Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: https://t.co/c3yfEewsWj
#LLM #RLHF #PostTraining #vLLM
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
KV cache shouldn't disappear every time vLLM restarts. With @novita_labs, we're sharing PegaFlow — a production-grade external KV cache service that plugs into vLLM through the external KV connector interface.
PegaFlow runs as a standalone Rust daemon owning the host KV pool, SSD cache, and RDMA resources. vLLM workers attach via CUDA IPC + gRPC, and cache survives engine crashes, upgrades, and model switches.
In production-oriented evaluations:
🚀 2.15× faster vLLM startup with a pre-warmed 500 GiB host pool
📈 56% higher throughput for 8 Qwen3-8B instances sharing one cache
⚡ 72% higher throughput for DeepSeek-V3.2 MLA TP8 (logical KV stored once, not per rank)
🌐 194 GB/s average remote-read throughput across nodes
Three-level hierarchy: pinned DRAM, remote DRAM over RDMA, local SSD on io_uring. Integrates through the existing `kv_transfer_config` path — no vLLM source changes.
📖 https://t.co/rf2VmevP7J
Everything AI released at Google I/O 2026
- Gemini Omni Flash
- Gemini 3.5 Flash (and in GA)
- Antigravity 2.0
- Managed Agents in the Gemini API
- AI Studio app in pre-order
- New SynthID partnerships
- AI Studio: native Android support, Workspace Integrations, and export to AGY
- Antigravity SDK and CLI
- Gemini Spark
- New Google AI Ultra subscription
And stay tuned, so much more to come!
Gemma 4 was released just a few weeks ago.
Since then, it has been downloaded over 50 million times and there are almost 1500 community-built models based on it. Exciting times ahead!
Today we’re releasing Laguna XS.2, Poolside’s first open-weight model.
It’s a 33B total / 3B active MoE model built for agentic coding and long-horizon tasks.
Trained fully in-house on our own stack. Runs on a single GPU. Released under Apache 2.0.
Links 👇
Weights: https://t.co/HSo8L2gM64
API: https://t.co/DMJtNFrace
Blog: https://t.co/BXEjQxtQoV
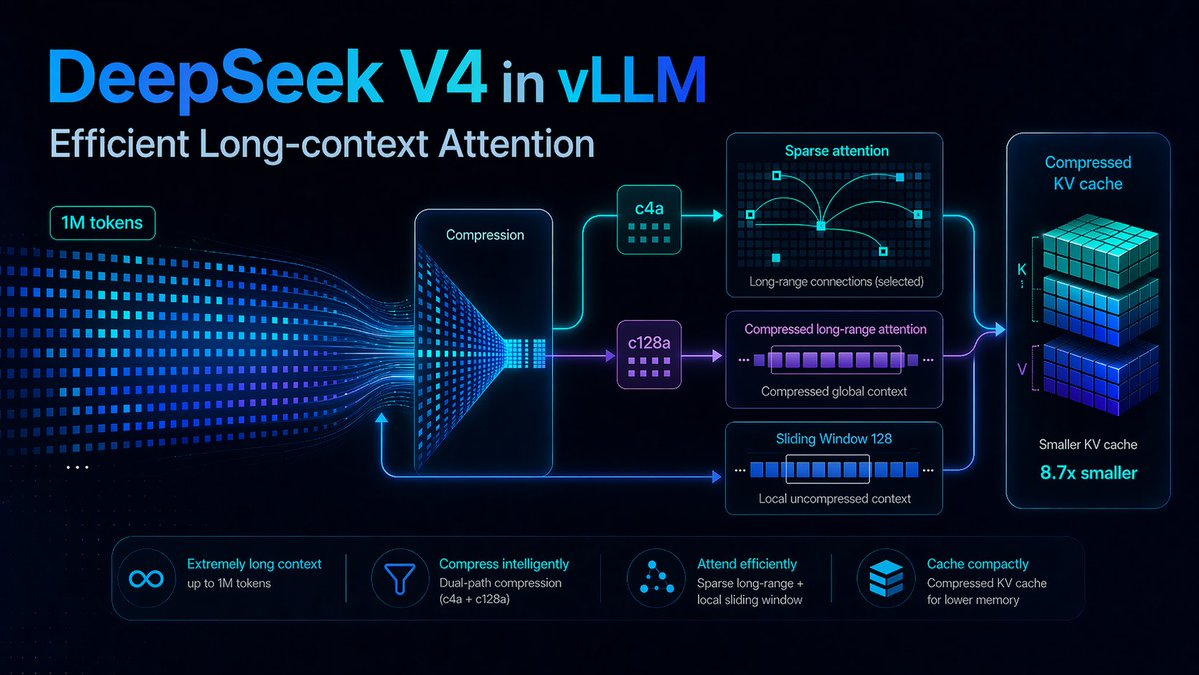
🎉 Day-0 support for @deepseek_ai V4 Pro and Flash on vLLM — a new generation of DeepSeek model, purpose-built for tasks up to 1M tokens. Alongside the release, we're publishing a first-principles walkthrough of the new long-context attention and how we implemented it in vLLM.
