CTO and cofounder @ParseBio. Co-developer of single cell combinatorial barcoding method SPLiT-seq. Making genomics more scalable, flexible, and accessible.
Check out our two new papers with new single-cell tech/methods/data!
1. Phospho-seq: Multi-modal profiling of intracellualar proteins
https://t.co/6z5rx0UeNU
2. Systematic Perturb-seq of signaling regulators (2.6M cells, 6 cell lines, 1500 perturbations)
https://t.co/PPc31sW0dO
So excited to work with @ParseBio to share my work studying the role of Sox9 in promoting branching morphogenesis in mouse intrahepatic bile ducts (IHBDs).
I will highlight how Parse scRNA-seq enabled discovery of a target to rescue IHBD branching in mice lacking Sox9.
Are you attending #ASHG23? Don't miss our featured education session with Rahul Satija (@satijalab) from the New York Genome Center. Lunch will be provided for the first 50 attendees.
📣 "Single cell sequencing using Evercode shows a superior outcome compared to 10x Genomics™"
Watch the full video here 👉 https://t.co/c2dKKALp2N
#comparisonstudy#research#singlecell
Join @CharlieRoco, Co-Founder and CTO of @ParseBio as he reveals important insights in his talk, "Expanding Capabilities in Single Cell RNA Sequencing".
Don't miss this opportunity to gain new perspectives at #FoGBoston#RNA#SingleCell
Find out more: https://t.co/KQmfdXPXt7
Happy to present our new preprint! We ran a head-to-head comparison of sample multiplexing reagents for single-cell RNA-Seq on the same samples on the same day. 1/9 https://t.co/c0gK98224B
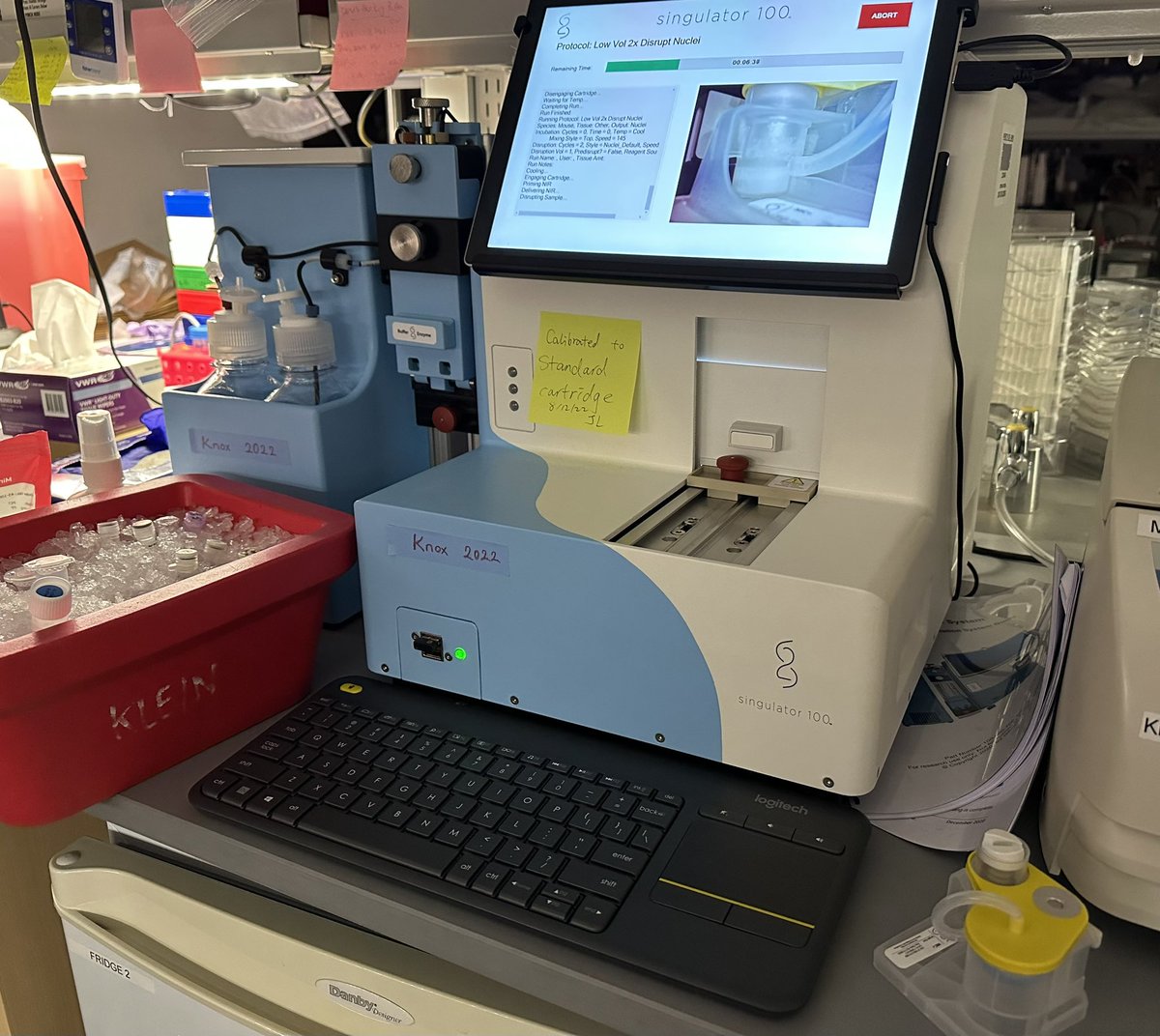
That was nuclei extraction extraction, using @S2Genomics singulator and fixation w/ @ParseBio kits (lucky 13 kits!). Looking forward to the next steps 👩🏻🔬
And how was your week? #postdoclife#biology
Big thanks to @ToonSwings and the entire #RNGS23 organizing committee for inviting me to represent @ParseBio in beautiful Ghent! What a great conference - hope to be back again soon!
