In @latentspacepod podcast, I shared my view on video generation, world models, LLMs, agents, continual learning and where the next frontier is.
1. Video models get most of their intelligence from language, not from video data.
2. Idea-to-code is fast now. The bottleneck is back to having enough compute to try every idea.
3. Iteration speed beats almost everything else in model development.
4. The next leap won't be a better video model. It'll be a video agent.
5. Diffusion will be the frontend of AGI, the LLM the backend. Generative UI will replace HTML/CSS: user intent straight to pixels.
6. Physical embodiment may become a tool a powerful AI picks up. Robotics may get solved by video-capable LLMs.
7. Continual learning may look like models that manage their own context, and even rewrite their own harness at test time.
Thanks @swyx and @vibhuuuus for having me 🙏
https://t.co/mLuvbODJxA
Today, at the @DARPA expMath kickoff, we launched 𝗢𝗽𝗲𝗻𝗚𝗮𝘂𝘀𝘀, an open source and state of the art autoformalization agent harness for developers and practitioners to accelerate progress at the frontier.
It is stronger, faster, and more cost-efficient than off-the-shelf alternatives. On FormalQualBench, running with a 4-hour timeout, it beats @HarmonicMath's Aristotle agent with no time limit.
Users of OpenGauss can interact with it as much or as little as they want, can easily manage many subagents working in parallel, and can extend / modify / introspect OpenGauss because it is permissively open-source. OpenGauss was developed in close collaboration with maintainers of leading open-source AI tooling for Lean.
Read the report and try it out:
On how implicitly or architecturally induced sparsity mitigates variance explosion from prenorm. Attention over depth is also a kind of architectural sparsity from this aspect.
Our co-founder Terence Tao is announcing SAIR Foundation's inaugural competition: the Mathematics Distillation Challenge.
Co-organized by @damekdavis, Terence Tao, and SAIR Foundation.
https://t.co/uuDizGTsVT
Say you have trained your deep learning model. It works. But do you know what it has actually learned?
🚀 We’ve built SymTorch: a library that translates deep learning models into human-readable equations.
I've attached here a quick video demonstrating how SymTorch works.
I ran experiments with GPT-5.2-Pro on 20 latest arXiv preprints to see if it can:
- independently prove the main theorem
- find big mistakes in papers
Statistics:
- 1 easy proof can be re-derived by GPT-5.2-Pro
- 1 contained a critical error
- 1 more case is quite interesting ⬇️
Recently I gave a talk on LLMs for Math Research (mostly to an audience of pure and applied mathematicians)
I tried to compile the latest progress in one presentation
pdf and video recording: https://t.co/Q5qvnEwAiE
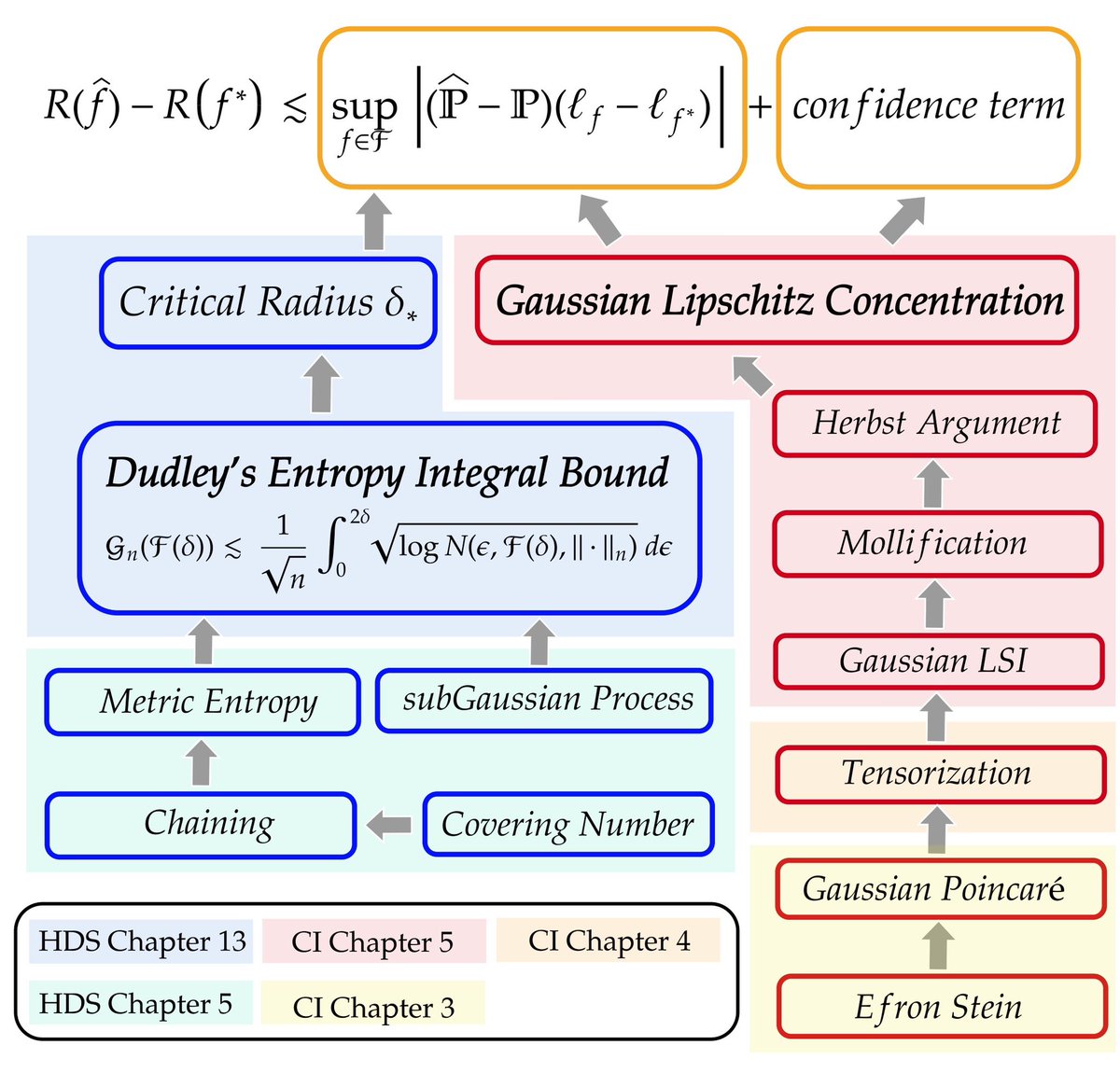
🚀 We present the first large-scale Lean 4 formulation of Statistical learning theory from scratch!
Led by my student @yuanhezhang6 and collaborated with @jasondeanlee
📄 Paper: https://t.co/8q5laY8KYp
💻 GitHub: https://t.co/mTpkr92TMQ
🤗 Dataset: https://t.co/K8wDD6us4k