This paper studies real coding chats to show why Large Language Models, chatbots trained on text and code, miss instructions.
Only 24.07% of chats follow every instruction, and even single instructions are followed only 48.24% of the time.
Most coding benchmarks miss real back and forth, so the authors pull coding conversations from large public chat logs and label what happens.
They treat each thread as connected turns, and the structure usually looks linear, star like, or tree like.
Linear threads fit step by step code polishing, star threads fit quick information queries, and tree threads fit big design work that splits into sub problems.
Bug fixing and refactoring are where the model slips most, because the answer must obey many small constraints at once across several turns.
Satisfaction drops as threads get longer, since the chat often turns into a loop of error spotting and patching instead of steady progress.
People seem happier with structured knowledge questions and algorithm design, and less happy with code generation and code cleanup where mistakes block them.
----
Paper Link – arxiv. org/abs/2512.10493
Paper Title: "Decoding Human-LLM Collaboration in Coding: An Empirical Study of Multi-Turn Conversations in the Wild"
Reasoning models are expensive.
Not because the models are huge.
It's because they generate thousands of tokens just to think.
But what if smaller models could learn to reason efficiently?
This new paper compares training 12B models on reasoning traces from two frontier systems:
- DeepSeek-R1
- gpt-oss (OpenAI's open-source reasoner)
The key finding: gpt-oss traces produce 4x more efficient reasoning. DeepSeek-R1 averages ~15,500 tokens per response. gpt-oss averages ~3,500 tokens.
Yet accuracy stays nearly identical across benchmarks. Verbose reasoning doesn't mean better reasoning.
Why does this matter?
Inference cost scales linearly with tokens. If your reasoning model generates 4x fewer tokens with the same accuracy, you cut costs by 75%.
That's a massive efficiency gain.
Interesting observation: Nemotron base models already had DeepSeek-R1 traces in pretraining. Training loss on DeepSeek traces started low and stayed flat. Training loss on gpt-oss traces started high and dropped gradually.
They showed that the model was learning something new, which also means you can distill reasoning capabilities from frontier models into smaller systems. But the source matters. Different reasoning styles produce different efficiency profiles.
(bookmark it)
Paper: arxiv. org/abs/2511.19333
Enhancing Reasoning to Adapt Large Language Models for Domain-Specific Applications
Regardless of how generalized LLMs are becoming, there is still a lot of interest in adapting LLMs for specialized domains.
Researchers from IBM and MIT-IBM Watson AI Lab introduce SOLOMON, a neuro-inspired reasoning network that enhances LLM adaptability for specialized tasks.
Key insights include:
• Enabling flexible domain adaptation – Unlike traditional fine-tuning, SOLOMON uses a multi-agent oversight system with prompt engineering and in-context learning to adapt LLMs efficiently across domains without retraining.
• Improving spatial reasoning in LLMs – Standard LLMs struggle with spatial reasoning and applying domain knowledge. SOLOMON addresses this by integrating multiple LLMs to generate diverse reasoning paths, refining them through a Thought Assessor mechanism inspired by the Free Energy Principle.
• Significant performance gains – Evaluations on 25 semiconductor layout design tasks show SOLOMON outperforms baseline LLMs and achieves results comparable to state-of-the-art reasoning models like OpenAI’s o1-preview. It notably reduces runtime errors and improves reasoning accuracy.
My talk on finding security vulnerabilities by combining classical symbolic reasoners with modern-day LLMs:
Recording: https://t.co/BHzt7Y6EiZ
Slides: https://t.co/TtmPZxzs7v
I gave this talk yesterday at the 2024 Static Analysis Symposium in Pasadena, California.
Finding security vulnerabilities is a grand challenge in static analysis. I talked about three kinds of approaches:
➡️ classical symbolic reasoning which has dominated for much of the history of the field;
➡️ modern-day LLMs which excel at many code-reasoning tasks and are rapidly improving; and
➡️ neuro-symbolic approaches, which combine the best of both worlds and are the focus of my group's research ).
My favorite illustration, originally due to Hyung Won Chung from OpenAI, puts these approaches in perspective. He argues how with less compute, an approach with more structure wins over an approach with less structure, but as the available compute grows, the former saturates in performance but the latter keeps improving.
The question then is: would approaches with even less structure be even more scalable? Not necessarily: it depends on how much compute we have today. If we are at the dotted line, then "even less structure" doesn't make sense, but we should remember to undo the structure already present when more compute becomes available tomorrow.
