🔥🔥Sácale todo el jugo a tu tarjeta gráfica🔥🔥. Aprende a entrenar tus modelos en haciendo uso de la precisión mixta.
#fp16#float16#mixedprecision
https://t.co/XANowvMLb8
Watch a team of humanoid robots running a full 8-hr shift at human performance levels. This is fully autonomous running Helix-02 https://t.co/bIgpYuaYCj
Si bien no podemos probar Mythos sí podemos darle validez al modelo a través de los rastros que van dejando quienes sí lo están utilizando.
En el blog "Suddenly, the bugs are very good" que ha compartido Mozilla se puede ver cómo, a través de los bugs identificados por Mythos y luego actualizando sus harness y con otras técnicas (se entiende que usando IA en cualquier caso), la cantidad de bugs identificados en abril rompe por completo la tendencia anterior.
"AI-generated security bug reports to open source projects were mostly known for being unwanted slop. [...] It is difficult to overstate how much this dynamic changed for us over a few short months."
Como es tendencia habitual en el mundo de la IA, desde Mozilla se sorprenden al ver cómo se ha pasado rápidamente de que la IA buscando bugs fuera puro slop (resultados plausibles pero de mala calidad que te quitaban tiempo de revisión) a de repente que esto funcionara muy bien.
Es interesante porque claramente ya podemos vislumbrar cómo la IA (en contra de lo que popularmente se ha dicho) sí va a ayudar mucho a volver más seguro a nuestros software, limpiándolos de bugs que llevan en el código décadas. Sin embargo, al mismo tiempo, esto nos coloca en un territorio más inseguro que antes, donde el que tenga acceso a los modelos más potentes, tendrá mayor capacidad de comprometer a los sistemas encontrando nuevos bugs desconocidos.
A la mínima que hayáis leído el análisis hecho por AISLE os daréis cuenta de que la crítica hecha aquí no tiene fundamento.
El motivo es que AISLE no ha reproducido realmente la tarea que Mythos ha resuelto (dejar que el LLM escanee proyectos completos hasta encontrar sin intervención humana las vulnerabilidades).
En el caso de AISLE se les ha dado como input al sistema las zonas de código más delicadas, ya conocidas previamente a través de los reports de Anthropic, para examinarlas con modelos menos potentes que sí han encontrado las vulnerabilidades que se esperaban. Es decir, no se está evaluando la capacidad de búsqueda real, sino la capacidad de análisis una vez el problema ya ha sido prácticamente aislado.
Y de ahí se ha saltado a concluir "los modelos menos potentes hacen la misma labor que Mythos", lo cuál es erróneo.
Por hacer una analogía sería como si a mi me ponen a buscar una aguja en un pajar y la encuentro tras mucho trabajo duro. Mientras que a otra persona le señalan la aguja entre toda la paja y le preguntan ¿es aguja o es paja? y al acertar concluyen que nuestras capacidades son iguales.
--
Soy el primero que cree (opinión) que Anthropic no saca a Mythos no por miedo, sino por falta de computación para poder desplegarlo. Lo dije en mi vídeo y ya lo dije incluso cuando surgieron las primeras filtraciones hace unas semanas.
Pero eso no es incompatible con que el modelo sí representa un salto en capacidades inesperado, al menos por lo visto sobre el papel. Y que gran parte de la gente que trabaja en Anthropic sí se toma muy enserio los riesgos tras estos modelos (en algunos puntos rozando una paranoia exagerada, a mi gusto).
Reducirlo todo a "lo hacen porque marketing, porque IPO, porque dinero, porque 2019..." es hacer una sobre-simplificación de la situación que minimiza riesgos reales de desplegar este tipo de modelos al públicos.
