The DAIO project has an official website and a new update is up on the latest. Happy halvening and here's to another interesting four-year cycle! https://t.co/jS0SWmxlxz https://t.co/TOFW905HrR
I started a new project. If anybody's interested in BTC and/or data analysis, then follow along on YouTube! Hit like, subscribe, etc, etc. https://t.co/jnAXKkNpTc
Been trying to reconcile a bunch of different aspects of NN behavior and cognition by playing with formulations of latent space at a level (also) suited for reasoning about everyday cognitive phenomena
In part it's led to a compact, diagrammable geometric system
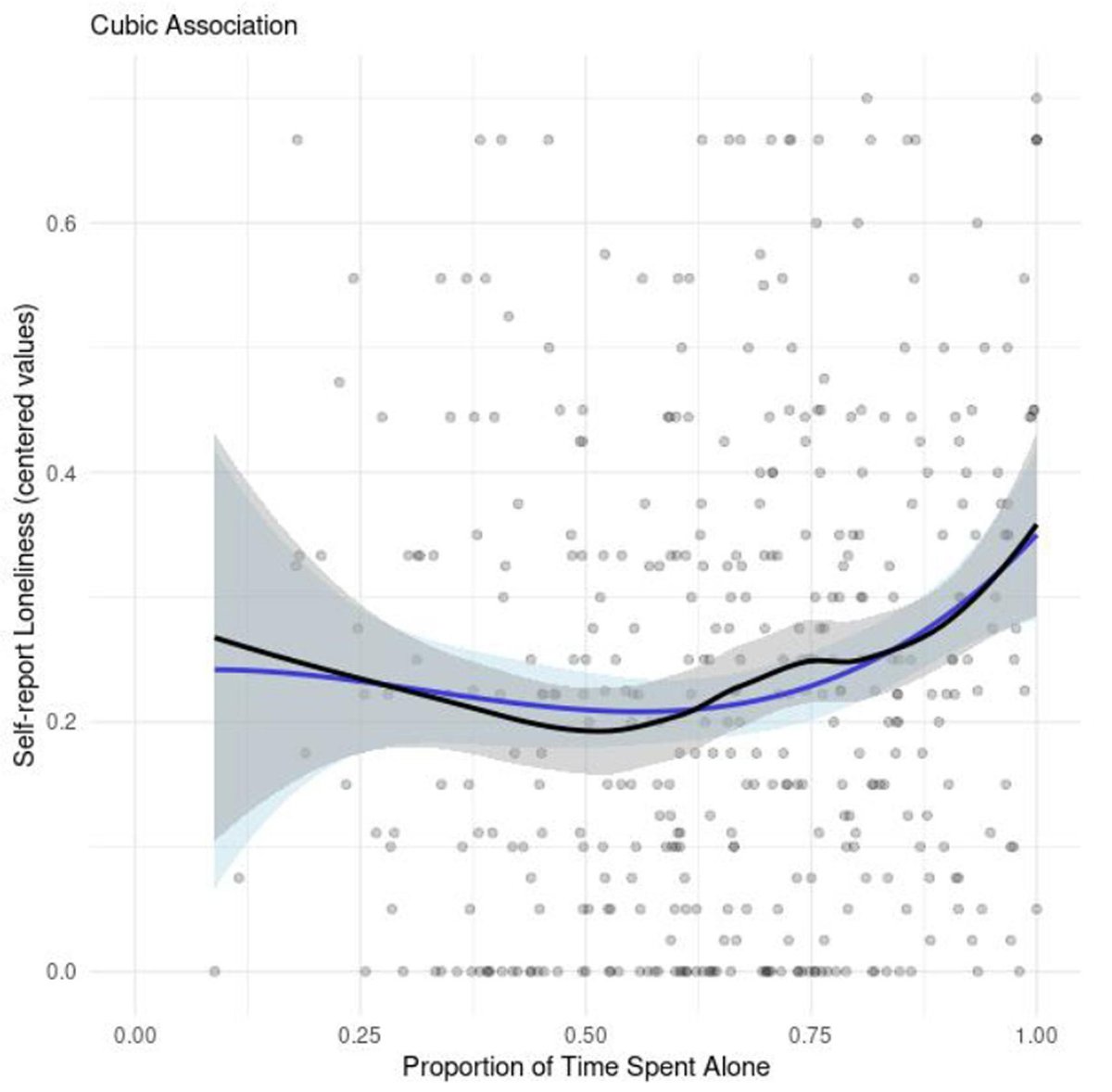
The best cure for loneliness is not more frequent interaction. It's more meaningful interaction.
Many people enjoy solitude. They can spend up to ~75% of their time alone without feeling isolated.
What matters most for well-being is the quality of connections, not the quantity.
The AI models = nuclear weapons analogy is terrible for a lot of reasons, but most importantly it heavily misleads policy-makers. Nuke-inspired regulation won't prevent people from building powerful AIs, but it will protect tech companies from competition 🧵
Introducing OpenWebMath, a massive dataset containing every math document found on the internet - with equations in LaTeX format!
🤗 Download on @HuggingFace: https://t.co/tFBHaX2Jpt
📝 Read the paper: https://t.co/mLnbbVPBWS
w/ @dsantosmarco, @zhangir_azerbay, @jimmybajimmyba!
The fact that most individual neurons are uninterpretable presents a serious roadblock to a mechanistic understanding of language models. We demonstrate a method for decomposing groups of neurons into interpretable features with the potential to move past that roadblock.
Created a WebGL neural network visualization for the quadruped robot I've been working on. The more red, the higher the activation. Bluer is less activation, while green is a midpoint.
With many 🧩 dropping recently, a more complete picture is emerging of LLMs not as a chatbot, but the kernel process of a new Operating System. E.g. today it orchestrates:
- Input & Output across modalities (text, audio, vision)
- Code interpreter, ability to write & run programs
- Browser / internet access
- Embeddings database for files and internal memory storage & retrieval
A lot of computing concepts carry over. Currently we have single-threaded execution running at ~10Hz (tok/s) and enjoy looking at the assembly-level execution traces stream by. Concepts from computer security carry over, with attacks, defenses and emerging vulnerabilities.
I also like the nearest neighbor analogy of "Operating System" because the industry is starting to shape up similar:
Windows, OS X, and Linux <-> GPT, PaLM, Claude, and Llama/Mistral(?:)).
An OS comes with default apps but has an app store.
Most apps can be adapted to multiple platforms.
TLDR looking at LLMs as chatbots is the same as looking at early computers as calculators. We're seeing an emergence of a whole new computing paradigm, and it is very early.
Excited to share #AlphaMissense our new AI system that can classify whether genetic mutations (missense variants) are benign or harmful - a critical step toward uncovering causes of many diseases, from cystic fibrosis to cancer. In @ScienceMagazine today https://t.co/pIsskIe1cP
Language Modeling Is Compression
paper page: https://t.co/tECPHg8y8S
It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
One of the best feelings as an engineer is when you reach the point where nothing seems impossible or unlearnable and the only factors getting in your way are time and energy.
The frustrating part is that you only seem to reach this point when you have limited time and energy.