So when I reflect upon my own research over the last decade which developed approaches with a lot of structure, it was the right thing to do at the time. But today we should be careful not to repeat yesterday's approaches -- rather we should determine what parts of the structure in those approaches are still needed, and remember to remove them tomorrow.
In the setting of security vulnerabilities, the attached picture shows how our recent neuro-symbolic approach IRIS divides this challenging problem into parts that an LLM like GPT-4 is good at today (e.g. inferring missing specifications and contextual analysis) and what a classical symbolic reasoning tool like CodeQL is good at (e.g. whole-repository taint tracking).
Thanks to the SAS'24 chairs Roberto Giacobazzi and Alessandra Gorla for inviting me, and to the many who attended including Patrick Cousot, Francesco Logozzo, Anders Møller, and Kwangkeun Yi (apologies to those whose names I missed!). Thanks also to the SPLASH organizers for an excellent job hosting the conference.
Textbooks Are All You Need II
Presents phi-1.5, a new 1.3 billion parameter model trained on 30 billion tokens. The dataset consists of "textbook-quality" synthetically generated data.
phi-1.5 competes or outperforms other larger models on reasoning tasks suggesting that data quality plays a more important role than previously thought.
The authors claim that phi-1.5 is the first LLM at the 1B scale to exhibit most of the relevant traits of larger LLMs.
The model is open-sourced to encourage research around in-context learning, mechanistic interpretability, and safety topics such as hallucinations and toxicity.
paper: https://t.co/U4iNWPW7g7
model: https://t.co/4Vppq0ylmc
If you are still confused by all the benchmarks and evaluation pipelines for LLMs, you should definitely watch @dk21 latest video from the LLM fine-tune course.
https://t.co/ww8JxYsJNh
He covers all the standard used benchmarks, like HumanEval, HellaSwag, ARC and standard metrics like Bleu, rouge, etc...
You will finally understand what it means to be at the top of an OSS leaderboard and the caveats about it.
