🧠 From early programming lessons to scaling #AI on supercomputers, Abhinav Bhatele (@bhatele) shares his path and research at @UofMaryland's Department of Computer Science.
Read more: https://t.co/KEwHty5nkc
Congratulations to Dr. Joy Kitson for successfully defending her PhD dissertation last Friday (April 10)! That makes her the fifth PhD student to graduate from our group.
Dissertation title: "Scaling Agent-based Epidemic Diffusion on HPC Clusters"
On Mar 25, we set a personal record with 2 PhD defenses in a day! Congrats to @onurcankur & @jhdavis_josh for their excellent work:
Onur's title: "Longitudinal Data Analytics of HPC Systems & Applications"
Josh's title: "LLM-driven Development of Performant & Portable GPU Codes"
If you are interested in collaborating with us or you are an undergrad planning to apply for a PhD, come and talk to us (don't feel shy!). You'll find me or PSSG students at the events below. #SC25
We have arrived in St. Louis for @Supercomputing 2025. Learn more about our group's research through the various talks, panels and tutorials below. We will also be at the @UofMaryland booth (3123) at various times. #SC25#UMDCS#HPC#AI#MLSys#AI4Science
A large number of PhD students in my group have graduated or will be graduating by Spring, so I am recruiting several PhD students for the next admission cycle (Fall 2026). If you want to work with us, apply by Dec 5 and drop me a short email. Please repost/share widely. #HPC#AI
Fine-tuning massive LLMs requires reliability at scale. The Lightning open source stack gives you just that.
Check out Democratizing Al: Open-source Scalable LLM Training on GPU-based Supercomputers.
✅ 405B param MoE language model
✅ Fully finetuned on 32,768 GPUs on a massive 1.4 exaflop/s cluster
✅ All running on LitGPT
Led by @siddharth_3773 and @bhatele at @UofMaryland.
Read the paper ➡️ https://t.co/86mPNxjPAZ
Use LitGPT ➡️ https://t.co/mRqAGr40aV
Congrats @siddharth_3773! Siddharth is going to join NVIDIA after he graduates to continue working on parallel training and inference.
Follow him to keep track of what interesting stuff he’ll do next 😊
We are on a roll, second successful dissertation defense in a week (March 28)! Congratulations to @siddharth_3773 on becoming the second PhD graduate from PSSG!!
Dissertation title: "Optimizing Communication in Parallel Deep Learning on Exascale-class Machines"
#HPC#AI#HPC4AI
Riken, including our center R-CCS, is hiring researchers big time, from PIs to postdocs to interns. We have the best support for international researches; in fact the % of non-JP researchers at R-CCS is approaching 50 % now. Come work with us! https://t.co/DhTYia461v
Incredibly proud moment for me as an advisor. The first cohort of students in @hpc_group started in 2020 and they are now starting to graduate. Also a bittersweet moment as we bid adieu to some senior students this Spring & welcome new ones in the Fall. Congrats @DanielNichols10!
We present our very first newly minted Dr. Daniel Nichols (@DanielNichols10), who successfully defended his dissertation today. Congrats & best wishes for a bright future ahead!!
Dissertation Title: "On Learning Behaviors of Parallel Code and Systems Across Modalities"
#HPC#AI
We have a postdoc opening in our group on the intersection of HPC and AI, specifically on developing and applying Code LLMs to HPC software development. Please help us spread the word:
https://t.co/i4Gi5xPsTr
Position will remain open until filled. #HPC#AI
Come see our #NeurIPS2024 poster today on"
Loki: Low-rank Keys for Efficient Sparse Attention"
Paper: https://t.co/MwRsuFYaks
Code: https://t.co/ZUMt1ped6x
Loki is a sparse attention method that reduces the computational and memory costs of LLM inference! By exploiting the low-dimensional space of key vectors in self-attention, Loki achieves faster attention computation without compromising model performance.
@prajwal1210 will be presenting this work today (Dec 13) @NeurIPSConf in the poster session from 11 am-2 pm in East Exhibit Hall A-C (Poster# 2000). Come and say hi!
