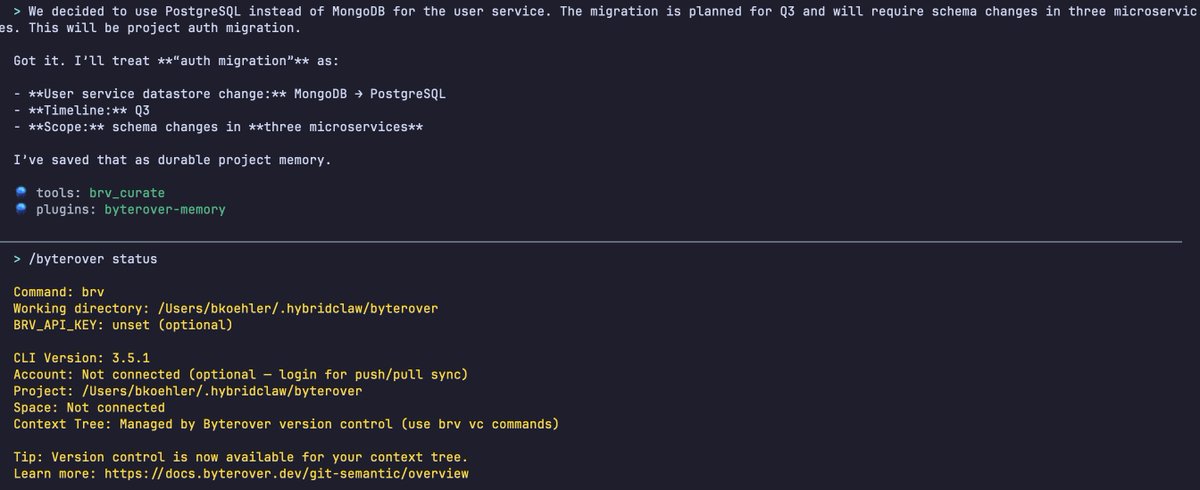
HTML vs Markdown for agent memory. Which is better in real production?
After the previous benchmark with 603 questions and HTML won on all accuracy, token saving and latency reduction. So, we were questioning:
Does HTML still perform better in real production at a larger scale?
To answer that, we re-ran our LoCoMo benchmark on the full set with 1,982 questions across 11 conversations. The results:
- HTML scored 90.77% accuracy at a total cost of $4.11, while Markdown scored 90.51% at $8.30.
- HTML ran 40% faster on query and 12.5% faster on curate.
Beyond the numbers, HTML brings three more benefits:
1. Anyone with a browser can open HTML without extra tools:
An HTML file opens directly in any browser, while Markdown files need a separate viewer or editor to render properly.
2. Agents can search HTML like a database and return the exact answers
3. HTML fits inside the new cross-agent protocols: A2A (Agent-to-Agent) and MCP (Model Context Protocol) both expect standardized input and output, and HTML provides exactly that.
We are shipping HTML as the default format for ByteRover soon
HTML vs Markdown for agent memory: Which is cheaper?
Before we ran the benchmark, we expected HTML to cost more because it carries images and charts.
Surprisingly it was 42% cheaper. Also 5.9% more accurate and 39% faster
The test was conducted across 271 sessions, 603 questions on LoCoMo
Check how we tested ↓
Your memory, organizing itself while you sleep.
ByteRover Dreaming runs while your agent is idle:
→ merges near-duplicate notes
→ connects topics that share patterns
→ archives stale drafts
Nothing changes without you. Every proposal comes with the reasoning, and one command to approve.
run brv dream
Your shared memory across Claude Code, OpenClaw, and Hermes is invisible. Now it's a webpage.
The Local Web UI for ByteRover (OSS memory system): Manage your team's context across every entry and every project, in one place.