In the next lesson @jefrankle will talk about dataset processing and curation!
Code Llama was just released 4 days ago. Since then, we already got
1) WizardCoder-34B (https://t.co/WDd94tt3fG)
2) Phind's finetuned CodeLLama-34B (https://t.co/FGtnv2w7xy)
*Both reported to be surpassing GPT-4 on HumanEval.
The open source community is amazing!
🔥🔥🔥
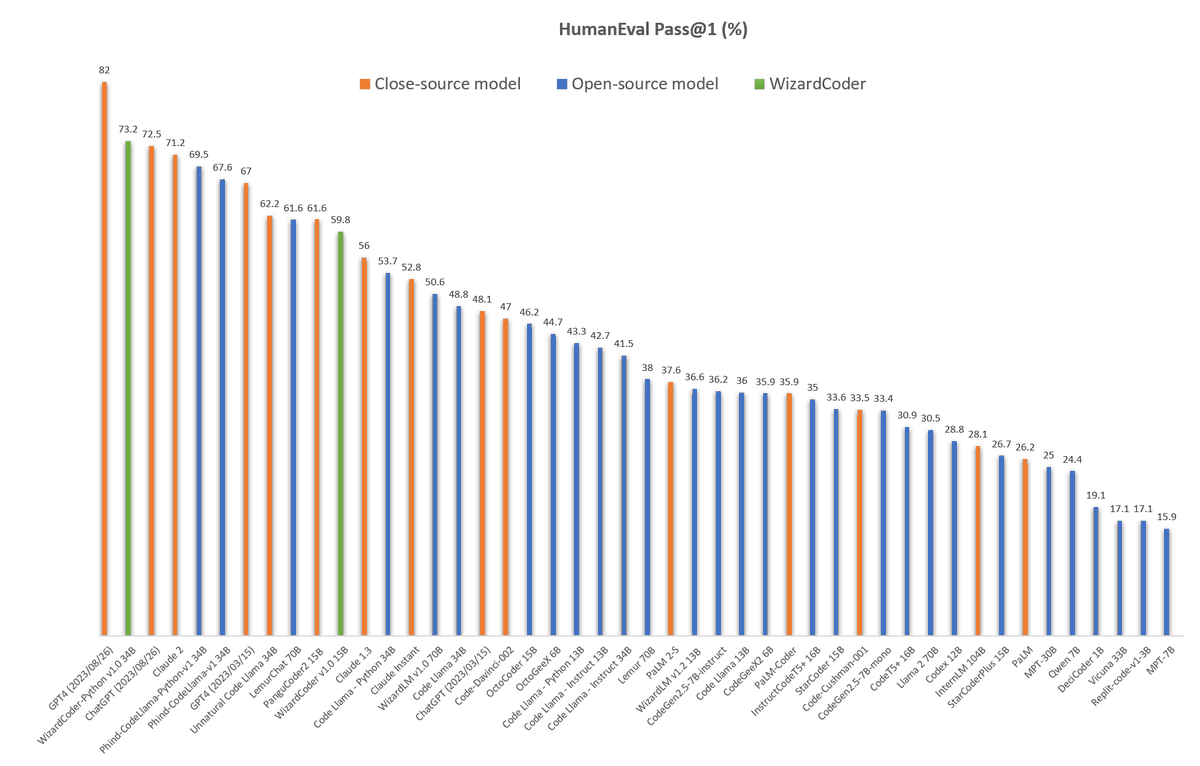
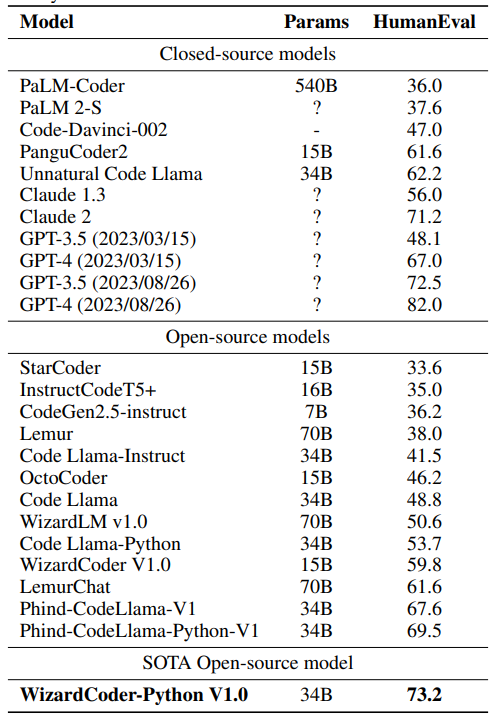
Introduce the newest WizardCoder 34B based on Code Llama.
✅WizardCoder-34B surpasses GPT-4, ChatGPT-3.5 and Claude-2 on HumanEval with 73.2% pass@1
🖥️Demo: http://47.103.63.15:50085/
🏇Model Weights: https://t.co/3jrdUMYPFz
🏇Github: https://t.co/AY7ECXenfT
The 13B/7B versions are coming soon.
*Note:
There are two HumanEval results of GPT4 and ChatGPT-3.5:
1. The 67.0 and 48.1 are reported by the official GPT4 Report (2023/03/15) of OpenAI.
2. The 82.0 and 72.5 are tested by ourselves with the latest API (2023/08/26).
AgentBench: Evaluating LLMs as Agents
paper page: https://t.co/r9ipiPnbfs
Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation.
The recording of my talk "Unveiling Secrets in Binaries using Code Detection Strategies" at @reconmtl is now online. It covers strategies to explore unknown, large binaries.
Recording: https://t.co/pmpBRoUO6z
Slides: https://t.co/ibeUOsfsee
Code: https://t.co/wWPTnvRHvJ
its almost like.. embeddings was compression the whole time.
wordcount is a embedding and a compression that loses position sensitive to common words
tdidf is an embedding and its a compression that is insensitive to document frequency
gzip is an embedding like tfidf
but contains positional information and a has a tokenizer.
Absolutely love this.
You want to visualize your firmware binaries and their interaction? Use our new tool Pyrrha, introduced by @_cryptocorn_ during @passthesaltcon#pts23 https://t.co/vd4cAZXPYA
✨👩💻 Our @DeepMind Code AI team delivered a presentation this morning about the work we've done internally and externally—and the path for reinventing what it means to do software development and creative technical work in the age of generative models.
