Bitcoin will very likely remain in a bear market, despite short-term countertrend rallies.
The hardest part of midterm years is just not believing in every single rally.
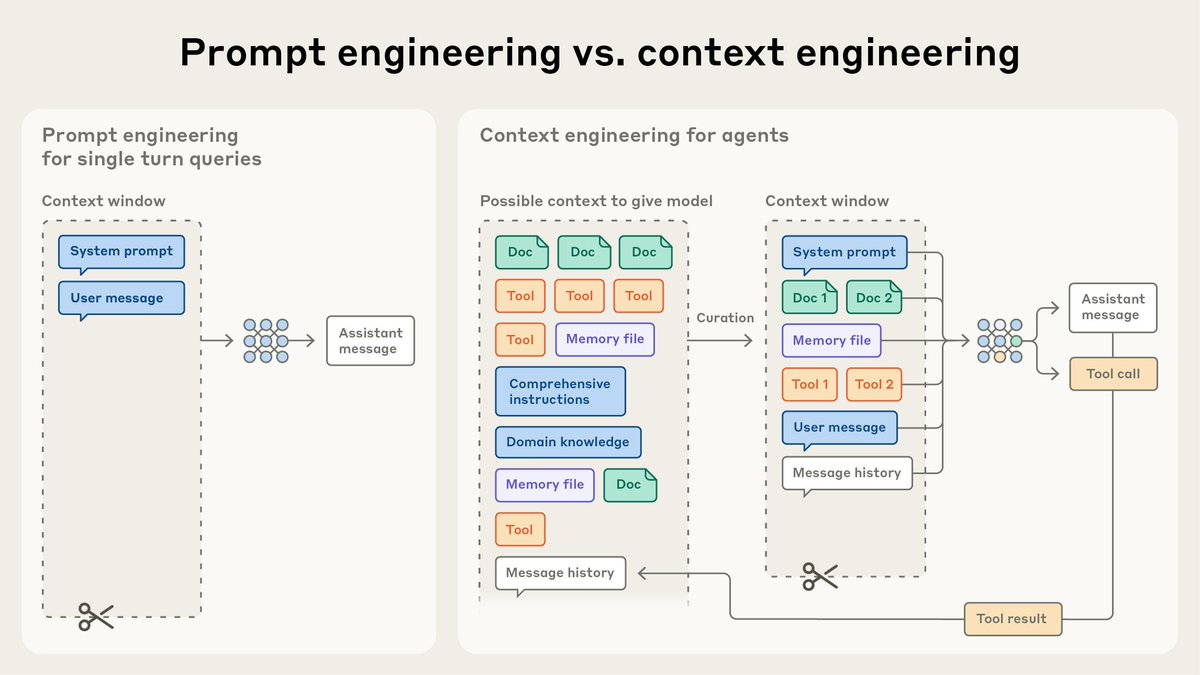
I just read how Anthropic's own engineers actually use Claude internally.
They don't prompt engineer. They context engineer. And the difference broke my brain.
Most people are still obsessing over the perfect phrasing. The magic sentence that makes Claude finally understand them.
That's not the problem.
The problem is what you're putting around the prompt.
Here's what Anthropic's own team actually does:
→ Just-in-time retrieval
Don't load everything upfront. Pull data dynamically using tools when the model actually needs it.
Claude Code does this brilliantly. It uses grep, head, and tail to analyze codebases without ever loading full files into context. The model stays sharp because it's never drowning.
→ Compaction
When you hit context limits, summarize the conversation. Keep architectural decisions. Discard redundant tool outputs. Maintain continuity without the bloat.
Most people just start a new chat. That's not the fix. Smart compression is.
→ Structured note-taking
Have the model write persistent notes outside the context window. Pull them back only when needed.
Think of it as your AI keeping its own NOTES.md file. It remembers what matters without wasting attention on what doesn't.
→ Sub-agent architectures
Specialized agents handle focused tasks and return compressed 2k token summaries instead of raw 50k token explorations.
