Andrej Karpathy spent 4 minutes in an interview explaining a single idea
about how most people haven’t even started learning how to use AI
and everyone paying $20/month for a subscription.. that's not really using Claude at all
his point is that the real skill gap is the ability to build with AI
he identified 4 behaviors that break Claude Code and put them all into one file
a developer expanded it into 21 rules and published it - 82,000 stars and #1 on GitHub Trending
coding accuracy jumped from 65% to 94%
here's what these 21 rules actually are and why most developers using Claude every day have never configured them
the full breakdown is covered in the article below 👇
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
🚨 INSTEAD OF WATCHING NETFLIX TONIGHT.
Spend 1 hour with this.
Obsidian + Claude Code = 24/7 personal operating system.
Works while you sleep.
The people who build this tonight will never work the same way again.
Watch it and Bookmark it now.
BREAKING:
🇨🇳 China just took the most aggressive diplomatic position in decades.
Xi Jinping on CCTV 13:
"If the world is to be saved from a third world war, Israel and the United States must be disarmed of nuclear weapons."
China arms Iran. Dumps U.S. Treasuries. Buys discounted Iranian oil.
Now demands U.S. nuclear disarmament.
This is a direct challenge to U.S. global dominance.
I want to see such indian content creators being celebrated, way more than we do.
What an awesome way to remember formulas: Bam Bam Bhole , Sona Chandi Tole 🤩
wrote an article breaking down the math behind TurboQuant by @GoogleResearch.
I walk through a toy example using concrete numbers to show every single operation that goes on under the hood.
link below:
Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
GitHub Repo: https://t.co/xgUdqncyRH
This 2 hour Stanford lecture on AI careers will teach you more about winning in the AI race than every piece of AI content you have scrolled past this year.
Bookmark this & give it 2 hours, no matter what. It'll be the most productive thing you could do this weekend.
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Stop burning tokens on Claude Code.
Use this instead 👇
A free GitHub repo (80K⭐) that turns your CLI into a high-performance AI coding system.
Link → https://t.co/h0lbndmbT1
Why it’s different:
→ Token optimization
Smart model selection + lean prompts = lower cost
→ Memory persistence
Auto-save/load context across sessions
(No more losing the thread)
→ Continuous learning
Turns past work into reusable skills
→ Verification loops
Built-in evals so code actually works
→ Subagent orchestration
Tames large codebases with iterative retrieval
Most people think Claude struggles with complex repos.
It doesn’t.
They’re just using the wrong setup.
This fixes it.
Bookmark this for your AI stack. ♻️
#AI #Claude #AIAgents #LLM #GenAI #DevTools
We are also releasing self-contained lecture notes that explain flow matching and diffusion models from scratch. This goes from "zero" to the state-of-the-art in modern Generative AI.
📖 Read the notes here: https://t.co/RULWDgn9pm
Joint work with @EErives40101.
Jensen Huang: "If that $500,000 engineer did not consume at least $250,000 worth of tokens, I am going to be deeply alarmed. This is no different than a chip designer who says 'I'm just going to use paper and pencil. I don't think I'm going to need any CAD tools.'"
🤯holy shit...someone just dropped the open-source version of Stripe/Ramp-level AI coding agents.
this isn’t a demo. this is the actual internal architecture.
→ agents that run in isolated cloud sandboxes
→ full repo + issue context injected
→ spawn subagents to work in parallel
→ fix code, run tests, commit changes
→ open PRs automatically
trigger it from Slack, Linear, or GitHub… and it just works.
no prompt babysitting. no fragile workflows. just autonomous execution.
this is what “AI engineer” actually means in 2026.
repo in comments 👇
You can now run ElevenLabs-level voice cloning completely offline 🤯
LuxTTS is a local TTS model that clones voices from 3 seconds of audio at insane speeds. It runs at 150x real-time without you ever having to pay a subscription.
- Works perfectly on both CPU and GPU
- Takes up just 1GB of VRAM
- Outputs crisp 48kHz audio instead of standard 24kHz
100% Open Source.