Por ejemplo, argumentar que porque "George Hotz (hacker famoso) dice que es capaz de encontrar 0days con facilidad, porque no es tan difícil pero que no hay incentivos para buscarlos, y que por tanto lo de la IA no es tan impresionante", es mover el foco de donde está el problema. Es el equivalente a decir que los deepfakes no son un problema porque ya los profesionales de efectos especiales antes lo hacían con software de FX. El problema no es de capacidad sino de escala. Antes sólo unos pocos podían hacer eso y hoy en día con la IA y muy pocos recursos, cualquiera podrá hacerlo. La democratización de estas capacidades es "el problema" al que nos enfrentamos con una incertidumbre total. Quizá no pase nada. Quizá estemos jodidos. O quizá sea algo intermedio.
Ya os digo. A día de hoy si yo fuera el líder de una de estas empresas no tendría claro cuál sería la decisión más acertada a la hora de desplegar este tipo de modelos cada vez más potentes en abierto al público.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: https://t.co/hmyDe4Nel3
Weights: https://t.co/CuUjXcPKJD
API: https://t.co/fz6reja4fb
Coding Plan: https://t.co/Nk8Y98HNhU
Coming to https://t.co/WCqWT0qCQb in the next few days.
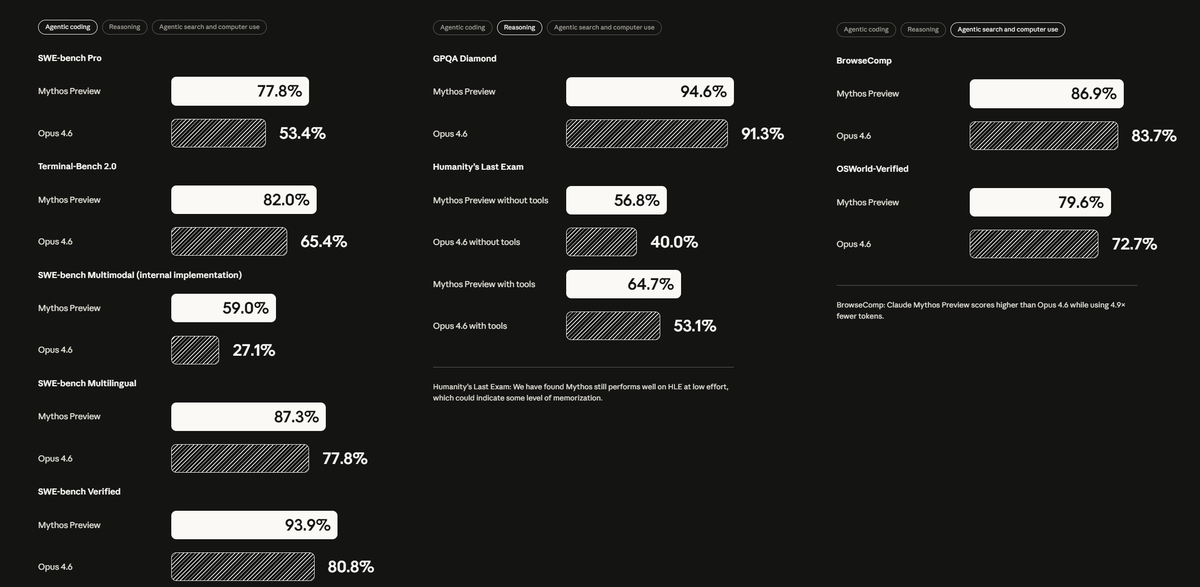
🔴 ¡ANTHROPIC MYTHOS PREVIEW!
Anthropic acaba de publicar lo que serían los primeros benchmarks de su "filtrado" gran próximo modelo, Mythos.
La verdad es que en programación y razonamiento el salto es BESTIA!
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
PSA: If you've been running out of Claude session quotas on Max tier, you're not alone. Read this.
Some insane Redditor reverse engineered the Claude binaries with MITM to find 2 bugs that could have caused cache-invalidation. Tokens that aren't cached are 10x-20x more expensive and are killing your quota.
If you're using your API keys with Claude this is even worse. This is also likely why this isn't uniform, while over 500 folks replied to me and said "me too", many (including me) didn't see this issue.