Separation of concerns at the AI level. Same principle that makes engineering teams work.
Here's why this matters:
LLMs have an attention budget. The transformer architecture creates n² relationships between tokens. Every token you add depletes focus exponentially.
Stuffing your AI with information isn't thoroughness. It's noise.
Anthropic calls the result "context rot." More context, worse performance. The relationship is real and it compounds fast.
The shift in thinking is everything:
Before: "How do I write the perfect prompt?"
After: "What's the minimal high-signal context that drives my desired outcome?"
The best AI engineers aren't prompt wizards anymore.
They're context architects.
> be Anthropic
> lost the $200M Pentagon contract to OpenAI
> climbed to #1 on the App Store anyway
> ChatGPT uninstalls surged by 295%
> shipped “Memory”to pull chatgpt users over.
🚨🚨🚨BREAKING: Apple has officially chosen Google’s Gemini to power Apple Intelligence
“After careful evaluation, we determined that Google's technology provides the most capable foundation for Apple Foundation Models”
it’s so fucking over for @sama
If you go back and read about Tulip mania in 1637 you realize that the bubble was not in fact caused by irrational exuberance as historians have claimed, it was actually Wintermute
A few security tips
• Don't deposit over 10% of your net worth in one dApp
• Always verify the yield source
• Keep your funds in multiple wallets
I was also affected by yesterday's events.
If there's one thing to be learned, that is to prioritise survival over making money
This week, two U.S. coding assistants—Cursor and Windsurf—were caught running on Chinese foundation models. Cursor’s “Composer” speaks Chinese when it thinks. Windsurf’s “SWE-1.5” traces back to Zhipu AI’s GLM.
The real story here isn’t deception. Training foundation models from scratch costs tens of millions. Fine-tuning open-source models is the rational path. And Chinese models are now the best option.
Qwen leads global downloads on Hugging Face. Chinese models dominate trending charts. Third-party benchmarks show they match or beat Western alternatives on reasoning and speed.
Silicon Valley has spent years worrying about China “catching up” in AI. That framing is obsolete. Chinese open-source models aren’t just competitive—they’re infrastructure. Western developers build on them because they work, they’re free, and they’re good enough.
The global AI stack is converging. Right now, much of it runs on code from Beijing.
The setup is classic, fear maxed out, headlines bearish, everyone convinced the top’s in and meanwhile, macro data quietly flips bullish. This is how rallies always start.
Amazing that all the Chinese hotels, big chains or small family hotels, I have stayed in the past months provide free laundry services for guests. It was not the case more than a decade ago and certainly not the case in most hotels from the U.S. to Europe. Is it a result of this JUAN 卷 (excessive competition) culture. It’s great to use it after a long drive tour.
In the past, when a CEO needed air cover for layoffs or a strategy change, they’d hire McKinsey to tell them what they already knew and then point to the “consultants”.
Now they will point to “AI”, but it’s equally untrue.
So to be clear, this is a preorder for a humanoid home robot that will cost $20,000 or $500/month when it (maybe) ships next year, and currently is not finished. Joanna Stern got to do a demo in its current state, and 100% of its actions are tele-operated (https://t.co/nOAfAJca8l)
I see this as more of a hype reel for a thing that they're hoping to be able to make someday... which is becoming SO common with products these days
Progress toward real-time proving for Ethereum L1 is nothing short of extraordinary.
In May, SP1 Hypercube proved 94% of L1 blocks in under 12 seconds using 160 RTX 4090s. Five months later Pico Prism proves 99.9% of the same blocks in under 12 seconds, with just 64 RTX 5090s. Average proving latency is now 6.9 seconds.
Performance has outpaced Moore's law ever since Zcash pioneered practical SNARKs a decade ago. Today's Pico Prism results are a striking reminder of that exponential curve.
