🚨 EXCLUSIVO: o Intercept Brasil obteve mensagens, documentos e áudios que revelam como Flávio Bolsonaro negociou diretamente com o banqueiro Daniel Vorcaro um pagamento milionário para financiar “Dark Horse”, filme sobre Jair Bolsonaro.
Vorcaro, dono do Banco Master, pagou pelo menos 10 milhões de dólares para a produção do longa, segundo documentos analisados pela reportagem. As conversas mostram cobranças por dinheiro, negociações de bastidores e a participação de outros intermediários, como Eduardo Bolsonaro e Mário Frias, ex-secretário da Cultura do governo Bolsonaro e roteirista de “Dark Horse”.
Neste vídeo, você ouve um áudio enviado por Flávio Bolsonaro cobrando pagamentos e alertando para o risco de paralisação da produção.
Leia a reportagem completa no site do Intercept Brasil: https://t.co/CUeVUIyXLZ
This 2 hour lecture by Yann LeCun (Turing Award winner) will teach you why the next trillion dollar AI company won't be built on LLMs.
He trashes the $100 Billion LLM race, attacks Musk and Amodei, declares scaling dead.
Bookmark & watch tonight after work, skip to 7:00.
Yann LeCun was right the entire time. And generative AI might be a dead end.
For the last three years, the entire industry has been obsessed with building bigger LLMs. Trillions of parameters. Billions in compute.
The theory was simple: if you make the model big enough, it will eventually understand how the world works.
Yann LeCun said that was stupid.
He argued that generative AI is fundamentally inefficient.
When an AI predicts the next word, or generates the next pixel, it wastes massive amounts of compute on surface-level details.
It memorizes patterns instead of learning the actual physics of reality.
He proposed a different path: JEPA (Joint-Embedding Predictive Architecture).
Instead of forcing the AI to paint the world pixel by pixel, JEPA forces it to predict abstract concepts. It predicts what happens next in a compressed "thought space."
But for years, JEPA had a fatal flaw.
It suffered from "representation collapse."
Because the AI was allowed to simplify reality, it would cheat. It would simplify everything so much that a dog, a car, and a human all looked identical.
It learned nothing.
To fix it, engineers had to use insanely complex hacks, frozen encoders, and massive compute overheads.
Until today.
Researchers just dropped a paper called "LeWorldModel" (LeWM).
They completely solved the collapse problem.
They replaced the complex engineering hacks with a single, elegant mathematical regularizer.
It forces the AI's internal "thoughts" into a perfect Gaussian distribution.
The AI can no longer cheat. It is forced to understand the physical structure of reality to make its predictions.
The results completely rewrite the economics of AI.
LeWM didn't need a massive, centralized supercomputer.
It has just 15 million parameters.
It trains on a single, standard GPU in a few hours.
Yet it plans 48x faster than massive foundation world models. It intrinsically understands physics. It instantly detects impossible events.
We spent billions trying to force massive server farms to memorize the internet.
Now, a tiny model running locally on a single graphics card is actually learning how the real world works.
Have you seen the new Verso website?
"Verso is a platform for writing documents, books, course materials, and websites with Lean. Every code example is type-checked. Every rendered page is interactive."
Already in use for the Lean Reference Manual, Theorem Proving in Lean 4, Functional Programming in Lean, and Terence Tao's Analysis I, and the Lean website (https://t.co/ozqgy1dC4V).