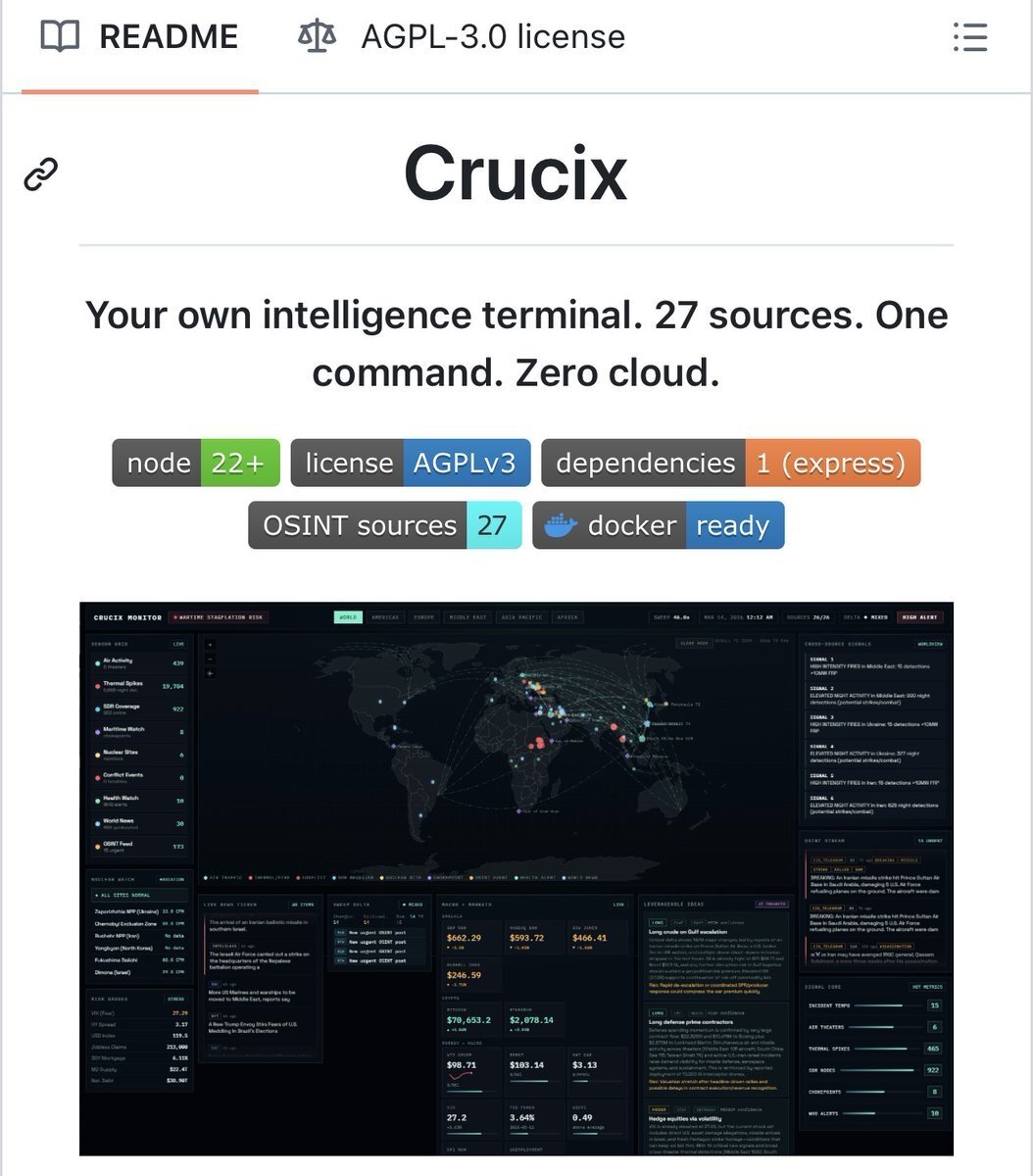
Someone just open-sourced a global intelligence system.
The kind governments spend millions building.
Yes, seriously.
Meet Crucix.
An always-on intelligence system that watches the world…
and texts you when something actually matters.
Every 15 minutes, it scans 26 live data streams and fuses them into a single Jarvis-style command center.
Here’s what it’s tracking in real-time:
→ NASA satellite fire detection
→ Fed economic signals
→ Markets: crypto, oil, commodities
→ Sanctions + watchlists
→ Maritime vessel tracking
→ Global news via GDELT + RSS
→ Global flight movement
→ Radiation levels
→ Conflict zone activity
→ Sentiment from 17 Telegram intel channels
Now the wild part:
It’s not just passive, it talks back.
Ping it on Telegram or Discord:
→ /brief → get a full intelligence rundown
→ /sweep → trigger a fresh global scan
It responds like an analyst on demand.
The kind of system usually locked behind six-figure government contracts…
…just got open-sourced.
MIT licensed.
This is really cool.
It got me thinking more deeply about personalized RL: what’s the real point of personalizing a model in a world where base models can become obsolete so quickly?
The reality in AI is that new models ship every few weeks, each better than the last. And the pace is only accelerating, as we see on the Hugging Face Hub. We are not far away from better base models dropping daily.
There’s a research gap in RL here that almost no one is working on. Most LLM personalization research assumes a fixed base model, but very few ask what happens to that personalization when you swap the base model. Think about going from Llama 3 to Llama 4. All the tuned preferences, reward signals, and LoRAs are suddenly tied to yesterday’s model.
As a user or a team, you don’t want to reteach every new model your preferences. But you also don’t want to be stuck on an older one just because it knows you.
We could call this "RL model transferability": how can an RL trace, a reward signal, or a preference representation trained on model N be distilled, stored, and automatically reapplied to model N+1 without too much user involvement? We solved that in SFT where a training dataset can be stored and reused to train a future model. We also tackled a version of that in RLHF phases somehow but it remain unclear more generally when using RL deployed in the real world.
There are some related threads (RLTR for transferable reasoning traces, P-RLHF and PREMIUM for model-agnostic user representations, HCP for portable preference protocols) but the full loop seems under-studied to me.
Some of these questions are about off-policy but other are about capabilities versus personalization: which of the old customizations/fixes does the new model already handle out of the box, and which ones are actually user/team-specific to ever be solved by default? That you would store in a skill for now but that RL allow to extend beyond the written guidance level.
I have surely missed some work so please post any good work you’ve seen on this topic in the comments.
🚨 Anthropic dropped a FREE 33-page playbook revealing Claude's very own cheat code:
The 'Skills' folder.
Spend 30 minutes building it,
and you’ll never have to explain your process again.
Top-tier users don't just type commands, they build systems.
Grab your free copy of Anthropic's official guide to building Claude skills right here: https://t.co/giATfp8BZw
























![techNmak's tweet photo. Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
GitHub Repo: https://t.co/xgUdqncyRH](https://pbs.twimg.com/media/HFC1ZQbaYAE9qoA.jpg)