1 API key, 220,000+ AI models. We’re the largest inference API on the internet and power NeurIPS and CVPR to bridge the gap between AI papers and runnable code✨
Run 100,000+ AI Models for Free
Build AI faster with the largest inference API on the internet. Instantly demo and deploy thousands of models through one unified API.
Serverless inference. No infra or DevOps required. Free for developers.
Try now👇
How Bytez 0.1 works:
Think of an exam. 1,000 students in the room — each one the top mind in their field. Lawyers, doctors, engineers, artists.
Teacher asks a question. Everyone writes their answer.
Our model gets to cheat. It sees all 1,000 answers. It figures out what kind of question was asked. Legal question? It pulls the top 3 legal minds' answers. Medical? Top 3 medical minds.
Then it either combines their answers or picks the best one.
Every other model gets 1-shot at the answer. Ours gets N-shots, from N experts.
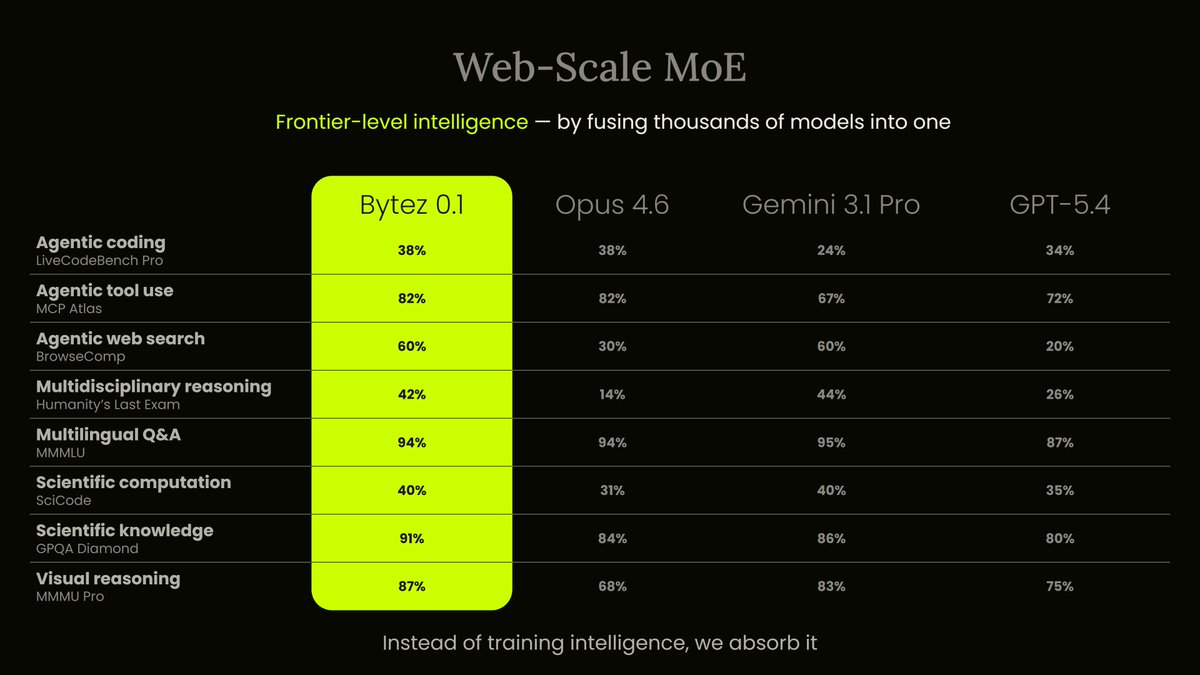
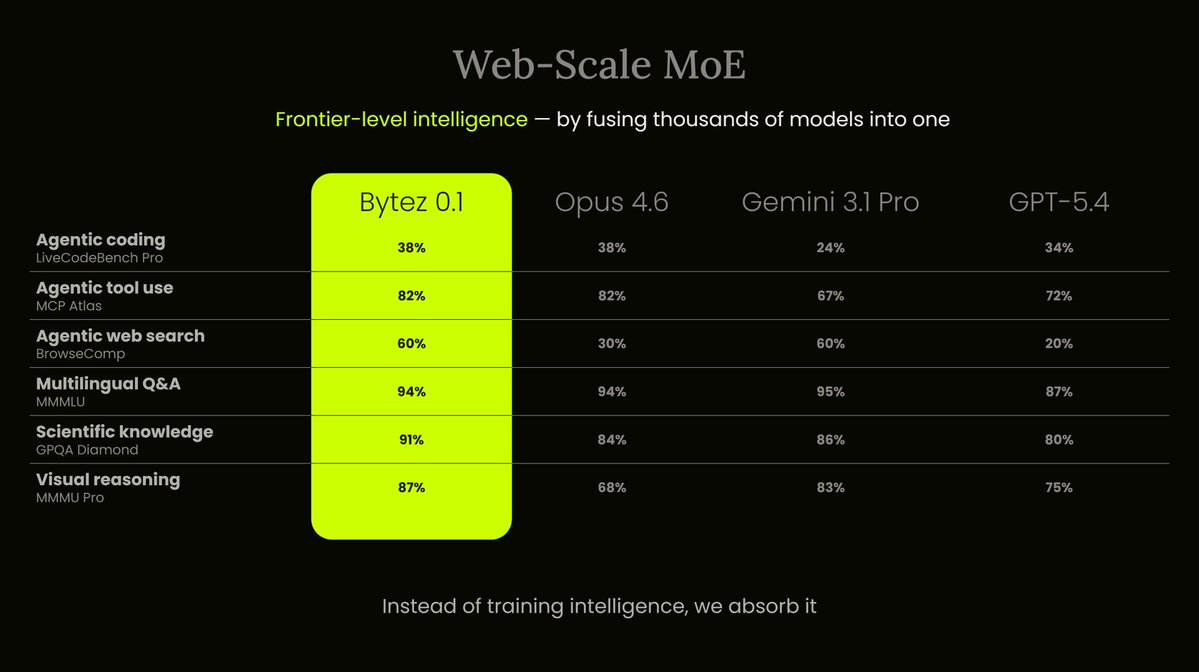
This is what we call a Web-Scale MoE. Each "expert" isn't a subnetwork inside a single model — it's an entirely separate model.
As more experts show up on the web, our model gets smarter without retraining.
The upside: it scores higher than Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 across benchmarks.
The downside: it behaves like a bigger model and costs more to run.
We think the tradeoff is worth it. 1,000 minds wired together are smarter than any single mind.
Is the path to AGI training one massive mind — or wiring together every mind that comes into existence?
Gemma 4 Models Now Available On Bytez
Hey all, as promised, we keep up with the latest and greatest in open source and closed source machine learning.
The following models are now available:
google/gemma-4-E2B-it
google/gemma-4-E4B-it
google/gemma-4-26B-A4B-it
google/gemma-4-31B-it
Models support the ability to understand text, image, audio, and video as context.
Hit them either via the Bytez.js client, or via our chat/completions endpoint!