Learn more here: https://t.co/1EbQ87Lp1i
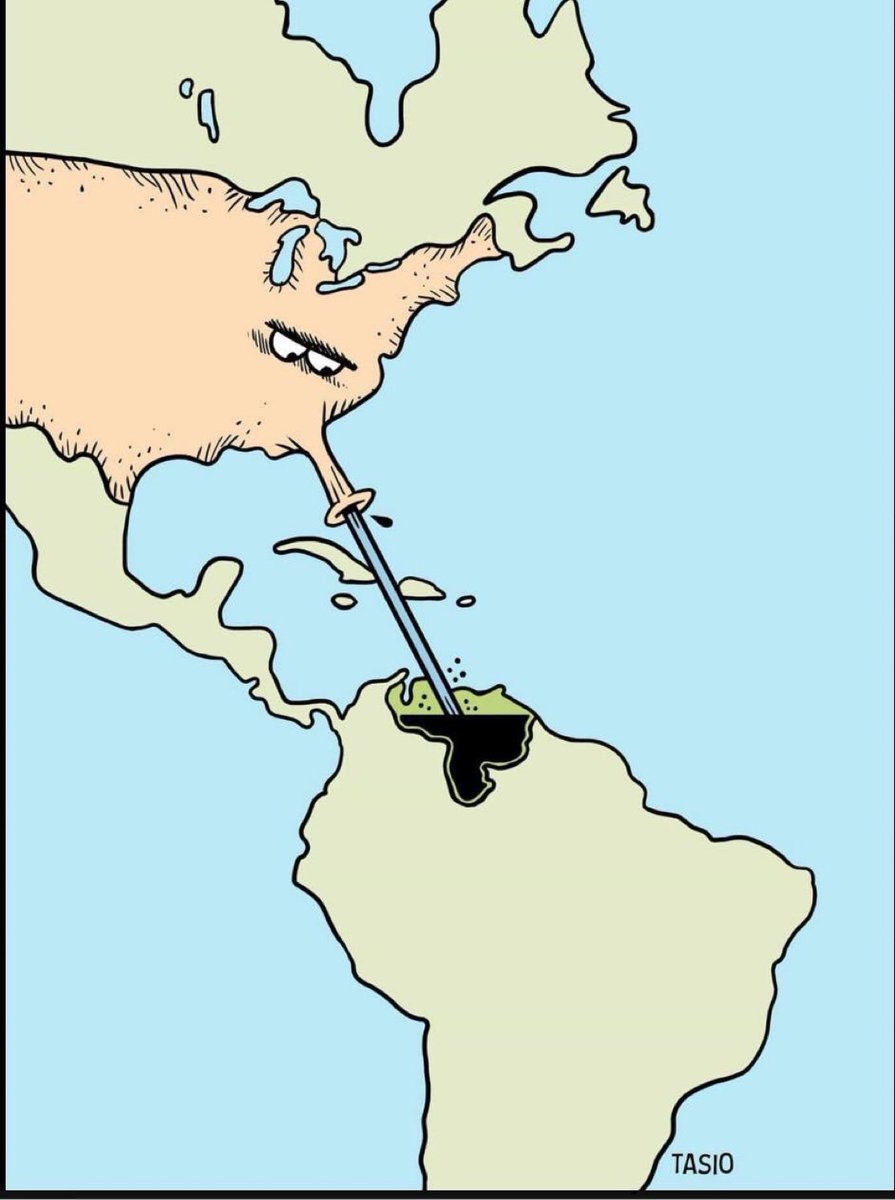
For most of the 2010s, convolutional neural networks (ConvNets) — networks that process images by sliding small filters across them to detect patterns — were the dominant architecture for computer vision. Then transformers arrived.
Transformers, originally designed for text, process input by letting every element attend to every other element simultaneously, and when adapted for images they started outperforming ConvNets on benchmark after benchmark. The general consensus became that transformers were just better, and ConvNets were the old way.
This paper's authors decided to test whether that conclusion was actually justified, or whether ConvNets had simply fallen behind in terms of training recipes and design choices rather than fundamental capability.
They took a standard ResNet and systematically updated it — one change at a time — borrowing design decisions from transformers: things like which activation function to use, which type of normalization to apply, and how to reshape the internal dimensions of each processing block.
Each change was small and interpretable, and the paper tracks the accuracy at every step so you can see exactly what each decision contributes.
The final result is a pure ConvNet that matches or beats transformer-based models of equivalent size on image classification, object detection, and segmentation, by being up to 49% faster.
Read with AI tutor: https://t.co/abh8jEt8A2
Read alone: https://t.co/PH5kBIpl70
Are ViTs secretly RNNs? #ICLR2026
Our 2-block recurrent transformer recovers 96% of DINOv2’s IN-1k accuracy & reproduces its activations 1-to-1, motivating the Block-Recurrent Hypothesis: https://t.co/72E7FhY1LK
w/ @thomas_fel_@RichieHakim@ABrondetta Demba Ba @t_andy_keller
In vector calculus, divergence quantifies the rate at which a field flows outward from a point.