🤖 RL and generative models combined have massive potential for creators: and there has never been a more capable group to build and implement this vision. ✨
Very excited for the years to come! 🙌🏻
If you're curious about what we've been working on, a small fraction of our research and applied work can be found in the links below:
• Large sequence models for software development activities https://t.co/gVm8vHtYQ3
• Understanding HTML with Large Language Models https://t.co/hp1OlaB35A
• Natural Language to Code Generation in Interactive Data Science Notebooks https://t.co/apiSxNZxAh
• ML-Enhanced Code Completion Improves Developer Productivity https://t.co/fHyPl3J9C7
• Code as Policies: Language Model Programs for Embodied Control https://t.co/AWo2eVfDFH
• Learning Performance-Improving Code Edits https://t.co/jFdPZ35VTJ
• Generative Agents: Interactive Simulacra of Human Behavior https://t.co/hhlwioR83m
• AlphaDev discovers faster sorting algorithms https://t.co/Ea1RXVywlG
• Competitive programming with AlphaCode https://t.co/HlxXfOOWfv
• Baldur: Whole-Proof Generation and Repair with Large Language Models https://t.co/FrAbfvFyP0
...and more.
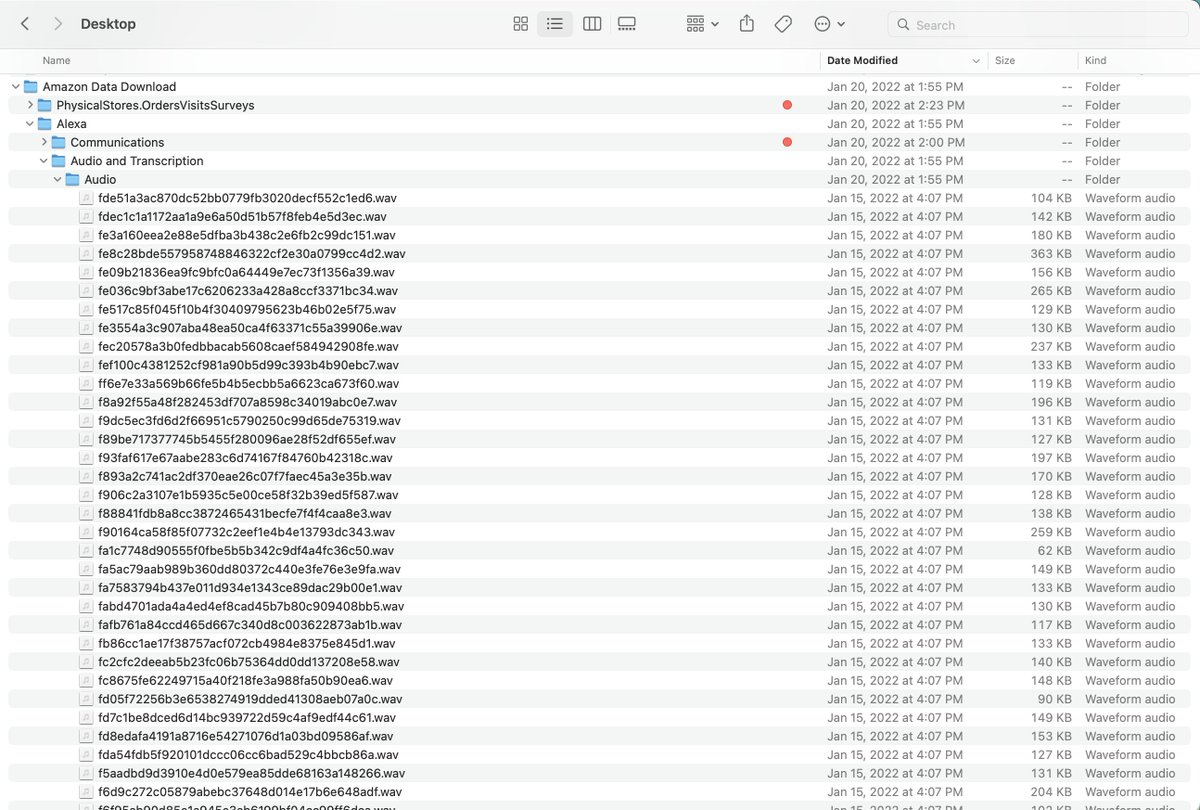
I downloaded all the data Amazon has on me, and honestly the creepiest thing about it is that they sent me the *actual audio files* of every time I spoke* to Amazon Alexa
*years ago when I was young and foolish about surveillance
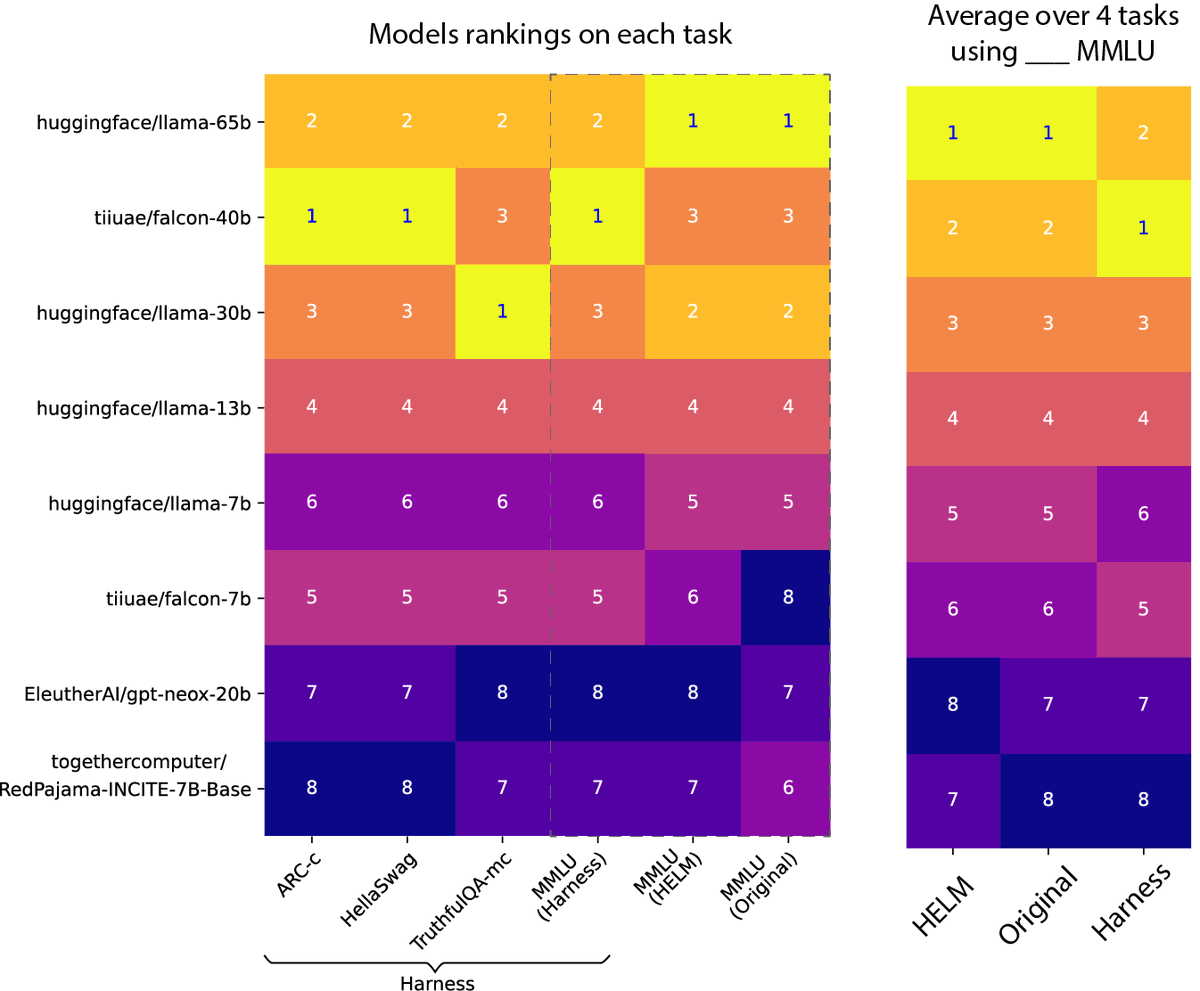
What was going on with the Open LLM Leaderboard?
Its numbers didn't match the ones reported in the LLaMA paper!
We've decided to dive in this rabbit hole with friends from the LLaMA & Falcon teams and got back with a blog post of learnings & surprises: https://t.co/bREo0oiQ01
Fine-tuned performance without a step of SGD?
Excited to share TART, which transplants transformer-based reasoning modules on arbitrary foundation models to improve in-context learning performance!
📜 https://t.co/bYtxGvfern
💻 https://t.co/nKcrMXWH1F
✍️ https://t.co/7tjSqQLzvm
I often get requests to dispel some of the jargon behind transformers and LLMs!
So here we go, my new article on "Understanding Encoder and Decoder LLMs":
https://t.co/muow0Kew8d