May thy vibe harvest be fruitful, and may thy cup overfloweth with success!
https://t.co/aueAkgISZe
The Position Paper Track is back at NeurIPS 2026 for the second year, with an expanded scope, and better alignment with the main and Evaluation and Dataset tracks!
Head to the Call for Paper at https://t.co/AexnZLLfsx for all the important dates and information and read our accompanying blog post at https://t.co/02v3jUxv7J to learn more about the changes we are making this year and how we adapted the process based on the feedback we got from the community!
The submission deadline is the same as for the main and ED track: May 6, 2026 AoE. We are looking forward to read your papers and any feedback you may have!
Bytez 0.1 beats Opus, Gemini Pro, and GPT-5.4 across benchmarks.
Achieved without spending millions on GPUs.
Karpathy recently said LLM ensembles are "under-explored."
He vibe-coded a weekend prototype to test the idea.
We've been building the production version for 2 years. Bytez 0.1 is a Web-Scale MoE — instead of training one massive model, we fuse thousands of models into a single intelligence.
Instead of training intelligence, we absorb it.
More benchmarks dropping soon.
What's a faster path to a v1 of AGI?
A) One massive model that tries to be an expert on everything
B) Thousands of experts fused into one
Bytez 0.1 update: more evals ran, matching or beating Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 across benchmarks
PS: the 0.1 model also does pro-level 3D generation
What happens after models learn to generate 3D worlds?
Bytez 0.1 beats Opus, Gemini Pro, and GPT-5.4 across benchmarks.
Achieved without spending millions on GPUs.
Karpathy recently said LLM ensembles are "under-explored."
He vibe-coded a weekend prototype to test the idea.
We've been building the production version for 2 years. Bytez 0.1 is a Web-Scale MoE — instead of training one massive model, we fuse thousands of models into a single intelligence.
Instead of training intelligence, we absorb it.
More benchmarks dropping soon.
What's a faster path to a v1 of AGI?
