Our paper was nominated in the Best Paper Finalist of #ECCV2024. I sincerely thank all co-authors. Our work was also reported by Georgia Tech @ICatGT . My advisor @RehgJim will present it on Oct 2 1:30pm at Oral 4B Session, and Oct 2 4:30pm at #240 of Poster Session.@eccvconf
LEGO can show you how it's done! New @eccvconf work from @bryanislucky, a new generative tool can produce visual images to accompany step-by-step instructions with just a single first-person photo uploaded into the prompt. #wecandothat🐝 @GTResearchNews
https://t.co/SYafClSFng
@RehgJim@IrohXu@zixuan_huang@Wenqi_Jia@fionakryan@siebelschool@uofigrainger Thank you! A bit more details for my few-shot image editing paper. Our model can learn a new image editing operation from textual and visual guidance via in-context learning, and apply it to new query images.
Please check our webpage for code and videos: https://t.co/duJP8j3cZ3
Howdy from Nashville, ya'll! 🎸🤠
Check out our stars at #CVPR2025, a top @IEEEorg research venue for computer vision experts presenting their work on how computers interpret the world using image and video data!
Tech’s experts will take center stage this week at @CVPR at the Music City Center to share their breakthroughs in computer vision. @GeorgiaTech is in the top 10% of all organizations for first authors and the top 4% for number of papers. More than 2000 organizations have research accepted into the main program.
Tech's first authors include Chengyue Huang, Bolin Lai, Fiona Ryan, Andrew Szot, Lifu Wang, Lex Whalen, and Haoran You. @ICatGT faculty represent the majority of faculty in the papers program. Yeehaw!
Meet all of our experts now 🔗: https://t.co/2m2V2Qatda
#GTComputing #TogetherWeCompute #ChangeTheGame
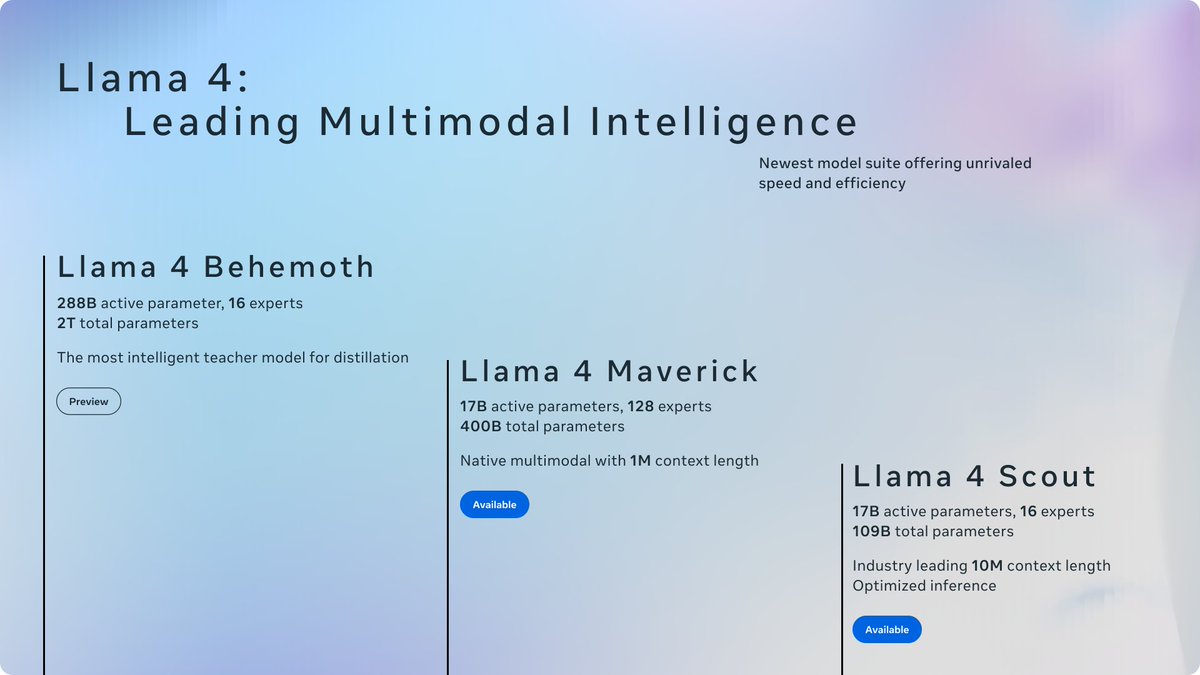
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ https://t.co/9G3QgVdCkB
Download Llama 4 ➡️ https://t.co/eVomRvEr0w
💻The work was done at GenAI Meta. Thank all collaborators at Meta and my advisor @RehgJim for their strong support.🍻 [8/8]
📄Paper: https://t.co/GezWv3GRtO
⌨️Code: https://t.co/8Paxa2axRx
���️Video: https://t.co/cCv6MUeJbr
📢#CVPR2025 Introducing InstaManip, a novel multimodal autoregressive model for few-shot image editing.
🎯InstaManip can learn a new image editing operation from textual and visual guidance via in-context learning, and apply it to new query images. [1/8]
https://t.co/duJP8j3KOB
🔎In addition, when different exemplar image pairs are used with the same textual instruction, InstaManip can capture the different visual patterns and apply them in editing query images. [7/8]
Alibaba just dropped Wan2.1
open AI Video Generation
#1 on VBench leaderboard, outperforming SOTA open-source & commercial models
Mastery in complex motion dynamics & physics simulation & text rendering
My paper RelCon: Relative Contrastive Learning for a Motion Foundation Model for Wearable Data, from my @Apple internship, has been accepted at #ICLR2025! 🎉
We introduce the first IMU foundation model, unlocking generalization across motion tasks. 🏃♀️📊
https://t.co/BGVzFjSjxn
Introducing Gaze-LLE, a new model for gaze target estimation built on top of a frozen visual foundation model!
Gaze-LLE achieves SOTA results on multiple benchmarks while learning minimal parameters, and shows strong generalization
paper: https://t.co/Is2NgrrurO
#ECCV2024 has honored this computer vision research as one of 15 Best Paper Award candidates 🎉! Congrats to the team and lead author Bolin Lai, PhD student in Machine Learning at @GeorgiaTech.
























![bryanislucky's tweet photo. 🔎In addition, when different exemplar image pairs are used with the same textual instruction, InstaManip can capture the different visual patterns and apply them in editing query images. [7/8] https://t.co/tyfI4xfkvI](https://pbs.twimg.com/media/GneOdM1XgAAEk4x.jpg)






























