Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
We just published internal data on how much of Claude's development is already being done by Claude:
- Over 80% of all code merged into our codebase is now written by Claude
- It's been months since many researchers at Anthropic hand-wrote code
- The typical Anthropic engineer ships 8x as much code as they did in 2024
- On the most open-ended engineering tasks, Claude's success rate jumped from ~26% to 76% in 6 months
- When research sessions went off-track, Claude proposed a better next step than the human took 64% of the time
We're not at recursive self-improvement yet, but it could come sooner than most expect. I highly recommend reading the full blog post.
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
We’ve added a CLI for Claude Platform to make every API endpoint runnable from your terminal.
Call the Messages API, stand up Claude Managed Agents, pipe results straight into your shell.
The ant CLI is well understood by coding agents (Claude Code) using the claude-api skill.
BREAKING: Ideogram 4.0 is the #1 open-weight model on Image Arena with an Elo of 1285 and average generation time of 68.7 seconds.
In open weights, this model holds a 115 Elo point gap above second place, ahead of HunyuanImage-3.0 by @TencentHunyuan and FLUX.2 [dev] by @bfl_ai. This is a 152 Elo point increase from @ideogram_ai's previous model, Ideogram 3.0, placing it in the same performance band as Gemini 3.0 Pro Image Gen 2k and Gemini 3.1 Flash Image Gen by @GoogleDeepmind.
Ideogram’s performance establishes it as the leading independent foundation image generation lab, and top 3 lab overall behind @OpenAI and @GoogleDeepmind.
Huge congratulations to the @ideogram_ai team on the launch!
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: https://t.co/v65eop5Ixq
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Anthropic has confidentially submitted a draft S-1 registration statement to the Securities and Exchange Commission.
Pending completion of SEC review, this gives us the option to pursue an initial public offering.
Read more: https://t.co/onGZAhRLvD
Composer 2.5 is now available inside Grok Build.
Composer 2.5 is a fast, highly intelligent model that excels on long-running tasks and following complex instructions.
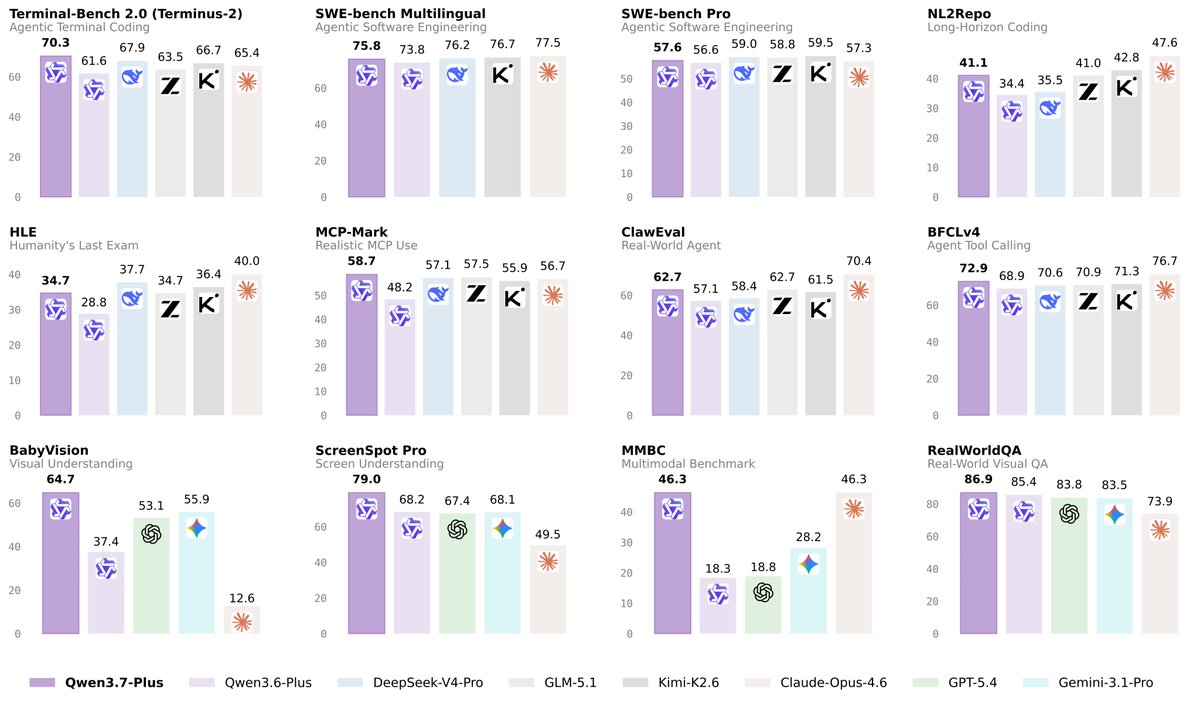
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
We have been working closely with @nvidia to ensure Hermes Agent works smoothly on their new @NVIDIARTXSpark superchip and integrates with the new OpenShell runtime, which connects Hermes to @Microsoft's security primitives.
Watch our feature in the big announcement at Computex:
Welcome to the NVIDIA RTX Spark channel.
A new superchip for the age of personal AI.
Don't worry, your favorite NVIDIA local AI content continues on right here, just with a new headliner.
Let's get started...
Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
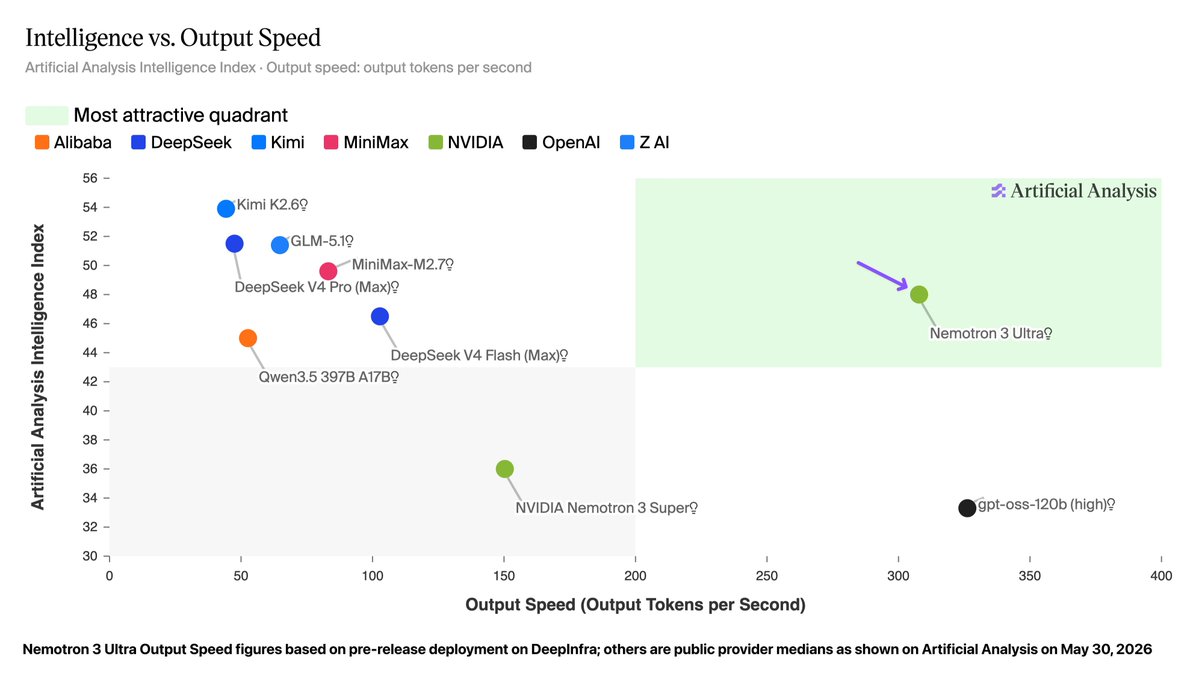
NVIDIA just announced the release of Nemotron 3 Ultra in Jensen Huang's Computex keynote: at 550B parameters (55B active), this is the largest Nemotron 3 model to date, and it is the most intelligent US open weights model
We partnered with @nvidia to evaluate this model for intelligence and speed - these figures use the model’s BF16 weights, but as with Nemotron 3 Super the model will be made available in NVFP4 quantization as well for higher inference performance.
➤ New leader for US open weights intelligence: Nemotron 3 Ultra scores 48 on the Artificial Analysis Intelligence Index. This is well ahead of the next strongest US open weights models, Gemma 4 31B (39), Nemotron 3 Super (36) and gpt-oss-120b (33), but behind the Chinese-led open weights frontier (Kimi K2.6 at 54).
➤ Leading speed for its intelligence: on a pre-release @DeepInfra endpoint, Nemotron 3 Ultra served over 300 tokens per second. Peer models in its size class from China-based labs such as DeepSeek and Moonshot (Kimi) are generally served at speeds of 50-100 tokens per second in the market today. gpt-oss-120b is served at speeds similar to this level, but with significantly lower intelligence.
➤ Largest Nemotron 3 model so far: at approximately 550 billion total parameters and 90% sparsity, Nemotron 3 Ultra is significantly larger than its siblings and is the largest recent US open weights model release
We’ll be sharing additional analysis and full benchmarks at release.
Anthropic CEO Dario Amodei:
"The cheapest way to use Claude is also the smartest. Most devs do the exact opposite."
In 36 minutes, he breaks down the real economics behind every Claude model, and why running them all the same way is a mistake.
Watch the full interview, then save the config below 👇






















![Designarena's tweet photo. BREAKING: Ideogram 4.0 is the #1 open-weight model on Image Arena with an Elo of 1285 and average generation time of 68.7 seconds.
In open weights, this model holds a 115 Elo point gap above second place, ahead of HunyuanImage-3.0 by @TencentHunyuan and FLUX.2 [dev] by @bfl_ai. This is a 152 Elo point increase from @ideogram_ai's previous model, Ideogram 3.0, placing it in the same performance band as Gemini 3.0 Pro Image Gen 2k and Gemini 3.1 Flash Image Gen by @GoogleDeepmind.
Ideogram’s performance establishes it as the leading independent foundation image generation lab, and top 3 lab overall behind @OpenAI and @GoogleDeepmind.
Huge congratulations to the @ideogram_ai team on the launch!](https://pbs.twimg.com/media/HJ5qOUcakAA9Ydw.jpg)