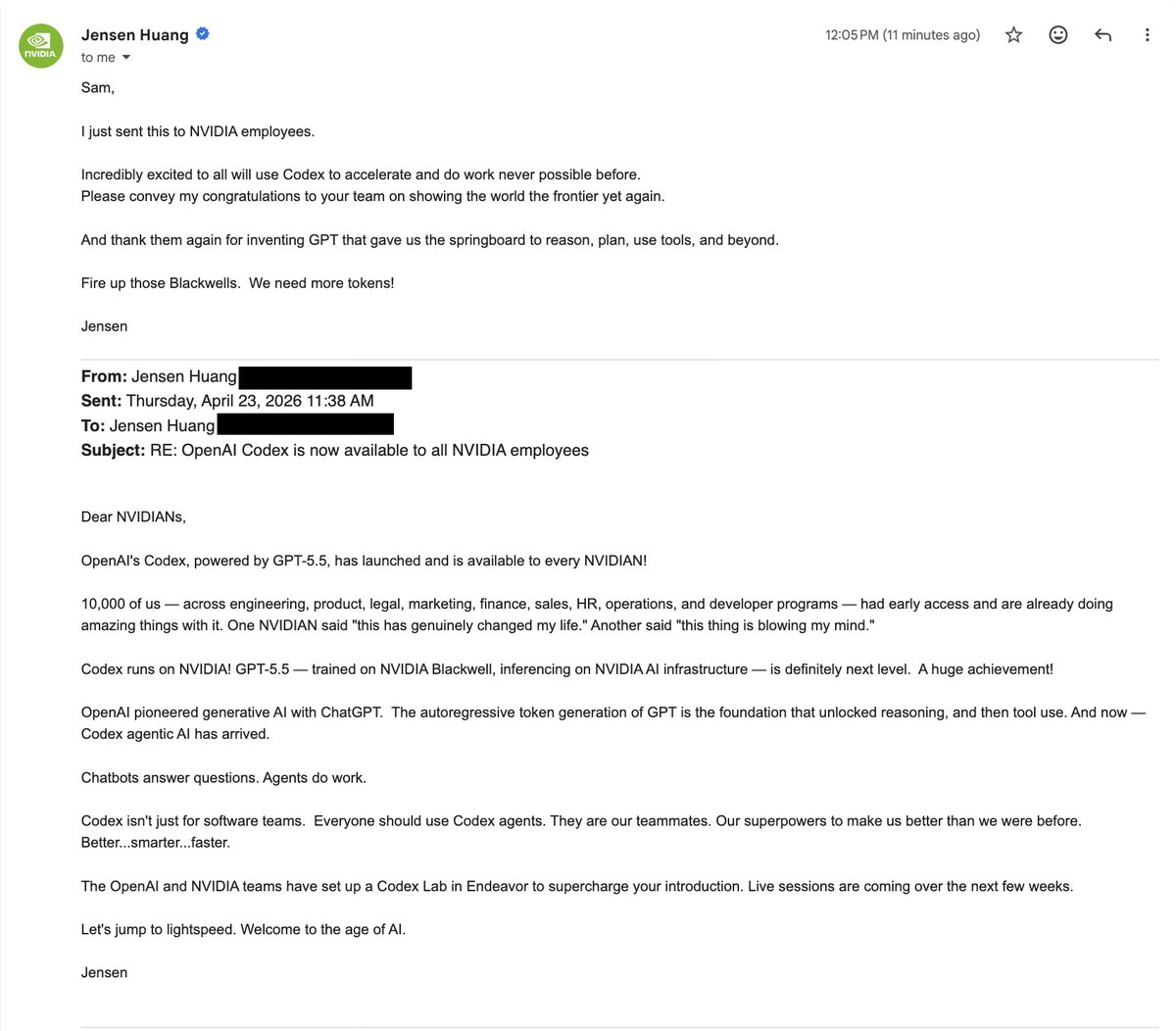
We tried a new thing with NVIDIA to roll out Codex across a whole company and it was awesome to see it work.