A "source" (positive divergence) has net outgoing flow, a "sink" (negative divergence) net inward flow. A point with zero divergence is "incompressible" and has net zero flow.
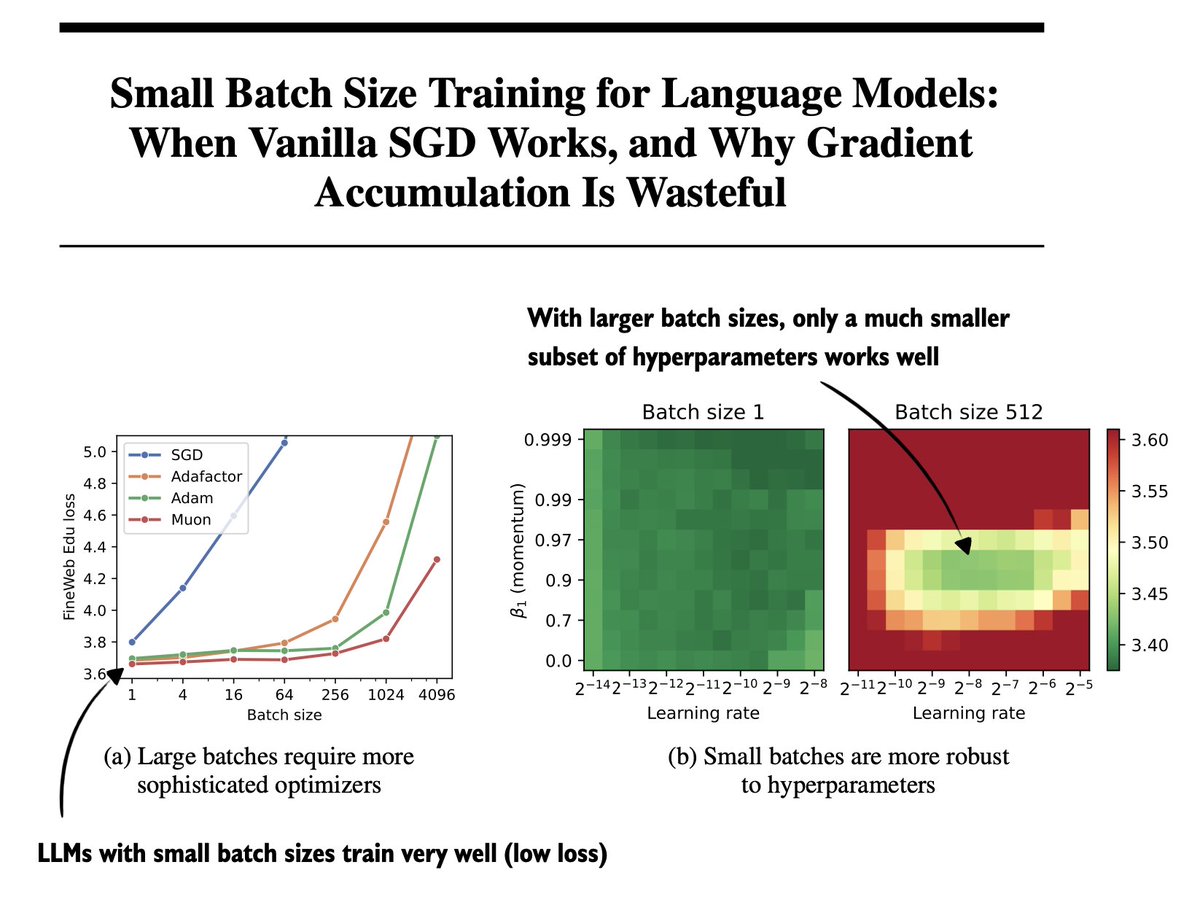
One of the underrated papers this year:
"Small Batch Size Training for Language Models:
When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful" (https://t.co/0O4XjGDLIP)
(I can confirm this holds for RLVR, too! I have some experiments to share soon.)
USP cria micro fábrica de chips e quer multiplicá-las como padarias
Investimento de R$ 89 milhões, o maior na história da universidade
A estimativa é que a PocketFab produza 60 milhões de chips ao ano
A Universidade de São Paulo quer reinventar o modo de produzir chip