→ trace decisions back to where they were made
→ recall how a teammate solved the same problem last month
→ see context ranked by relevance, automatically
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
Never let one vendor own your workflow" is trending again today. the version that actually matters: never let one vendor own your context.
models are swappable. chat history, prompt libraries, custom instructions, integration state, agent memory those you can't rebuild when the vendor goes sideways.
what you accumulated is the moat. keeping it portable is the discipline.
the vendor risk everyone's scared of isn't losing the model. it's losing everything you built on top of it
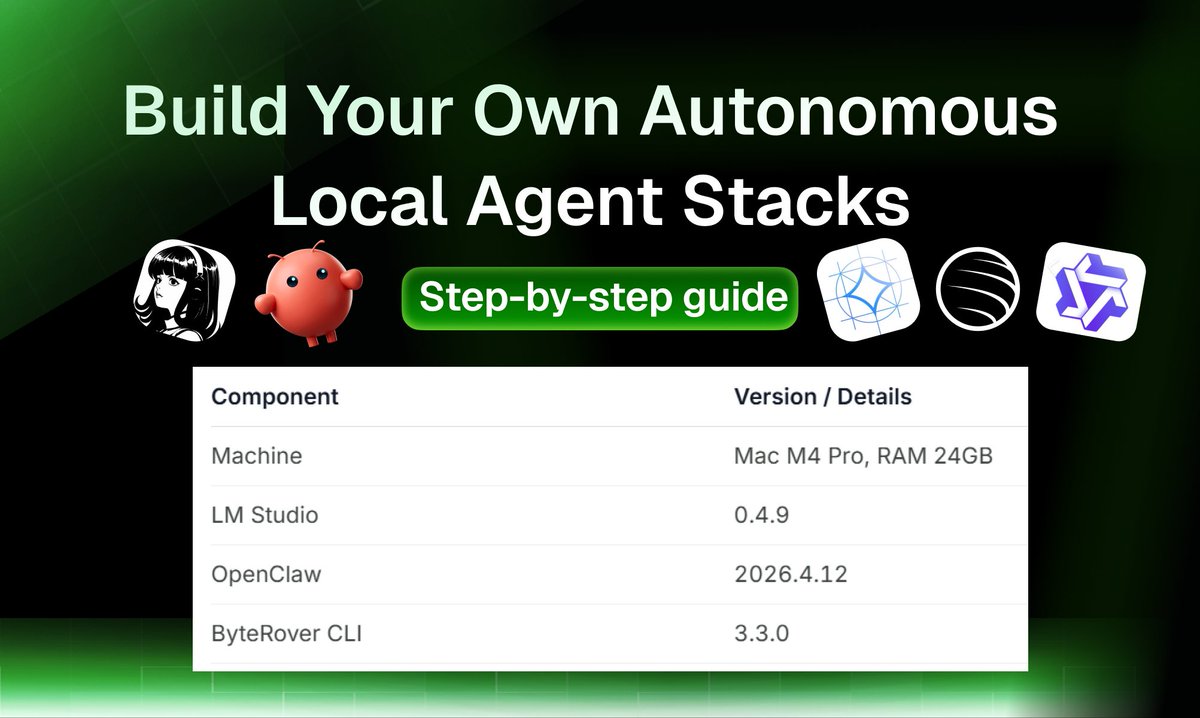
Build Your Own Autonomous Local Agent Stacks
That save 83% on token costs and give your agents 92% long-term memory retention.
This guide helps you set up a fully local and private autonomous stack. This means your data stays on your machine, your agents don't forget their tasks, and you stop paying for expensive cloud API tokens.
The Stack Components:
💪The Execution Agents: OpenClaw (2026.4.12)/ Hermes → run the actual tasks and scripts on your computer.
🧠The Brain (Local LLM): Gemma 4, https://t.co/cSsh2XhKph’s GLM-5.1, and Qwen 3.5 → able to handle complex tasks like coding, media generation, or researching
🤖The Memory Engine: ByteRover (3.3.0) → filesystem memory that connects natively with your tools and keeps context organized
Hardware Requirements
- For this experimental setup, we run on Mac M4 Pro, RAM 24GB (ByteRover and autonomous agents can run on a Apple RAM 24GB machine)
- For production usage we recommend at least an Apple M4 with RAM 48GB.