Let us know if you'd like to do it at your company!
🌅 BASIC is BACK!
In response to overwhelming demand from seasoned developers everywhere, we’re releasing cuTile BASIC for GPUs, bringing CUDA Tile programming to this long-overlooked language.
🧵 👇
OpenAI shipped a HUGE upgrade to ChatGPT Code Interpreter and failed to document it (even in the release notes) - but ChatGPT can now pip/npm install packages and run code in Python, Node.js, Bash, Ruby, Perl, PHP, Go, Java, Swift, Kotlin, C and C++! https://t.co/El5osALZGx
Tomorrow we’re hosting a town hall for AI builders at OpenAI. We want feedback as we start building a new generation of tools.
This is an experiment and a first pass at a new format — we’ll livestream the discussion on YouTube at 4 pm PT.
Reply here with questions and we’ll answer as many as we can!
Today Groq entered into a non-exclusive licensing agreement with Nvidia for Groq’s inference technology. Along with other members of the Groq team, I’ll be joining Nvidia to help integrate the licensed technology. GroqCloud will continue to operate without interruption.
Learn more here: https://t.co/1Lgv1EKZNH
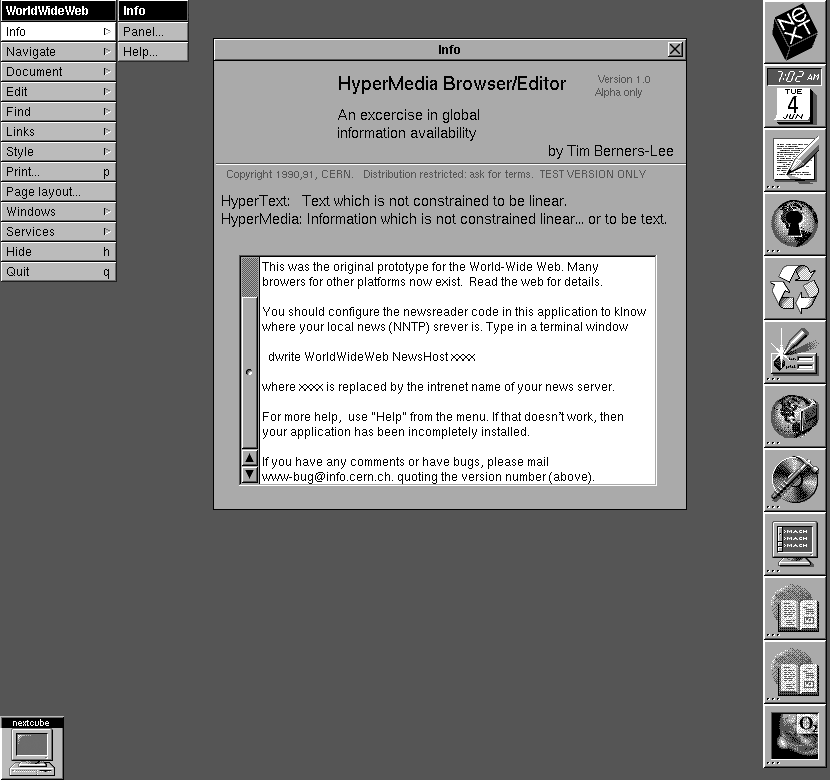
Happy 35th Birthday WorldWideWeb – the first browser!
On December 25, 1990, at CERN, a British physicist and internet pioneer Tim Berners-Lee created the world's first web browser, called WorldWideWeb.
Try the browser emulator https://t.co/1ZxhMhVTFj
#InternetHistory
Warm yourself by the virtual fireplace in this cosy 8-bit #Christmas scene. No MS-DOS or floppy 💾 drive required to stoke this very 1980s hearth. Thanks to software preservation, the flames are still crackling on the Internet Archive.
✉️ Open the full 1986 Sierra On-Line "A Computer Christmas" card ⤵️
https://t.co/OyMjGrtx9U
#RetroComputing #VintageComputing #8bit #SoftwarePreservation #ComputerHistory
At #OCPSummit25 this week?
