ML @snap for @spectacles, prev. @canva, building user-facing ML experiences that feel like magic ✨.
Interested in multimodality, VLMs, systems & MLOps.
📢 @evanspiegel (CEO, @Snap) is headlining #AWE2026
Join us June 16 for his keynote: "Making Computing More Human."
Plus, explore the latest in AI smartglasses, physical AI, and robotics.
⏳ Save $400. Early Bird ends May 7
🎫 https://t.co/K9bNbWoUlx
#AWE2026#XR#ISpatial
Today, we announced a multi-year strategic agreement with @Qualcomm to power future generations of @Spectacles with Snapdragon XR platforms.
https://t.co/RMQJi16kDd
Announcing FunctionGemma, a specialized version of our Gemma 3 270M model that’s fine-tuned for function calling ⚙️
The new release brings bespoke function calling to the edge, and is designed as a strong base for further training into custom, fast, private, local agents that translate natural language into executable API actions.
https://t.co/nkfZAKgBMm
Snapchat + @perplexity_ai 🤝
Starting in early 2026, you’ll be able to ask questions, explore new ideas, and get credible answers right inside chat.
AI that feels more personal, social, and fun! https://t.co/5J10blvzhR
Not all visual tokens are important. We present new work on efficient token selection driven by the text prompt in VLMs. We train a vision encoder in a CLIP-like setting with local/global contrastive loss. Once trained, the model can output a heatmap of interest given a text prompt. As a result, we achieve up to 4k x 4k working resolution in an efficient way.
In the paper (https://t.co/xTkmn1CIEz), we present:
• PS3: a method to scale CLIP-like models to 4k and above;
• PS3-SigLIP-SO400M and PS3-C-RADIO-v2-L ViT models;
• 4KPro: a benchmark for high-resolution VQA on 4k resolution for VLMs;
• VILA-HD: extending VLM to 4k resolution with 1.9-3x better efficiency than using all patches, with an accuracy gain of 3.2%.
@AniC_dev Really cool stuff! Any way now or in the future to export the logs or a natural language/structured summary of them to use as context e.g. for further questioning?
we just dropped SmolVLM2: world's smollest video models in 256M, 500M and 2.2B ⏯️🤗
we also release the following 🔥
> an iPhone app (runs on 500M model in MLX)
> integration with VLC for segmentation of descriptions (2.2B)
> a highlights extractor (2.2B)
So if you are typical ML researcher, you had this question for eternity:
"I want small, powerful model: Should we train large model and distill? Or should we train small model from scatch"
This new Apple papers conclusion:
Its complicated but maybe yes, depending on your budget.
1/n
Neat approach to more flexible and steerable token-based image-generation!
Seems to lead to noteworthy instruction- and task-level zero-shot capabilities https://t.co/kDtWCHDMkf
This project really changed how I think about multimodal models and LLMs. I used to believe that multimodal (visual) prediction required significant changes to the model and heavy pretraining, like Chameleon. But surprisingly, the opposite is true! In large autoregressive models, visual understanding and generation are closely linked and can be instruction-tuned directly from LLMs.
The LLM is there waiting for vision. [1/7]
Website: https://t.co/d35d5ZNGOf
Gemini 2.0 Flash has native image outputs! Congrats to the awesome team that built it.
I find the example at 1:15 super cool: to change the car's color and add beach gear, the model generates two images step-by-step using visual chain of thought.
https://t.co/zLl14JUEG1
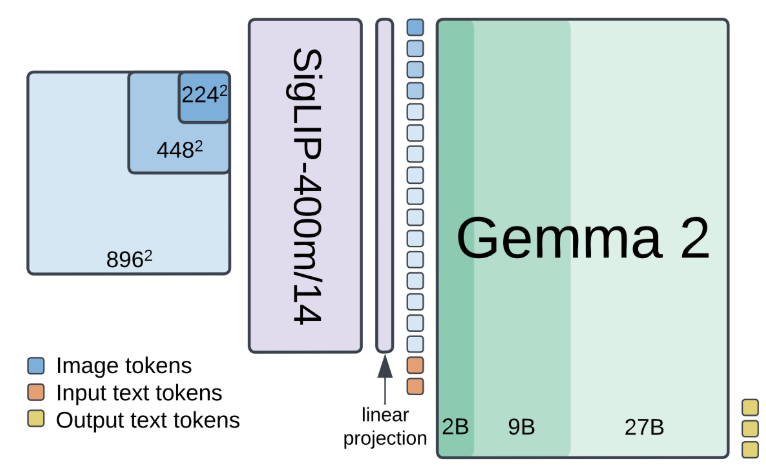
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
Understanding the inner workings of foundation models is key for unlocking their full potential.
While the research community has explored this for LLMs, CLIP, and text-to-image models, it's time to turn our focus to VLMs. Let's dive in! 🌟
https://t.co/NtTrkZ6iWh
Today we're sharing our first research update @theworldlabs -- a generative model of 3D worlds!
I'm super proud of what the team has achieved so far, and can't wait to see what comes next. Lifting GenAI to 3D will change the way we make media, from movies to games and more!
Truffle’s aesthetics are peak. Design that transcends utility and becomes ubiquitous furniture. Your goal should be to make movies that don’t feature your work look anachronistic. @iamgingertrash is on that path. An inspiration ⭐️⭐️⭐️⭐️⭐️
📢 Presenting our app for real-time zero-shot image classification using MobileCLIP!
Fully open-source—code & models available for everyone to explore. Check it out here: https://t.co/hg08zPJSZB
with - David Koski, Travis Trotto, Megan Maher Welsh & Hugues Thomas
𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding. https://t.co/LkkkSDWpJh (🧵)