There are 2 issues that are compounded here (per Redditor, I haven't independently confirmed this) :
1s bug he found is a string replacement bug in bun that invalidates cache. Apparently this has to do with the custom @bunjavascript binary that ships with standalone Claude CLI.
The workaround there is to use Claude with `npx @anthropic-ai/claude-code`
2nd bug is worse, he claims that --resume always breaks cache. And there doesn't seem to be a workaround there, except pinning to a very old version (that will miss on tons of features)
This bug is also documented on Github and confirmed by other folks.
I won't entertain the conspiracy theories there that Anthropic "chooses" to ignore these bugs because it gets them more $$$, they are actively benefiting from everyone hitting as much cached tokens as possible, so this is absolutely a great find and it does align with my thoughts earlier.
The very sudden spike in reporting for this, the non-uniform nature (some folks are completely fine, some folks are hitting quotas after saying "hey") definitely points to a bug.
cc @trq212@bcherny@_catwu for visibility in case this helps all of us.
Computer use is now in Claude Code.
Claude can open your apps, click through your UI, and test what it built, right from the CLI.
Now in research preview on Pro and Max plans.
AI can make work faster, but a fear is that relying on it may make it harder to learn new skills on the job.
We ran an experiment with software engineers to learn more. Coding with AI led to a decrease in mastery—but this depended on how people used it.
https://t.co/lbxgP11I4I
🚨 CLAWDBOT
¿Qué es? ¿Por qué ABSOLUTAMENTE todo internet está como loco usándolo? ¿Cómo no quedarte atrás y comenzar a usarlo/instalarlo? Te cuento 👇
Nunca en mi vida había visto el nivel de aceptación de un proyecto tan brutal y rápido. En días: miles de stars en GitHub, Discord con miles de miembros activos, PRs diarios, gente comprando Mac Minis solo para correrlo, VPS explotando... y eso que solo tiene 3 semanas de vida. LOCURA MÁXIMA.
1/ ¿Qué es Clawdbot?
Es un asistente personal self-hosted que vive donde tú ya hablas: Telegram, WhatsApp, Slack, Discord, Signal… (y más). Y encima es TUYO:
• corre en tu máquina
• con tus reglas
• con tus integraciones
• con memoria/persistencia
• y puede hacer cosas, no solo responder texto
2/ ¿Qué hace que esté explotando?
Porque junta 4 cosas que la gente llevaba años necesitando sin saberlo y ninguno de los grandes (OpenAI, Claude, Grok, etc) ha ofrecido porque son unos f*cking panzas (lo hubieran podido hacer chasqueando los dedos, pero ha tenido que venir UNA SOLA PERSONA avispada a crearlo):
• Siempre disponible (en tu móvil, en tu escritorio, en tu chat de siempre)
• Persistente (no "olvida" cada 5 minutos, va construyendo contexto)
• Acciones reales (automatiza, integra, dispara workflows)
• Open source (la comunidad lo puede llevar a otro nivel)
POR FIN, la sensación de: "vale, ahora sí tengo un copiloto 24/7".
3/ Cómo instalarlo en 2 minutos (la ruta fácil):
a) Abre terminal (Mac/Linux/Windows).
b) Pega este one-liner mágico:
curl -fsSL https://t.co/NPj7XuP01t | bash
(Instala Node.js + todo automático).
c) Sigue el wizard: configura Gmail, Claude API, WhatsApp/Telegram bot, etc. (te guía paso a paso).
d) ¡Listo! Prueba enviando un mensaje a tu bot: "Clawdbot, limpia mi inbox y resume mis emails pendientes".
¡VAMOS!
¿Se te ha quedado corto esta explicación Pues espera que viene LA BIBLIBA👇
AI efficiency is important. Today, Google is sharing a technical paper detailing our comprehensive methodology for measuring the environmental impact of Gemini inference. We estimate that the median Gemini Apps text prompt uses 0.24 watt-hours of energy (equivalent to watching an average TV for ~nine seconds), and consumes 0.26 milliliters of water (about five drops) — figures that are substantially lower than many public estimates.
