@JinjingLiang What's your sense of quality vs. others after a handful of sessions?
Love how fast Gemini 3.5 Flash (Medium and High) runs in Antigravity CLI, much faster than Claude Code and Codex with any model at Medium. Quality seems pretty good across a few sessions, but still early, TBD.
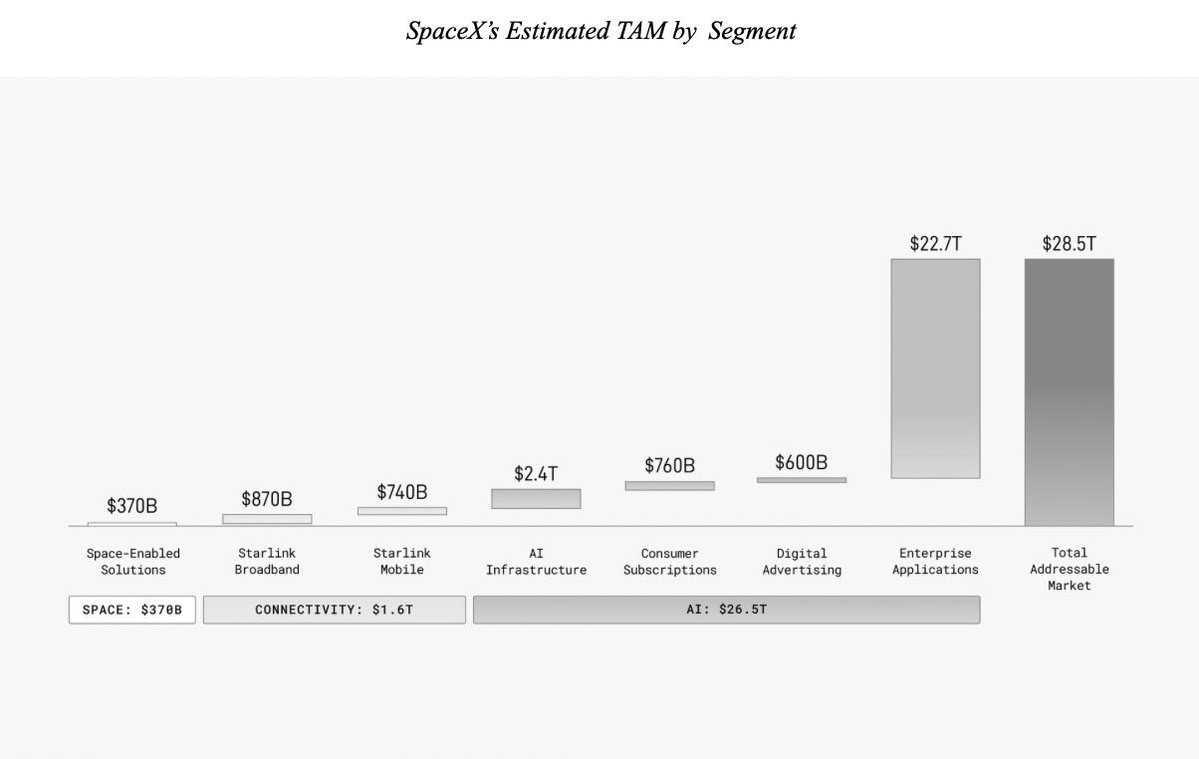
SpaceX drops the hypiest IPO filing and says "we believe we have identified the largest TAM in human history", and you're like, my interplanetary east India company, what delectable spice have you decided to ship across the stars, and it's like... 22 trillion dollars of b2b saas
One of the better descriptions of models’ extreme jaggedness:
“You're either in the data distribution (on the rails of the RL circuits) and flying, or you're off-roading in the jungle with a machete (in relative terms).”
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
Bare metal infra double backlog and growing 50%+ on multibillion scale.
Meanwhile, SaaS CFOs be like "well technically, our growth did not decelerate since if you round up the decimal of 9.55%, its basically 10% once you adjust for FX tailwinds"
It took us 47 iterations to stop one of our AI SDRs from being too aggressive on pricing. Not 3. Not 10. Forty-seven.
Each iteration required reviewing outputs, adjusting prompt instructions, testing again.
That's not a bug in AI GTM. That's the job.
The companies failing with AI agents are the ones who expected 2 iterations. The ones winning expected 50.
@paulg SF-LA overnight trips in AVs (“moving hotel rooms”) will be here years before CA completes even the first 1/10 of the promised high-speed rail line…
@paulg SF-LA overnight trips in AVs (“moving hotel rooms”) will be here years before CA completes even the first 1/10 of the promised high-speed rail line…
@mckaywrigley Same here, but I mean, definitely wouldn’t mind if they also improved Gemini CLI and fixed Google Workspace CLI while the stock price kept going up…
- New version of Claude Code desktop app is the first really good version -> finally starting to bring me over from terminal to desktop app. (Good UX for running multiple sessions in parallel with easy preview, terminal options for each is the key.)
some random ai thoughts:
- for code, i went from 80/20 claude/gpt to 80/20 gpt/claude in <3 months. surprised by this tbh, and interested to see where the split is at in another 3mo.
- claude still mogs gpt for non-coding agent stuff. codex feels like an engineer (which is great for coding!), whereas claude still feels like a general purpose coworker. gpt still lacks that coworker magic
- i’m pretty meh on opus 4.7. my experience hasn’t been *bad*, but it certainly hasn’t been good. sideways if anything.
- anthropic has got to figure out the compute thing. you can feel it as a user. vibes are all out of whack bc of it. my opinions above are all likely downstream of this. it’s an issue.
- anthropic labs continues to be the goat of ai product. claude design is another hit. it’s fantastic. idk why it’s not talked about more? a+
- updated claude code app is great. i finally switched out of the terminal for it. very well done.
- how are people STILL sleeping on the claude agent sdk? i feel like i’m going insane.
- gpt 5.5 is incredible. the level to which i trust it for engineering is amazing. if i could only have one model rn, it would be this one just bc of strong need for the coding use case.
- codex team is killing it. app has been the gold standard since 5.3 release (buuut i credit conductor team for the ui innovation that everyone is using now). though i could do with a little less passive aggressive shots at ant from the codex team. TARS, dial up class by 30%. it’s a long race guys haha
- i uninstalled cursor this month and am now back to vs code for my ide. composer just can’t hang with claude/gpt, and the product feels a bit all over the place. pretty stoked about the xai thing though, because their team is absolutely stacked and i’m excited to see what they might be able to do with that compute. codex and claude code are t1, cursor is t2. i would love if this deal got xai/cursor to t1 for a real trio there.
- gemini…? seems like this is 2-3 models now where the model seems like a great release and then nobody ever uses it? i’m bullish google/deepmind but weird it hasn’t translated to product use in any form. kinda disappointed still
- no open source models have hit the opus 4.5 level. was hopeful the new deepseek would get there, but nope. good oss agents will have to wait a few more months it would seem…
- Gemini/Google take nails the conflicted feeling:
"…? seems like this is 2-3 models now where the model seems like a great release and then nobody ever uses it? i’m bullish google/deepmind but weird it hasn’t translated to product use in any form. kinda disappointed still"