The new attention mechanism, in four moves:
• Shared K/V + inverse RoPE → 2× memory savings
• c4a / c128a KV compression → 4×–128× savings
• DeepSeek Sparse Attention over compressed tokens
• Short sliding window for locality across compression boundaries
At 1M context, per-layer KV state is ~8.7× smaller than a DeepSeek V3.2-style 61-layer stack (9.62 GiB vs 83.9 GiB, bf16). fp8 attention cache + fp4 indexer cache shrink it further.
vLLM side:
• Unified hybrid KV cache — single logical block size (256 native positions) across all compression rates; compressor state folded into the SWA KV cache spec so prefix caching, disagg prefill, CUDA graphs and MTP reuse the same abstraction
• Three page-size buckets for the full 5-way cache stack → no cross-kind fragmentation
• Fused kernels: compressor + RMSNorm + RoPE + cache insert (1.4–3×), inverse RoPE + fp8 quant (2–3×), Q-norm + KV RoPE + K insert (10–20×)
• Multi-stream overlap of indexer vs main-KV compression vs SWA insertion
Disaggregated serving is supported out of the box and strongly recommended for best performance.
Follow our recipes site for verified commands for @nvidia Blackwell (B200, B300, GB200, GB300) and Hopper (H100/H200/H20) systems.
Thanks to the @deepseek_ai team for open-sourcing DeepSeek V4, and to @inferact for landing day-0 support 🤝
📝 Blog: https://t.co/Eh7vk6xVJy
📖 Recipes: https://t.co/jlWuzYyZeX
🤗 https://t.co/IA9qAysqJk
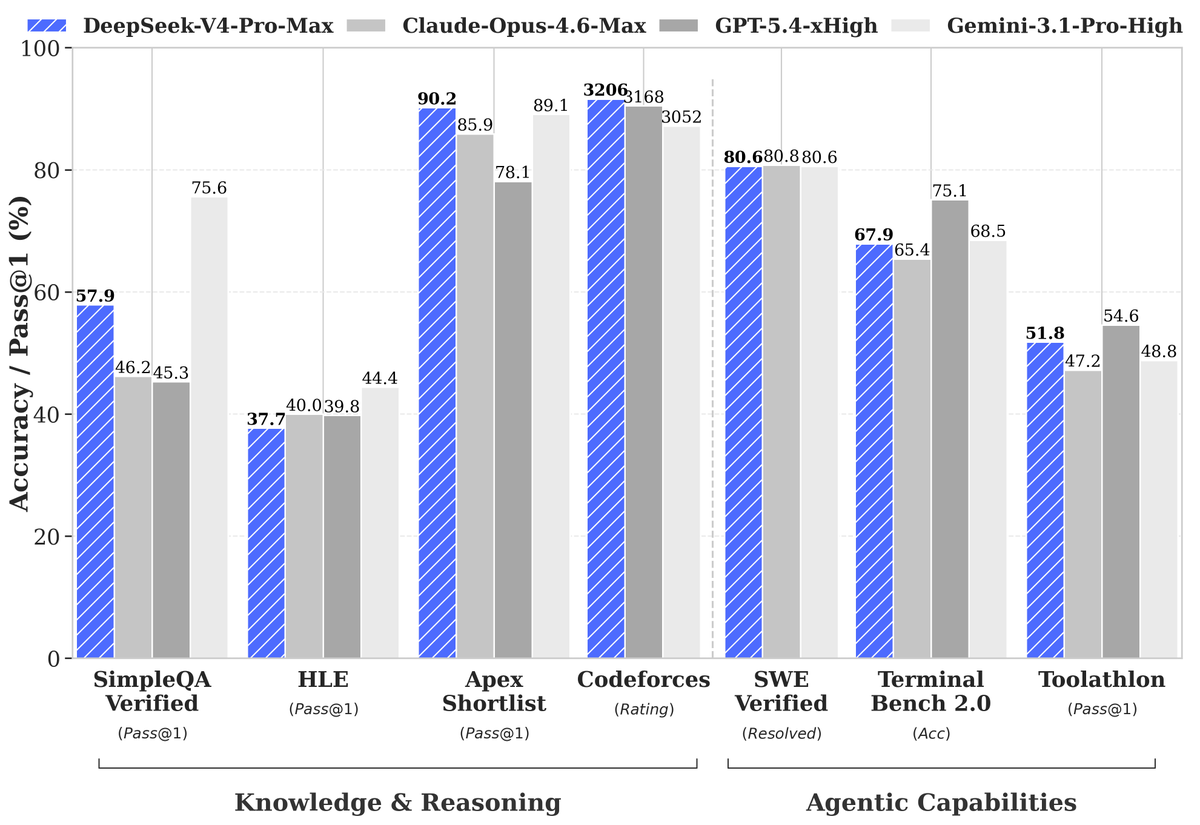
DeepSeek-V4-Pro
🔹 Enhanced Agentic Capabilities: Open-source SOTA in Agentic Coding benchmarks.