#NeurIPS2024#HPC#AI
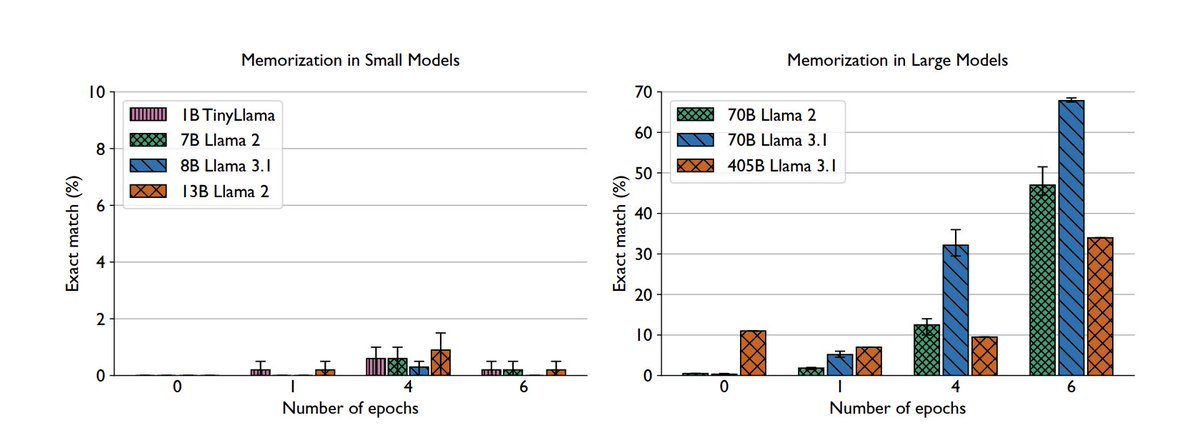
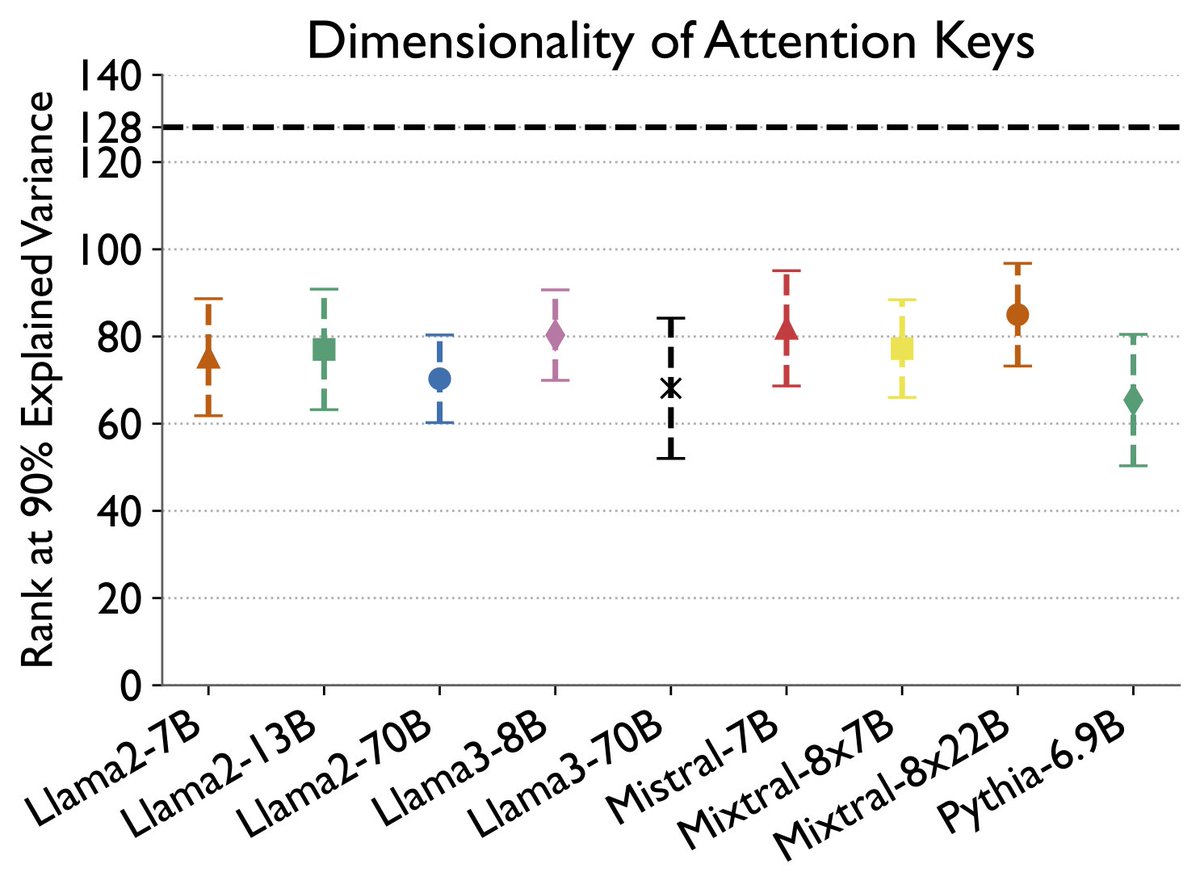
Can we get away w/ reducing attention keys to a lower-dimensional space to optimize compute during inference?
@prajwal1210 & @siddharth_3773 investigated using PCA on key vectors & found that the rank of attention keys is much lower than the full dimensionality. #NeurIPS2024
Why is addition hard for next token predictors? Come hear about our fix for this at #NeurIPS!
We’re presenting Abacus Embeddings 🧮 tomorrow (Friday) from 11-2 in the East Exhibit hall at poster 2907.
Drop by to see how we can improve your language model.
🏆 Researchers from the @UofMaryland received the HPC Innovation Excellence Award from @Hyperion_HPC for their work on AxoNN—a scalable framework that’s pushing the limits of Large Language Model (LLM) training! 🚀
💫 https://t.co/xxfslEx7zq
🏆 https://t.co/8BjP8VyxmO
Congratulations to the winners of the #HPC User Forum Innovation awards at #SC24
o Siddharth Singh and Abhinav Bhatele
o Eric Nielsen
o Nils Helset
https://t.co/9ruv4BUHOL
A team of parallel computing and machine learning experts from @UMDscience and @umiacs has been named a finalist in a global competition recognizing outstanding contributions in high-performance computing.
The team—led by Abhinav Bhatele and Tom Goldstein—is one of six vying for top honors in this year’s ACM, Association for Computing Machinery’s Gordon Bell Prize competition.
https://t.co/oUNnadw3LD