Step 1: Downloads the local LLM models
You will need two specific models to balance performance and memory efficiency:
- Gemma 4 E4B (Q4): This is for OpenClaw to handle reasoning. (Uses ~8.7 GB RAM)
- Qwen 3.5-9B (Q8): This is for ByteRover to manage your data. (Uses ~10.5 GB RAM)
On a 24 GB machine, both models fit in memory simultaneously. Gemma 4 E4B at Q4 uses ~8.7 GB and Qwen3.5-9B at Q8 uses ~10.5 GB.
Step 2: Load Both Models in LM Studio
Open LM Studio and load both models simultaneously. On a 24GB machine, these will fit together, leaving just enough room for your system to run smoothly.
Step 3: Configure Your Agent
Whether you choose OpenClaw or Hermes, the setup is the same:
- Point the agent to your local LM Studio endpoint.
- Adjust Memory: By default, OpenClaw handles 50,000 tokens. To change this, edit your openclaw.json file and run openclaw gateway restart to apply the update.
Step 4: Connect ByteRover Memory
Finally, set up the ByteRover CLI:
- Link it to the same local endpoint.
- Select the Qwen model as the primary memory handler.
The Result: You now have a persistent AI assistant that remembers your project details across different sessions. Everything stays local, with Cloud option if you ever need to collab with your teams
Detailed guide for each step 👇
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
@ashwingop tested five architecturally distinct memory systems (vector DBs, knowledge graphs, context windows, BM25/filesystem, parametric memory) and then proved with math why the filesystem approach wins.
He mentions @ByteroverDev (alongside with @Letta_AI , ClaudeCode, @ManusAI and @openclaw) as rare real-world examples of filesystem-based memory actually shipping in production and delivering meaningful accuracy.
Here’s what we’ve been shipping:
- Your memory lives in simple, human-readable markdown files (not hidden vectors)
- Native memory for OpenClaw, Hermes, and 22+ AI coding agents including ClaudeCode and Cursor. Plus, native Obsidian support
- More than 92% on LoCoMo & LongMemEval benchmark
- Portable by default (local-first), with optional cloud sync for team collaboration and enterprise-grade security
Huge respect for Ashwin Gopinath for formalizing into a full paper https://t.co/gM8PQpWXnL. This is the kind of rigorous, formal analysis that moves the entire agent memory field forward.
If you’re building agents that need to actually remember long-term, check out this repo https://t.co/RpPq8ikSqP
Install the CLI: curl -fsSL <https://t.co/sXw88WYG58> | sh
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
@medinism Context is the moat and needs to be protected. Models will compete. Harnesses will multiply. But your knowledge is yours and shouldn’t be locked inside any single tool:
https://t.co/3zUvX6nbiG
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
@JayaGup10 The moat will always be your data. Models will compete. Harnesses will multiply. But your knowledge is yours and shouldn’t be locked inside any single tool: https://t.co/qjJVx91Cho
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
@prukalpa Context needs to be protected. Models will compete. Harnesses will multiply. But your knowledge is yours and shouldn’t be locked inside any single tool:
https://t.co/3zUvX6nbiG
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
@JayaGup10 It's clear. Context needs to be protected
Models will compete. Harnesses will multiply. But your knowledge is yours and shouldn’t be locked inside any single tool: https://t.co/3zUvX6nbiG
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading
@MatthewBerman I don't think its foolish. Sure some have a ton of capital but getting the best out of LLMs require different components. A computer analogy works as well: https://t.co/3zUvX6nbiG
CPU = LLM
OS = agent harness
RAM = context window
Files = your knowledge
Programs = your skills
I want to swap CPUs depending on the job
I want my files to outlive any OS
I want full control over who accesses my data
I don't want the company that makes my CPU or my OS to own my files
Your computer figured this out decades ago. AI agents haven't yet. I hope that's where we're heading