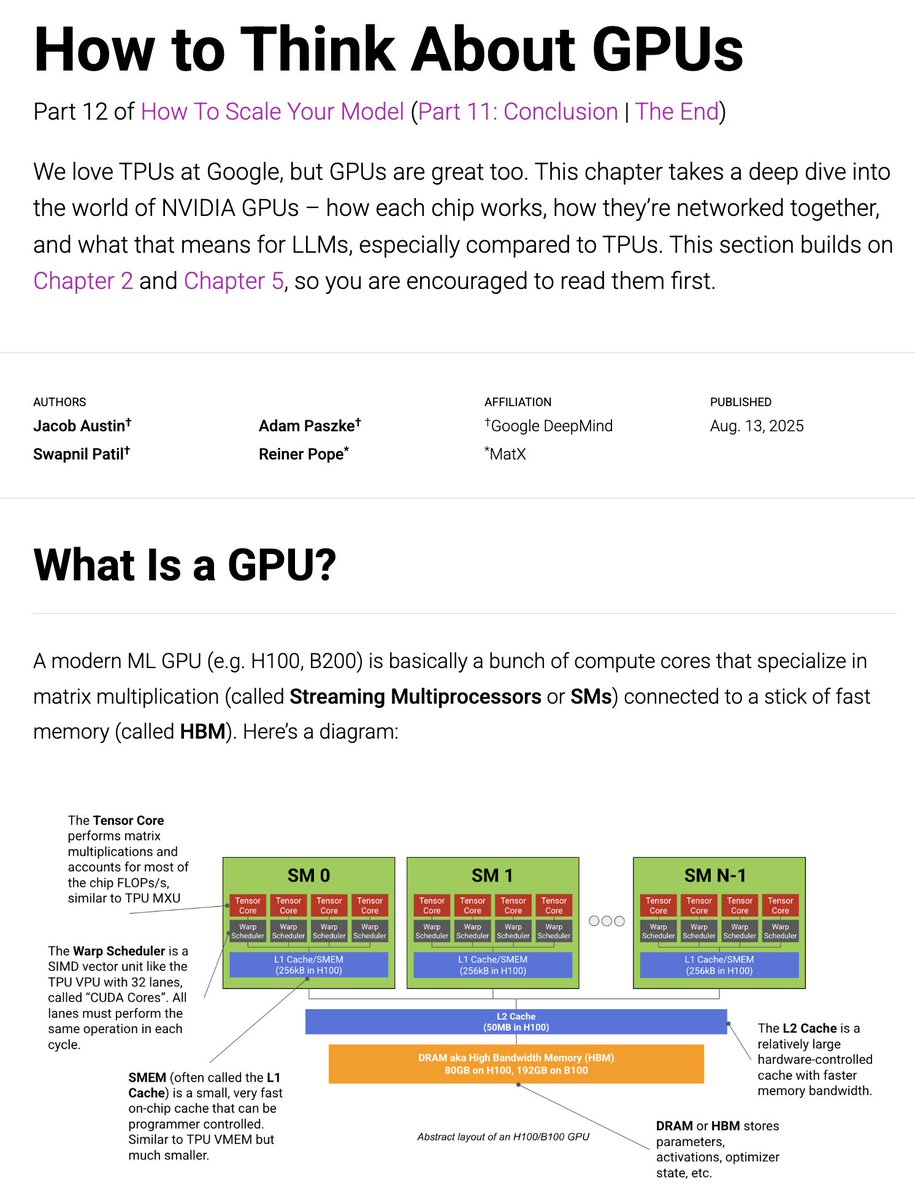
Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n
One of the most important papers in AI: a tiny brain-inspired 27M param model trained on 1000 samples outperforms o3-mini-high on reasoning tasks!
Still can't believe this tiny lab of Tsinghua grads gets 40% on ARC-AGI, solves hard sudoku and mazes.
We're still so early.
Excited to share I’ve joined @WaveFormsAI as Member of Technical Staff! Grateful to be working with a lean, talented team on ambitious challenges. Huge thanks to my amazing teammates at @amazon AGI for nearly 3 years of learning, building, and growth.
🚀 Introducing BLIP3-o: A Family of Fully Open Unified Multimodal Models https://t.co/Gk6X5uEbzl
🔓 Attempting to unlock GPT-4o’s image generation.
Open source everything!
Including 25 million pre-training data!
Exciting times in 3D computer vision! Gaussian Splatting (3DGS) merges with the classic SLAM framework, perfectly balancing ⏱️ real-time efficiency with 🖼️ photorealistic detail. This marks a full-circle evolution in 3D computer vision 🔄, integrating elements from SLAM, Deep SLAM, NeRF, to 3DGS, culminating in the cutting-edge 3DGS SLAM. #3DTechnology #nerf #GaussianSplatting
Happy to share Gaussian Splatting SLAM
https://t.co/3VCrAeDfZ4
We show the first 3DGS-based Monocular RGB SLAM, the hardest SLAM setting.
Using 3D Gaussians as a unified representation, the method only requires RGB images - No need for SfM, depth sensor, or learned prior.
🌐 NeRF Video (or 4D content) technology could revolutionize how we interact with digital content. 🚀 It opens up possibilities for a new kind of social media, transcending traditional image and video platforms. Imagine its impact on areas where perspective is key, like sports 🏀, dance 💃, and scene inspection 🔍. The big question remains: Will we lean towards dedicated VR/AR devices 🕶️, or could a simple joystick 🎮 and TV 📺 setup be enough? #NeRFVideo #FutureOfMedia
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
paper page: https://t.co/gUtjOCyRER
Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.