Beyond performance, zkVM diversity is remarkable. At least nine zkVMs are racing toward real-time proving: Airbender, Ceno, Jolt, OpenVM, Pico Prism, R0VM, SP1 Hypercube, Ziren, ZisK. That diversity is strength, similar to CL and EL client diversity.
Fusaka, expected in December, will simplify real-time proving. EIP-7825 caps per-tx gas usage, enabling more parallel proving via subblocks. MODEXP, a prominent "prover killer", is being repriced with EIP-7823 and EIP-7883.
By year's end several teams will prove every L1 EVM block on a 16-GPU cluster, drawing less than 10kW total. The 10kW target—about the same as a Tesla home charger—matters for on-prem proving in garages and offices, eliminating reliance on cloud proving.
gigagas frontier
L1 throughput has grown 100x since genesis ten years ago, from 20 kilogas/sec to 2 megagas/sec. With zkEVMs we can 100x again, in half the time. The key is to bypass validators as Ethereum's current scalability bottleneck.
Lean execution proofs also decentralise validation. Goodbye 4TB NVMe, 8 cores, 64GB RAM recommended by EIP-7870. A Raspberry Pi running statelessly, or even a phone, will soon suffice. The scalability vs decentralisation dilemma is dying.
Zooming out, the lean Ethereum vision is gigagas L1 and teragas L2. Gigagas L1 (10K TPS) means high-value payments, trading, and social apps directly on mainnet. Teragas L2 (10M TPS) means welcoming the entirety of finance onto Ethereum.
Nov 22: Ethproofs day demo
Behind the scenes teams are preparing a special Devconnect demo. In 38 days my home validator will run on zkEVM proofs. My mighty Geth node will go dark—no more execution client.
Devconnect Argentina is Ethereum's world fair. World fairs unveiled the lightbulb, running water, cars, refrigeration, phones, escalators. Real-time proving is Ethereum's lightbulb moment.
Ethereum's future is bright. Believe in something :)
Today, @aave experienced the largest stress test of its $75B+ lending infrastructure. The protocol operated flawlessly, automatically liquidating a record $180M worth of collateral in just one hour, without any human intervention.
Once again, Aave has proven its resilience.
1/ I’m excited to announce @inversion_cap seed round, led by @dragonfly_xyz with participation from some of the top funds and operators in the space.
I started Inversion because I refused to wait another decade for crypto to go mainstream. Crypto has been dismissed as a casino for too long, overshadowing the teams building technology that can transform industries.
Our conviction: crypto is not just speculation. It’s core infrastructure. It can make businesses run faster, cheaper, and more efficient - just as the Internet once did.
So why hasn’t mainstream adoption happened?
Because the industry keeps leading with speculation. If stablecoins and DeFi are so revolutionary, why aren’t billions of people using them yet? This question became the driving force behind Inversion.
Our answer: invert the playbook.
• Instead of building distribution from scratch, we acquire it.
• Instead of waiting for businesses to adopt crypto, we buy them and lead the transformation ourselves.
• Instead of forcing users to learn new tech, we make crypto invisible.
• Instead of pushing ideology, we lead with business logic.
At Inversion, we acquire legacy businesses and transition their operations to crypto rails - reducing fees, chargebacks, settlement times, and costs while unlocking real value through stablecoins, DeFi, and infrastructure protocols.
Past cycles gave us a death by a thousand pilots from enterprises. Today, the tech is ready. It’s time to invert the playbook and hack our way to mass adoption.
One of the most rewarding parts of this journey has been the people. @dannheim_ joined as our first hire after leading crypto at Goldman, and making her co-founder was a natural progression of the partnership we’ve built.
We’re just getting started - and we’re hiring: 👉 https://t.co/e1RkYwPUiW
Read more in the Wall Street Journal: https://t.co/ImhZTLfqr1
Real GDP onchain.
Invert, always invert.
Honestly, it's a joke how many Web 3 startups we invested in back in 2021/2022 have quietly shut down without even informing their investors.
As if such a quiet rug is the acceptable practice.
At least send a sorry, good bye and thank you email FFS