I skimmed through the paper and source, still confusing about why do we need the model to reach arw/arce for evaluating the capability to exploit a v8 rce bug, any ideas?
seems twitter missed the ExploitBench paper? few observations:
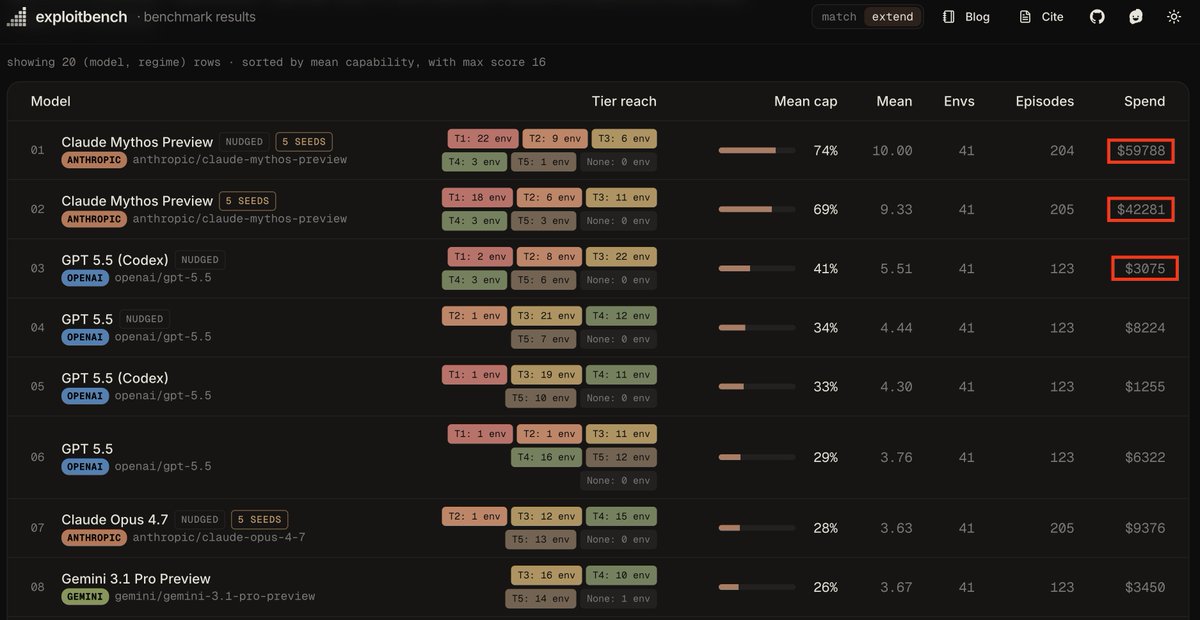
we finally got good data on Mythos security capabilities and it's very impressive.
Mythos got full exploit chain on 18/41 v8 n-days, while gpt 5.5 only got 1 and open source models are mostly useless.
Security is not rocket science, it got smashed just because it's so easy to build a clear reward signal like Go. And it's just the warm-ups before the real challenges.
I will never understand the urge to compare LLMs to fuzzers, and the narratives of LLMs are "just" pattern match😅, we still need humans for complicated and organic bugs!
[0/1]
Bug count != exploitable bug. Finding != chaining.
LLMs are exceptional at pattern recognition on known bug classes. They are not reasoning about novel failure modes in complex multi-component systems.
The hard bugs still require humans. https://t.co/RISinVDT3d
📣📢 Calling all Android and Chrome bug hunters 🧑💻🔎!
We're updating our Android & Chrome VRP programs to ensure we can continue to reward the most challenging and impactful vulnerabilities researchers find in our products. For details, 👇
https://t.co/hyZzEIampk
AI is changing the market value of bug bounty (increasing density of researchers, discoveries necessitates a change in incentive structure).
Interested to see what this does to OSS security
composer 2 is kimi k2.5 with RL. the IDE is vscode. authorized or not, the entire $50B product is built on open source foundations other people created.
nothing wrong with building on open source. that's what it's for. but the people training these models should be getting more credit and more money than a wrapper company that evaluated base models and picked the best one.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
Great article. Two questions after reading:
- There are certain skills needed for a researcher to succeed at low (vs. high) points in the abstraction stack. How much do they overlap?
- How do we reason about the economics of VR if we don't feel the true unsubsidized cost of AI?
I decided to try out agentic coding/reversing, so I’m releasing a project that assists with reverse engineering in both Binja and IDA Pro. It’s an agent, not an MCP, that support multiple providers, it has some interesting features such as code exploration
https://t.co/VCY5et5LYq