@KostasPenn Truly impressive results! It's fantastic to witness such seamless real-time performance. I look forward to reading the paper!!
P.S.: This particular sequence caught my eye, reminiscent of my days at Prof. Yiannis' lab at UMD - bringing back great memories of grad school.
The way people interact with the computer is going to change.
I am working on LLM controller for your Mac
Inspired by LLM OS (@karpathy)
But I think LLM first OS will come in 1-2 years.
We need intermediate step of Expanded /w LLM OS first. This is how we get there.
Search for collaborators…
You can now operate robots by just thinking about it. With your brain signals. WOW.
This robot system from Stanford has so much sci-fi vibe and wild implications that I don't even know where to start.
NOIR decodes the EEG signal from your head into a library of robot skills. It is demonstrated on 20 household activities, such as cooking Sukiyaki, ironing clothes, grating cheese, playing Tic-Tac-Toe, and even petting a robot dog!
NOIR learns to predict your intended goals in advance, so that your thinking efforts (literally) can be reduced to a minimum. It works with both adults and children as young as five years old.
Imagine scaling up this system to @neuralink + Humanoid robots like @Tesla_Optimus in the future! There's now a decent probability that we can see the movie Avatar become a reality in our lifetime.
Website: https://t.co/PNal9WNBC5
Paper: https://t.co/3uJL00QK3o
This work is from Stanford Vision Lab, my PhD home. The project is led by @RuohanZhang76 and advised by @drfeifei@jiajunwu_cs. Congrats on the phenomenal idea!
There is a new 3D generative model in town: Genie by @LumaLabsAI. This model is surprisingly good and insanely fast! As someone who has worked on 3D generative modeling, here are my observations and guesses about how this system works (without any insider info):
Truly incredible!! Immersive Reality (like VR and XR) bridges the gap between dreams and reality, turning distant imaginations into tangible experiences.
Today I’m launching Open Interpreter, an open-source Code Interpreter that runs locally.
Summarize PDFs, visualize datasets, and control your browser — all from a ChatGPT-like interface in your terminal.
● https://t.co/6QVoJHfwhl
$ pip install open-interpreter
$ interpreter
AI continues to make unbelievable advances in healthcare.
Researchers have just created a brain implant that decodes thoughts into synthesized speech allowing paralyzed patients to communicate through a digital avatar.
This is incredible:
-The implant converts brain signals into text at nearly 80 words per minute, focusing on phonemes vs. whole words to enhance speed.
-The AI generates realistic vocals (mirroring a patient’s pre-injury voice) and facial animations that aim to enable more natural communication.
-The breakthrough brings the tech closer to real-world use, with the next step being a wireless model that doesn’t require a physical connection to the interface.
Restoring communication for those with paralysis is an innovation that would change countless lives.
While it sounds crazy, mind-reading implants seem to be inching closer to reality.
3D-LLM: Injecting the 3D World into Large Language Models
Takes 3D point clouds and their features as input and perform a diverse set of 3D-related tasks.
proj: https://t.co/VUoEHZCqEd
abs: https://t.co/SC2aa7XgQ3
Imagine a future where EEG AirPods, Vision Pro & the Watch form a full mental health monitor kit! The data captured could unlock brain mysteries & potentially cure cognitive disorders. #MentalHealthTech#BrainHealth 🧠🎧⌚️
🧠🤖 The future of brain-machine interfaces and AI?
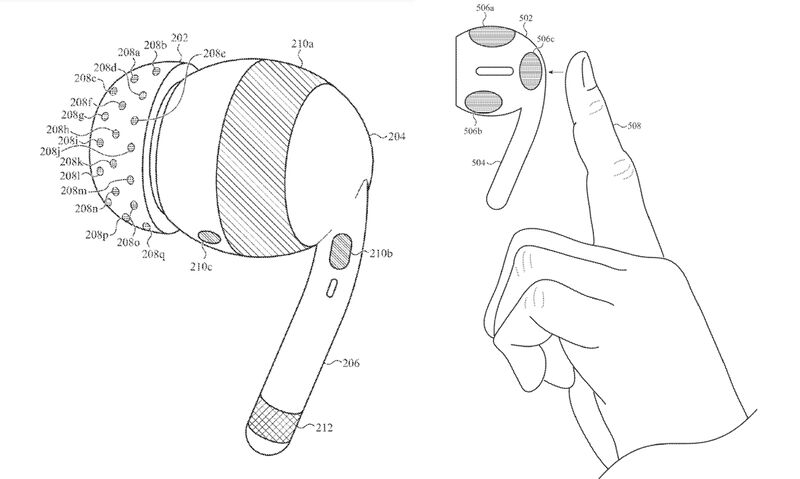
NEW patent by Apple published this week: EEG-integrated AirPods.
Abstract: A wearable electronic device includes a housing, and an electrode carrier attached to the housing and having a nonplanar surface. The wearable electronic device includes a set of electrodes, including electrodes positioned at different locations on the nonplanar surface. The wearable electronic device includes a sensor circuit and a switching circuit. The switching circuit is operable to electrically connect a number of different subsets of one or more electrodes in the set of electrodes to the sensor circuit.
Patent US-20230225659-A1: