To understand what it takes to build a humanoid robot with model-based control, we finetuned @physical_int 's (PI) Pi05 model for our custom use case and environment.
We incurred ~$10K in hardware costs, compared to the typical ~$20K set up (DROID/ALOHA).
Here are the lessons and challenges we faced building the first working prototype (shown in the video) in 3 months.
Part 1: Hardware, Software, Model Selection, Custom Embodiment, Inference, Embedded Hardware, Hierarchical Planner
Part 2: Model Evaluation, Data Collection, Model Training, Simulation and Teleoperation
We hope sharing our experience accelerates the learning of others who are in a similar starting point.
If you need a domain specific model that outperforms frontier models and reduces inference cost, @googrish and the @castformai team have the best product for it.
We're in Boston this week for #RoboticsSummit, and NYC next week.
Who should I meet to exchange notes and explore overlaps on vertical robotics?
We're building robots for datacenters and are actively thinking about early commercialization angles, continuous post-training pipelines fed by fleet data and scalable verification for RL.
Glad to see this project getting some recognition, thanks @dwarkesh_sp
People are surprised when I say I worked on datacenters when I was at Jane Street
“Why do you need to run datacenters?”
“Aren’t you a software engineer?”
When I first joined the team it was daunting, I was a fresh grad and knew nothing about DC ops
Over time I realized it was one of the best positions I could find myself in early in my career
Beyond the technical complexity of running critical infrastructure, supporting the entire firm led to collaborations across multiple teams
I was often reminded how much we take physical infrastructure for granted, and how much impact I can have solving problems with new tech in a traditional industry
Jane Street just showed the inside of their AI training data center in Texas.
4,032 GPUs. 56 racks. 8,000 km of fiber. liquid cooling running through every server because air cooling can't handle the heat anymore.
but the part that got me was the origin story.
Ron Minsky, who co-heads their technology group. said their first compute cluster was literally six Dell boxes stacked on top of each other at the end of a desk row. they called it "the hive."
the trading systems sat out in the room with the traders because they wanted to be able to unplug them if something went wrong.
at one point, someone vacuuming the office unplugged a live trading system in the middle of the day.
from six Dell boxes and a vacuum cleaner incident to a liquid-cooled GPU data center processing trades in under 100 nanoseconds.
that's a 20-year arc.
We'll be in SF next week for Data Center Expo.
Do I know anyone deploying robots in industrial or similar settings?
We're building robots for datacenters and are working together with our first enterprise partner. Would love to share notes and explore overlaps.
Real-world RL, engineering deployment pipelines for continuously improving models, and early commercialization are top of mind.
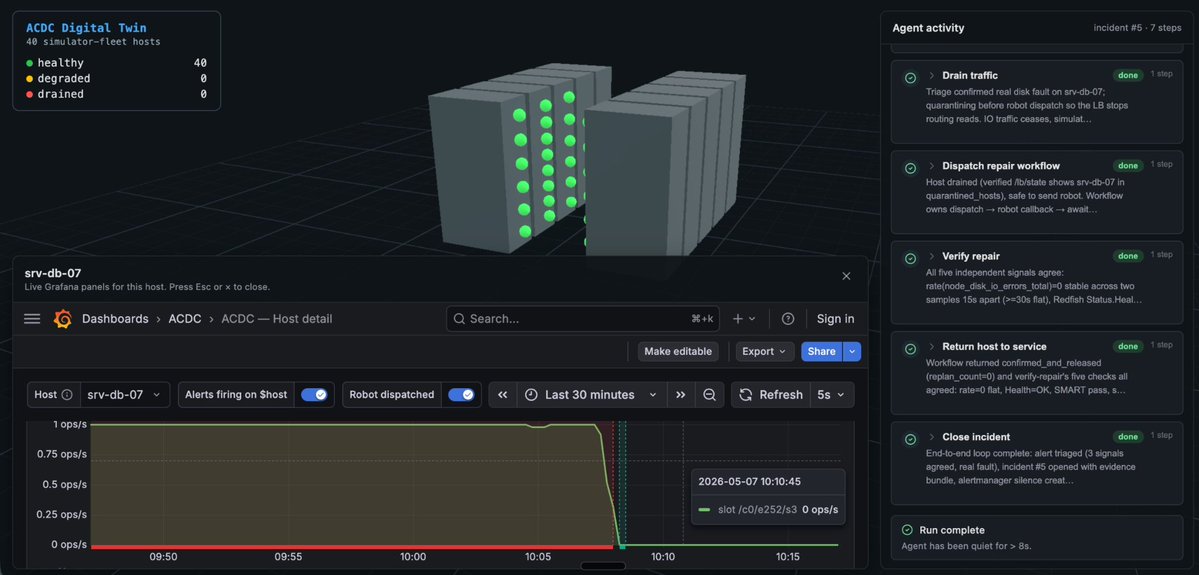
Digital twins for datacenters are still hard to build in 2026
As agents control systems more autonomously, the need for high-level observability and visualization will only increase
We need to know quickly how agents are running to make sure they do not go off the rails
Who’s working on continuous improvement model posttraining tools in the open source? (For AI robotics models)
Sounds like the kind of thing that would benefit from co-developing with the community.
Would love to meet others building their own.
Excited to share LWD: Learning While Deploying. Our robots learn while doing real tasks—restocking groceries, brewing Gongfu tea, making cocktails, making juice, and packing shoes. Deployment is no longer just evaluation; it becomes the training loop.
🧵
Congrats on the new MolmoAct 2 release by @allen_ai!
A few features that stood out for those considering this for real-world deployments:
1. YAM embodiment unlock + 720h teleoperated dataset
720 hours of bimanual YAM data is a meaningful contribution. The YAM embodiment is a simple bimanual arm setup for dexterous tasks, very similar to the dual PiperX and Trossen WidowX arms. Anyone building on @physical_int 's Pi05 or similar models with a YAM-type robot now has significantly more data to fine-tune from, which should reduce the fine-tuning samples needed for a custom task, assuming the target task and environment fall within the dataset's distribution.
The dataset spans household, factory, and coffee-shop settings with high object and scene variation. @cortexairobot was the data vendor. Hoping the appendix detailing the quality control protocol gets released.
2. Depth reasoning as a reproducible recipe, but only with layer-level access
MolmoAct2-Think shows one way to inject depth information into the action model. Before producing an action, the model predicts a compact discrete depth representation that conditions the action expert through per-layer KV conditioning.
The mechanism requires surgical access to the VLM's intermediate attention states at every layer, something only possible with fully open architectures.
3. Swappable VLM backbones for converting VLM -> VLM-ER
The released training recipe effectively decouples the perception backbone from the action head. You can pick a VLM optimized for your task domain rather than accepting a generic vision encoder.
Hypothetical example: for warehouse sorting where success hinges on reading tiny, cluttered, blurry SKU labels, start from a VLM fine-tuned for OCR (e.g., a custom Qwen-VL or InternVL variant) instead of a generalist web-scale VLM.
Apply the MolmoAct2-ER training recipe to that backbone to produce an "OCR-VL-ER" variant, then attach a flow-matching Action Expert. The result is a bespoke VLA that inherits your perception fine-tuning, optimized for label-reading manipulation rather than generic open-world scenes.
This assumes catastrophic forgetting is minimized and the backbone retains most of the baseline capabilities it had before fine-tuning.
With this recipe, you can swap in domain-specific backbones (medical imaging, industrial inspection, high-res OCR) and convert them into action models entirely from open components.
Robotics models often struggle outside controlled environments. Ours is built to work in real ones.
Today we're launching MolmoAct 2, which can assist with a host of chores & lab tasks, plus the MolmoAct 2-Bimanual YAM dataset—the largest open robotics dataset of its kind. 🧵
Simulations are core to robotics research, but spinning up custom scenes is still tedious and has a steep learning curve
We built mujoco workbench (mwb): cli + agent skills for codex/claude code to scaffold and debug sim scenes from natural language
"A robotics-shaped take-off curve." Cracking distribution is as hard as the technical challenges to commercialize early, especially when customers need to see a plausible trajectory, hardware budgets are tight, and data collection needs funding.
"Channel construction is the most underestimated lever in the stack." Creating the data flywheel that powers continuous improvement and eventual task reliability is what closes the gap to real-world deployments that actually create value.
"Deployment-system engineering matters as much as model architecture." Similar to the systems around early LLM applications and AI voice agents, a model's capabilities are only as good as the scaffolds around it. This is where engineering depth and iteration speed compound into capability.
The teams that earn the right to a first deployment reliable enough to kickstart the data flywheel will crack adoption in a new vertical.
@LukasForTech The skills and CLI focus on scene creation and not the physics engine for now.
So if you mean creating scenes from the standard MuJoCo library for your UAV testing then yes, it is supported.
Sims are an essential piece of any researcher's experimental loop, both for training data and for evaluation.
However, spinning up quick scenes still requires a learning curve and reading extensive documentation.
This is true even for the small but critical fraction of training data needed for diversity, or for quick, directionally correct evaluation checks.
In response, we built MuJoCo Workbench (MWB), a CLI and set of agent skills to prototype custom scenes with coding agents like Codex and Claude Code. Repo is in the next post.
It's an attempt to make building diverse scenes a delightful experience, and to maximize what coding agents can do in researchers' hands to accelerate their experimental loops.
How it works:
1. Install the bundled agent skills.
2. Describe what you want, and the agent scaffolds a working sim for you.
No MuJoCo experience is required to get started.
The skills teach the agent the mwb CLI, the scene layout conventions, and the debug tools, so it can iterate on behavior without you needing to know the plumbing.
We're working on extending MWB with a built-in integration for real-time inference on open-source VLAs/VAMs like Pi05.
If you recognize the problems mentioned here and want to learn more, reach out.
[Major life updates] 🎉
After 4 incredible years of my PhD at @UW@uwcse with @fox_dieter17849 and @RanjayKrishna, I'm joining @NUSComputing as an Assistant Professor this August, under the Presidential Young Professorship scheme!
More details 🧵👇


















![DJiafei's tweet photo. [Major life updates] 🎉
After 4 incredible years of my PhD at @UW @uwcse with @fox_dieter17849 and @RanjayKrishna, I'm joining @NUSComputing as an Assistant Professor this August, under the Presidential Young Professorship scheme!
More details 🧵👇 https://t.co/yDNXRRHN53](https://pbs.twimg.com/media/HHewex2aYAAfFqE.jpg)





