@nomad421@mikelove Looks like this paper from 2016 had the same conclusion
https://t.co/Ggox6VLpU2
"For future RNA-seq experiments, these results suggest that at least six biological replicates should be used, rising to at least 12 when it is important to identify SDE genes for all fold changes."
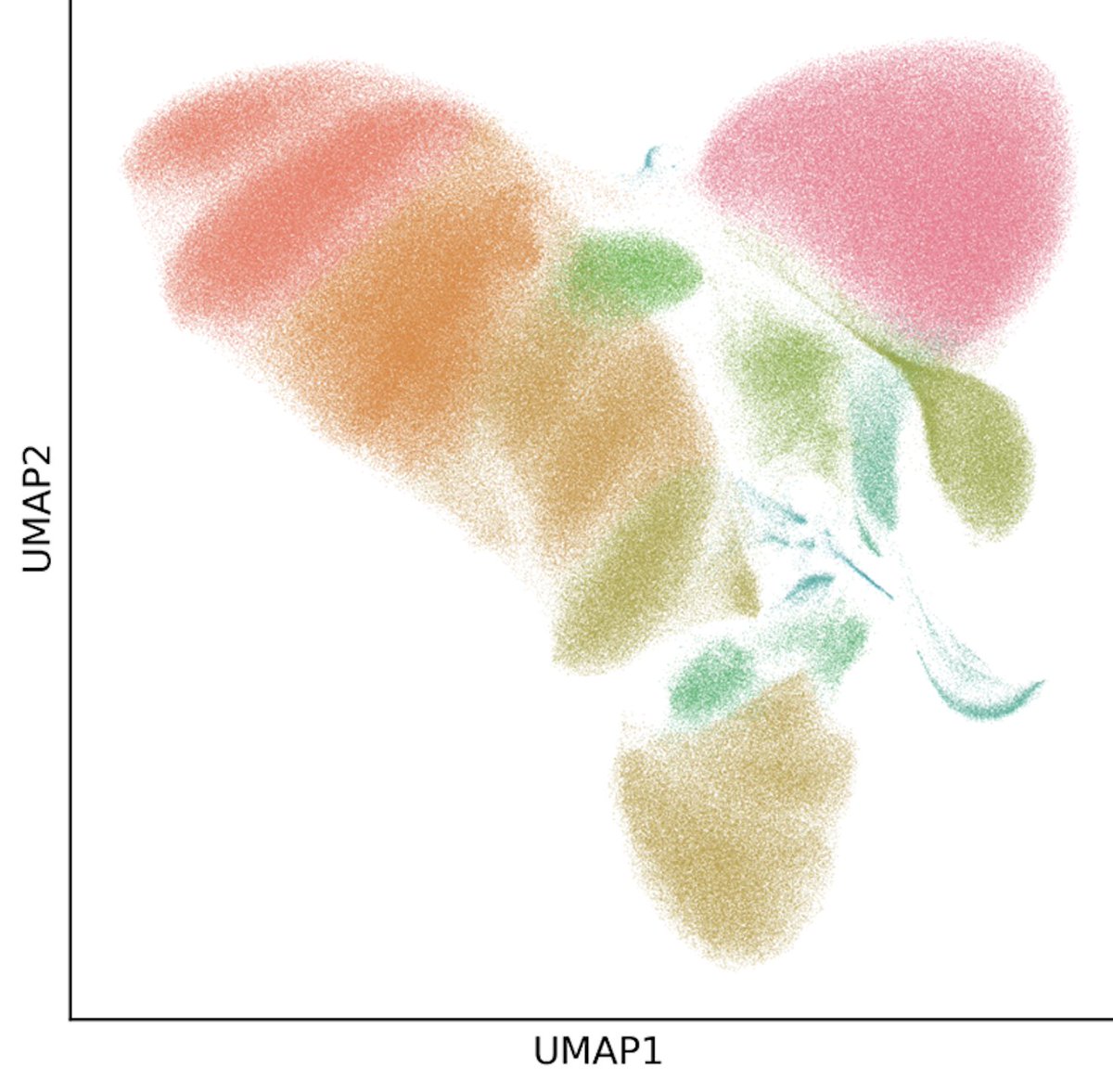
1/ We previously generated a 1M cell scRNA-seq dataset with 24 Type1 Diabetes/Control PBMC samples. Now Daniel Diaz, one of our Bioinformatics Application Scientists, has built a tutorial showing how you can easily analyze this dataset using existing single cell tools.
You can now do a deep dive into our 1 million cell T1D dataset! It was generated from 24 samples fixed over the span of 3 weeks and barcoded all together in a single run. The donor data was integrated with Harmony to generate the UMAPs. #singlecell https://t.co/deauJ5Gvtz
FYI this vignette has now been updated with some of our more recent recommendations for handling SPLiT-seq/ParseBio data with {alevin-fry}. Namely: it's important to quantify in U+S+A mode with a splici reference, and properly import all those counts into R with {fishpond}
First mega kit through @ParseBio and the sub library looks great after sequencing! So convenient to run sub libraries and know what’s going on before the big run. Estimating close to 900k cells for this exp!! Looking forward to the final results but so far so good.🤞🏼