A) One massive model that tries to be an expert on everything
B) Thousands of experts fused into one
.@illscience says the future of AI isn’t one model to rule them all—and explains why platforms that integrate multiple models will benefit the most:
"I think we're going to need and rely on all of the models."
"It's sort of like if you have a team of people... if you have five people, they could all do a basic set of things pretty capably."
"But then they all have their specializations. Maybe one of them is really good at closing a customer who doesn't want to sign the deal, and one of them is really good at culture and getting the best out of the team."
"There are some areas in which they are going to build apps, and that will be a threat to app companies. But there are many areas in which app companies are advantaged. Cursor and Krea are great examples of this—products where you benefit from being multi-model."
"When you actually use a creative tool, you don't want to just use Nano Banana, you want to have access to OpenAI, Nano Banana, Kling—all of them—Qwen, you name it. So using a single interface to access all the models is powerful."
Anish Acharya on BILLIONS with @GuillaumeMbh
Last week, we launched Palatial PhysReady and the response blew us away. Over 100 companies signed up for our waitlist and the team had a blast watching everyone tagging @PalatialSim with their creative prompts.
We generated over 100 assets in 1 day and below are a few of the highlights.
We're looking forward to giving everyone access to the platform and API, wave 2 goes live on Wednesday! Sign up at https://t.co/5fUD94wuge
A child consumes more data in 1 month than any LLM has ever seen. Embodied agents learn by doing, but the data that teaches them is tactile, sensorial and causal.
Such data does not exist.
To make physical AGI possible, we need to generate this new data at an industrial scale.
Enter Palatial: automated infrastructure that converts raw data into sensory rich playgrounds for robots to learn in.
Today, we’re unveiling Palatial PhysReady, the first automated sim asset generator (try it ⬇️) [1/5]
The future of AI is agentic, and America is leading the way to make it secure and interoperable.
A new AI Agent Standards Initiative is launching this week @NIST to drive industry-led standards and open protocols that build trust and advance innovation. https://t.co/bS5oqvU8iu
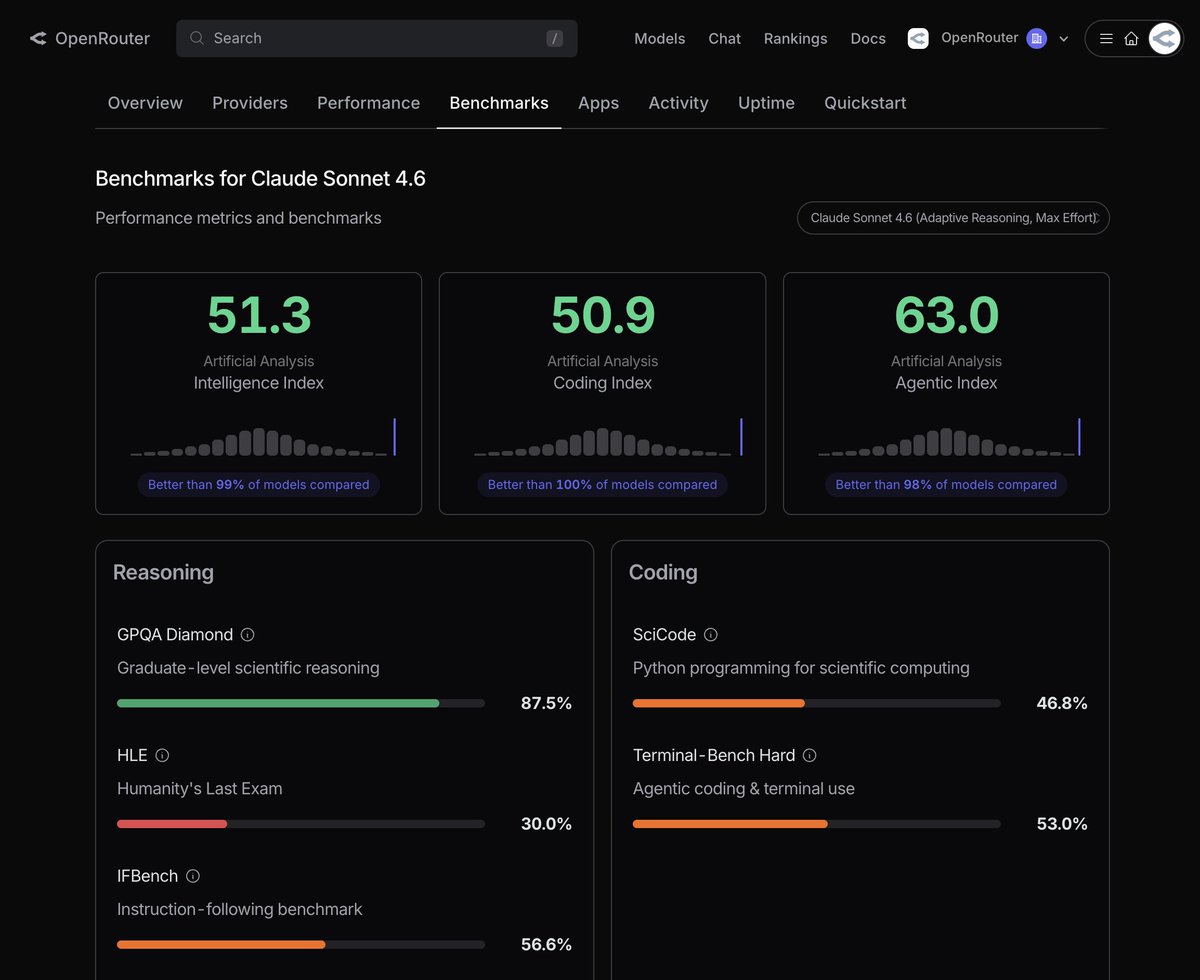
Benchmarks are now available on OpenRouter!