At the same time, our AI systems are becoming more efficient through research innovations and software and hardware efficiency improvements. From May 2024 to May 2025, the energy footprint of the median Gemini Apps text prompt dropped by 33x, and the total carbon footprint dropped by 44x, through a combination of model efficiency improvements, machine utilization improvements and additional clean energy procurement, all while delivering higher quality responses.
See the blog or technical paper for more about our methodology and ongoing efforts.
Blog:
https://t.co/CoMm5gV9SR
Link to detailed paper: https://t.co/UBi9rd6gEC
Si estuviste conmigo cuando salió GPT-2, obviamente 5 años más tarde estaremos juntos con la salida de GPT-5 🔥
Comparte el tweet de arriba para mayor difusión!
someday soon something smarter than the smartest person you know will be running on a device in your pocket, helping you with whatever you want.
this is a very remarkable thing.
🔴 ¡GOOGLE PRESENTA GENIE 3!
Una nueva evolución de su proyecto GENIE de generación de vídeo interactivos en tiempo real, ahora con una calidad más cercana a las IAs de generación de vídeo podían generar hace 6 meses 🤯
Os enseño varios ejemplos! 👇🧵
https://t.co/ULT6mw6yau
🔴 AVATARES ARTIFICIALES más EXPRESIVOS!
La industria de los avatares artificiales va a golpear fuerte en 2024 cuando se sobrevuele el valle inquietante tanto en voz como realismo de las expresiones.
Y Synthesia parece volver a la carga con EXPRESS-1 🔥
https://t.co/lGdqU6j5HB
🔴 ¡LLAMA 3 YA ESTÁ AQUÍ!
De la compañía que emocionó a la comunidad open source e inició una revolución de los LLMs en abierto, llega hoy el nuevo regalo de Meta 🦙
Voy leyendo la info, y desarrollo el hilo 🧵👇
🔴 ¡GENERACIÓN de VÍDEO de ADOBE!
Adobe sigue adaptándose a la transformación de su negocio, donde la IA en cloud sigue comiéndose sus propios productos. Hoy, presentando integraciones de generación de vídeo, y ojo...!
La primera aparición de SORA en un producto! 😱🧵
























![DotCSV's tweet photo. Si bien no podemos probar Mythos sí podemos darle validez al modelo a través de los rastros que van dejando quienes sí lo están utilizando.
En el blog "Suddenly, the bugs are very good" que ha compartido Mozilla se puede ver cómo, a través de los bugs identificados por Mythos y luego actualizando sus harness y con otras técnicas (se entiende que usando IA en cualquier caso), la cantidad de bugs identificados en abril rompe por completo la tendencia anterior.
"AI-generated security bug reports to open source projects were mostly known for being unwanted slop. [...] It is difficult to overstate how much this dynamic changed for us over a few short months."
Como es tendencia habitual en el mundo de la IA, desde Mozilla se sorprenden al ver cómo se ha pasado rápidamente de que la IA buscando bugs fuera puro slop (resultados plausibles pero de mala calidad que te quitaban tiempo de revisión) a de repente que esto funcionara muy bien.
Es interesante porque claramente ya podemos vislumbrar cómo la IA (en contra de lo que popularmente se ha dicho) sí va a ayudar mucho a volver más seguro a nuestros software, limpiándolos de bugs que llevan en el código décadas. Sin embargo, al mismo tiempo, esto nos coloca en un territorio más inseguro que antes, donde el que tenga acceso a los modelos más potentes, tendrá mayor capacidad de comprometer a los sistemas encontrando nuevos bugs desconocidos.](https://pbs.twimg.com/media/HHyN-HKWAAUeUzN.jpg)