Stop by the #NVIDIAMGX Ecosystem to explore the many components that go into creating an #AIfactory and learn more about our ecosystem partners.
Don't forget to join our MGX Ecosystem Sweepstakes for a chance to win an #NVIDIADGX Spark. ✨
Check out our latest advancements in NVIDIA accelerated computing, happening at OCP Global Summit. ➡️ https://t.co/qqw5HU6VNJ
It’s rare for competitors to collaborate. Yet that’s exactly what OpenAI and @AnthropicAI just did—by testing each other’s models with our respective internal safety and alignment evaluations. Today, we’re publishing the results.
Frontier AI companies will inevitably compete on capabilities. But this work with Anthropic is a small, meaningful pilot toward a “race to the top” in safety. The fact that competitors collaborated is more significant than the findings themselves, which are mostly basic.
Transparency + accountability → safer AI.
Read the report: https://t.co/eWLZY4gryC
I am alarmed by the proposed cuts to U.S. funding for basic research, and the impact this would have for U.S. competitiveness in AI and other areas. Funding research that is openly shared benefits the whole world, but the nation it benefits most is the one where the research is done.
If not for funding for my early work in deep learning from the National Science Foundation (NSF) and Defense Advanced Research Projects Agency (DARPA), which disburse a good deal of U.S. research funding, I would not have discovered lessons about scaling that led me to pitch starting Google Brain to scale up deep learning. I am worried that cuts to funding for basic science will lead the U.S. — and also the world — to miss out on the next set of ideas.
In fact, such funding benefits the U.S. more than any other nation. Scientific research brings the greatest benefit to the country where the work happens because (i) the new knowledge diffuses fastest within that country, and (ii) the process of doing research creates new talent for that nation.
Why does most innovation in generative AI still happen in Silicon Valley? Because two teams based in this area — Google Brain, which invented the transformer network, and OpenAI, which scaled it up — did a lot of the early work. Subsequently, team members moved to other nearby businesses, started competitors, or worked with local universities. Further, local social networks rapidly diffused the knowledge through casual coffee meetings, local conferences, and even children’s play dates, where parents of like-aged kids meet and discuss technical ideas. In this way, the knowledge spread faster within Silicon Valley than to other geographies.
In a similar vein, research done in the U.S. diffuses to others in the U.S. much faster than to other geographic areas. This is particularly true when the research is openly shared through papers and/or open source: If researchers have permission to talk about an idea, they can share much more information, such as tips and tricks for how to really make an algorithm work, more quickly. It also lets others figure out faster who can answer their questions. Diffusion of knowledge created in academic environments is especially fast. Academia tends to be completely open, and students and professors, unlike employees of many companies, have full permission to talk about their work.
Thus funding basic research in the U.S. benefits the U.S. most, and also benefits our allies. It is true that openness benefits our adversaries, too. But as a subcommittee of the U.S. House of Representatives committee on science, space, and technology points out, “... open sharing of fundamental research is [not] without risk. Rather, ... openness in research is so important to competitiveness and security that it warrants the risk that adversaries may benefit from scientific openness as well.”
Further, generative AI is evolving so rapidly that staying on the cutting edge is what’s really critical. For example, the fact that many teams can now train a model with GPT-3.5- or even GPT-4-level capability does not seem to be hurting OpenAI much, which is busy growing its business by developing the cutting-edge o4, Codex, GPT-4.1, and so on. Those who invent a technology get to commercialize it first, and in a fast-moving world, the cutting-edge technology is what’s most valuable. Some studies (link in original post, below) also show how knowledge diffuses locally much faster than globally.
China was decisively behind the U.S. in generative AI when ChatGPT was first launched in 2022. However, China’s tech ecosystem is very open internally, and this has helped it to catch up over the past two years:
- There is ample funding for open academic research in China.
- China’s businesses such as DeepSeek and Alibaba have released cutting-edge, open-weights models. This openness at the corporate level accelerates diffusion of knowledge.