See how models perform on industry standard tests, including programming, math, science, long context reasoning, and more to come.
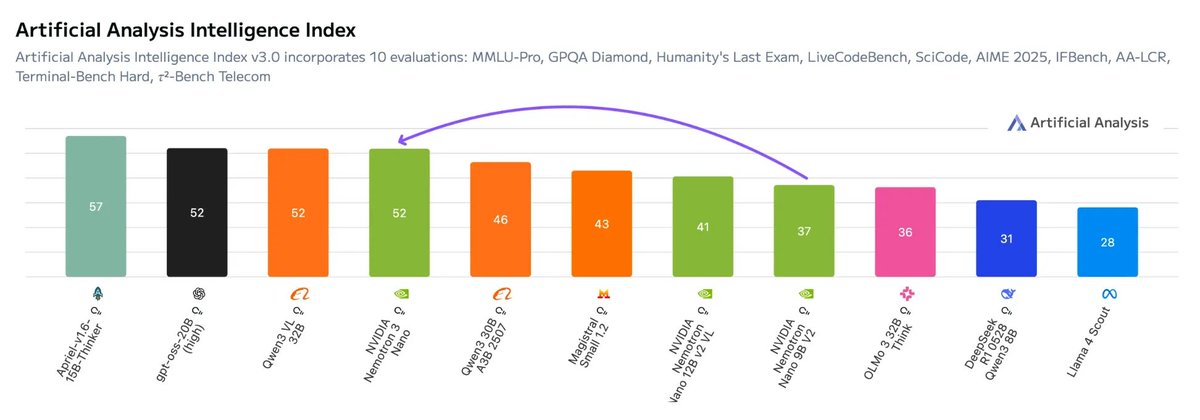
NVIDIA has just released Nemotron 3 Nano, a ~30B MoE model that scores 52 on the Artificial Analysis Intelligence Index with just ~3B active parameters
Hybrid Mamba-Transformer architecture: Nemotron 3 Nano combines the hybrid Mamba-Transformer approach @NVIDIAAI has used on previous Nemotron models with a moderate-sparsity MoE architecture, enabling highly efficient inference, particularly at longer sequence lengths
Small-model improvements: with 31.6B total and 3.6B active parameters, Nemotron 3 Nano scores 52 on our Intelligence Index, in line with OpenAI’s gpt-oss-20b (high). This represents a +6 point lead on the similarly-sized Qwen3 30B A3B 2507 and +15 improvement on NVIDIA’s previous Nemotron Nano 9B V2 (a dense model)
High openness: Nemotron 3 Nano follows other recent NVIDIA models in open licensing and releases of data and methodology for the community to use and replicate - it scores an 67 on the Artificial Analysis Openness Index, in line with previous Nemotron Nano models
Key model details:
➤ 1 million token context window, with text only support
➤ Supports reasoning and non-reasoning modes
➤ Released under the NVIDIA Open Model License; the model is freely available for commercial use or training of derivative models
➤ On launch, the model is being made available with a range of serverless inference providers including @baseten, @DeepInfra, @FireworksAI_HQ, @togethercompute and @friendliai, and it is available now on Hugging Face for local inference or self-deployment
See below for our full analysis and key announcement links from NVIDIA 👇