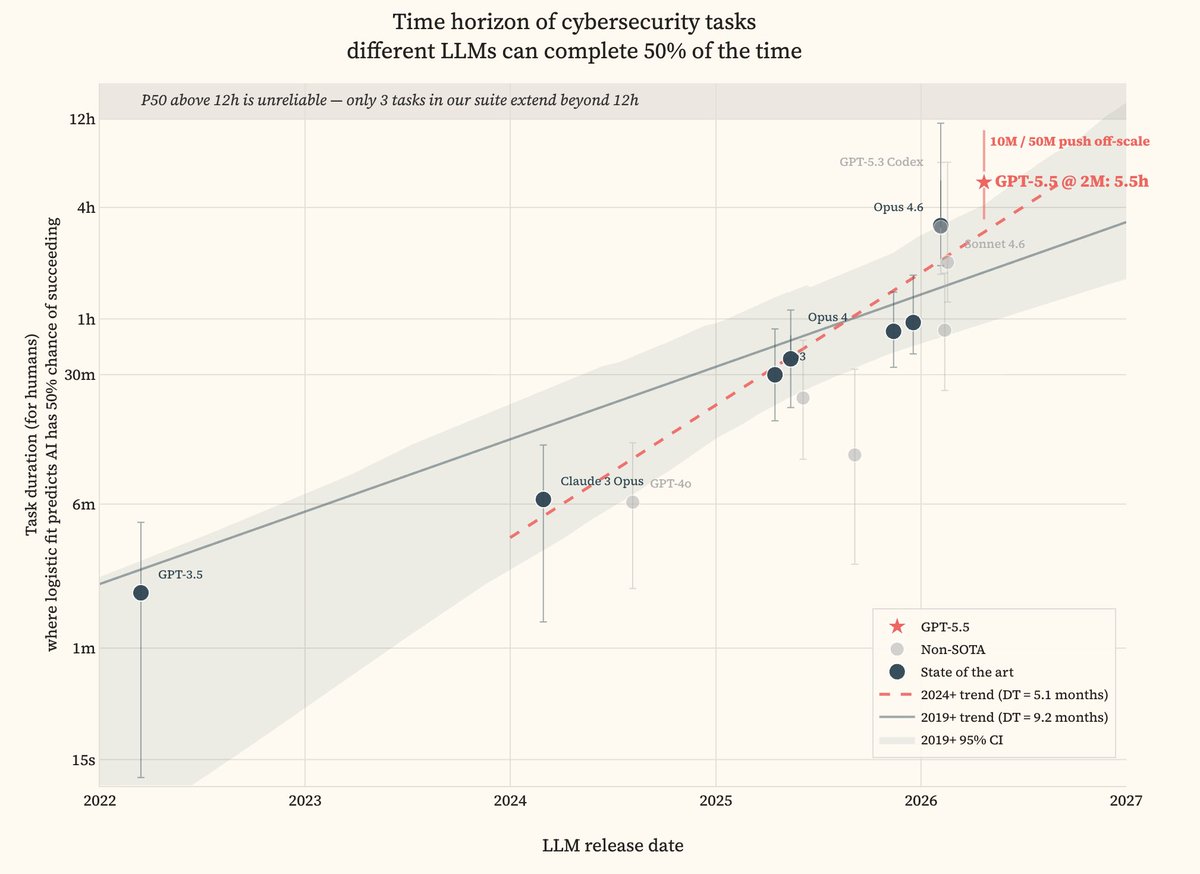
Two months ago we applied METR's time-horizon methodology to offensive cybersecurity, across 7 benchmarks with professional human baselines. Opus 4.6 at a 2M token budget achieved a 50%-time horizon of ~3h. We identified a trend doubling every 6 months since 2024.
GPT-5.5 now saturates our dataset.
At our 2M-token budget it reaches a time horizon of 5.1h. Pushed to 50M tokens it solves 92.4% of tasks and pushes off-scale past 12h.
Ferrari unveiled its first fully electric car, taking a high-stakes leap into EVs even as rivals including Porsche and Lamborghini scale back their ambitions amid weak demand https://t.co/3ntOvBehKz
Outside counsel: meet your clients where they work. If they live in Google Docs, sending a Word attachment is a small but avoidable miss. Anything that makes your client's life easier will earn you brownie points.
Characteristically great post from Nan. Most people are really sleeping on the importance of the OpenAI Foundation - it's already displaced Gates as the biggest foundation in the country by assets.