- China’s labor laws make non-compete agreements (which stop an employee from jumping ship to a competitor) relatively hard to enforce, and the work culture supports significant idea sharing among employees of different companies; this has made circulation of ideas relatively efficient.
While there’s also much about China that I would not want the U.S. to emulate, the openness of its tech ecosystem has helped it accelerate.
In 1945, Vannevar Bush’s landmark report “Science, The Endless Frontier” laid down key principles for public funding of U.S. research and talent development. Those principles enabled the U.S. to dominate scientific progress for decades. U.S. federal funding for science created numerous breakthroughs that have benefited the U.S. tremendously, and also the world, while training generations of domestic scientists, as well as immigrants who likewise benefit the U.S.
The good news is that this playbook is now well known. I hope many more nations will imitate it and invest heavily in science and talent. And I hope that, having pioneered this very successful model, the U.S. will not pull back from it by enacting drastic cuts to funding scientific research.
[Original post, with links: https://t.co/JR3x4O1iVr ]
I am super excited for AI for scientific innovation, a direction that will certainly grow in the next five years. I think there will be two flavors of it.
The first is “deepmind style”, where there is a very specific, important problem to solve (e.g., protein-folding), and you care just about that problem and train a model with a specific RL environment to solve that task. So far, large language models have not been the best instantiation for these types of problems, because these problems are structured and so specialized that having natural language pre-training isn’t the highest-order bit in solving them. This may change as our frontier models get better but I am not certain of it.
The second flavor is “generalist style”, where we train an AI that is generally better at running experiments than humans. An example in automating AI research would be if you specify some set of evals and give the model 10 days and 1k GPU, and the model tunes hyperparameters and debug runs, resulting in good evals in the end. An example in the life sciences would be if you are trying to amplify detection of some particle, and the model can optimize the setup given some limited time and resources better than most chemists could.
It’s not clear to me which one will win out; probably we’ll have both. Different types of science crave different types of innovation—some fields like chemistry or physics require major discoveries to transform them; other fields like AI can progress and have substantial impact from a combination of small improvements in many axes. And I think AI will first reach superhuman level on tasks where there is a clear reward, but will be slower for tasks like understanding why some phenomena happens because it’s harder to RL when there isn’t an easy-to-grade reward.
In any case, I think that in the future we’ll get used to the idea of simply “purchasing” scientific innovation with compute (could require a lot of it), and that is super exciting!
Shoutout to @Nasdaq for featuring us in Times Square, NYC!
🌍The excitement is building for Jensen’s keynote around the world.
While everyone can watch the livestream, register for #GTC25 to join us in person or online for keynote-related sessions. https://t.co/0iUSsc6f5h
. @ylecun and @BillDally will explore the future of AI models, hardware accelerators, and the evolving computational landscape at #GTC25.
💡Join us March 18 at 2 p.m. PDT: https://t.co/fVBHdPWGyZ
Maggie Zhang, a software engineer at NVIDIA, is passionate about how systems can help efficiently solve the world’s greatest challenges. Learn more about their role evaluating NVIDIA NIM microservices: https://t.co/GrE90lbX1m #NVIDIAlife
Whenever I post something critical of Meta’s handling of VR, there are always some old timers that pile on with “Yeah! More AAA PC VR Games is the way to win!”. To be clear — standalone VR was the biggest win that VR ever had, by a huge margin, and Beat Saber was far more important than Half-Life Alyx.
Using a PC to drive VR experiences is a boutique niche. Still valuable and definitely worth supporting as a bonus feature, but not something that was going to turn into even console level success, let alone mobile level.
The economics of AAA development were never going to be widely brought to bear on a PC accessory. I do think there is opportunity for AAA content to profitably have “VR bonus features”, but not fully designed-for-VR projects at comparable levels of effort.
"By making @AIatMeta Llama models open source, we're committed to democratizing access to cutting-edge AI technology. With Project DIGITS, developers can harness the power of Llama locally, unlocking new possibilities for innovation and collaboration.”
-- @Ahmad_Al_Dahle, VP, GenAI at Meta