🔹 Rich World Knowledge: Leads all current open models, trailing only Gemini-3.1-Pro.
🔹 World-Class Reasoning: Beats all current open models in Math/STEM/Coding, rivaling top closed-source models.
2/n
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Qwen 3.6 27B model is available on Ollama!
Use it with all the integrations in Ollama or chat with the model.
Chat with the model:
ollama run qwen3.6:27b
OpenClaw:
ollama launch openclaw --model qwen3.6:27b
Claude Code:
ollama launch claude --model qwen3.6:27b
More 👇👇👇
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Next week we're doing a special Gemma meetup in San Francisco 💎
If you have built something with Gemma 4 and would like to showcase it in person, send me a DM!
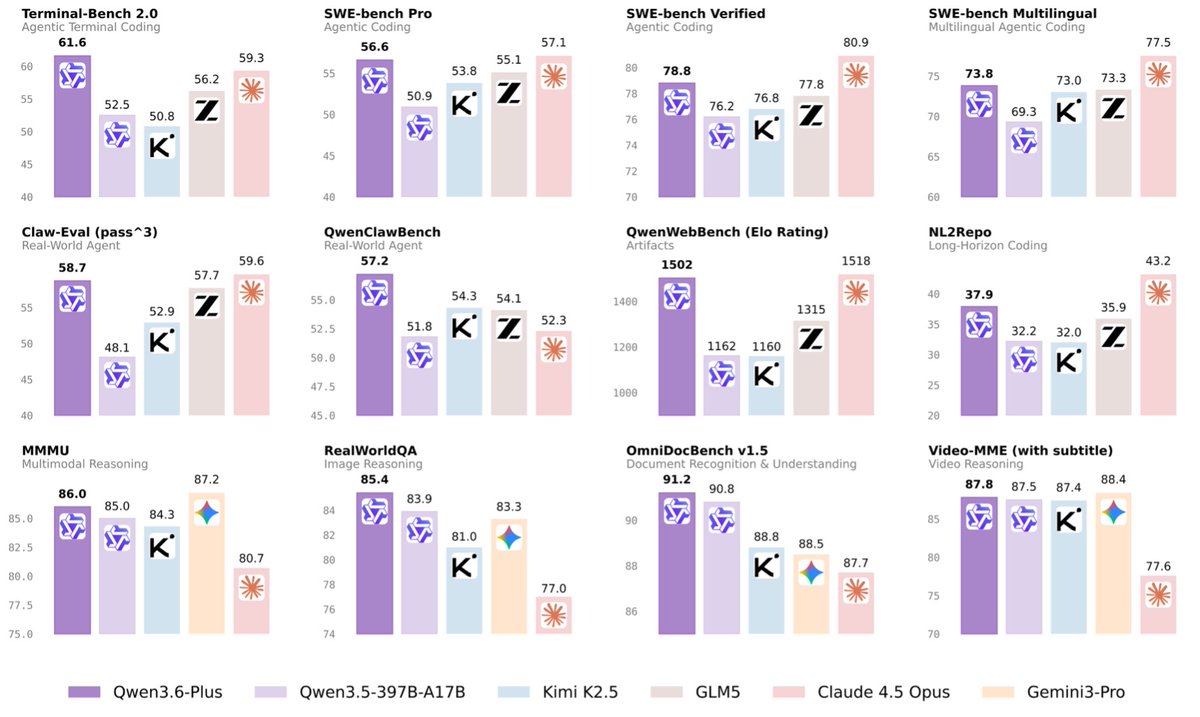
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️ Enhanced Multimodal Vision: Sharper perception & reasoning.
🏆 Top-tier Performance: Maintaining leading general capabilities.
📚 1M Context Window: Available by default via our API.
Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨.
Huge thanks to our community! Go try it out and show us what you can build. 👇
Chat: https://t.co/V7RmqMaVNZ
API: https://t.co/937Qkc9AMy
Blog: https://t.co/P0rJSxERND
🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents
We collaborated with @NVIDIA to teach you about Reinforcement Learning and RL environments.
Learn:
• Why RL environments matter + how to build them
• When RL is better than SFT
• GRPO and RL best practices
• How verifiable rewards and RLVR work
Blog: https://t.co/Jng3urMPyw
🎉 CUDA 13.2 just dropped, and GPU programming just got simpler.
This release expands CUDA Tile support to Ampere and Ada GPUs while delivering a stronger CUDA Python stack for cluster-scale workloads.
What's new:
✅ Install cuTile Python directly from PyPI: pip install cuda-tile
✅ Enhanced CUDA Python profiling and debugging across Numba-CUDA flows and Nsight tools
✅ Modern CUDA C++ and refreshed math libraries optimized for AI and HPC kernels
Ready to accelerate your workflows?
📝 Read the technical deep dive: https://t.co/pE5UcJZqXU
We rebuilt Next.js in a week. No, really.
The team ported the framework to run natively on Workers to prove what’s possible with edge-first architecture. Dive into the technical hurdles we solved to eliminate Node.js dependencies.
https://t.co/GqYBiZ5Qum