You should really try out herdr + moshi. I can start work from my desktop with herdr, then just connect with moshi. now I have two synchronous working enviro. I can continue my work from any side. On my desktop or from my mobile while outdoor.
@AnthropicAI We create LLM by distill the knowledge of all mankind, but we forbid others distill from our work. Funny 😄. So our work is not part of mankind’s knowledge?
Introducing Flue — The First Agent Harness Framework
Flue is a TypeScript framework for building the next generation of agents, designed around a built-in agent harness.
Flue is like Claude Code, but 100% headless and programmable. There's no baked in assumption like requiring a human operator to function. No TUI. No GUI. Just TypeScript.
But using Flue feels like using Claude Code. The agents you build act autonomously to solve problems and complete tasks. They require very little code to run. Most of the "logic" lives in Markdown: skills and context and AGENTS.md.
Flue is like Astro or Next.js for agents (not surprising, given my background 🙃). It's not another AI SDK. It's a proper runtime-agnostic framework. Write once, build, and deploy your agents anywhere (Node.js, Cloudflare, GitHub Actions, GitLab CI/CD, etc).
We originally built Flue to power AI workflows inside of the Astro GitHub repo. But then @_bgiori got his hands on it, and we realized that every agent needs a framework like Flue, not just us.
Check it out! It's early, but I'm curious to hear what people think. Are agents ready for their library -> framework moment?
/goal also lands in Codex CLI 0.128.0.
Our take on the Ralph loop: keep a goal alive across turns. Don't stop until it's achieved.
Built by my co-worker and OpenAI mentor Eric Traut, aka the Pyright guy. One of the GOATs I get to work with daily.
Embeddings power every modern LLM. But what do they actually learn?
This Berkeley (BAIR) paper is one of the clearest reads on how AI systems learn and why embeddings really work.
https://t.co/qj10TMZjnp
Vector RAG finds similar text | | Vectorless RAG finds the RIGHT place.
Two completely different philosophies:
→ Traditional RAG: chunk, embed, search, hope
→ Vectorless RAG: index structure, route query, navigate, retrieve precisely
For long structured documents — legal, financial, technical — vectorless can be far superior.
No vector DB needed. No irrelevant matches. Just precise section retrieval.
The tradeoff? Your document structure needs to be solid.
Which approach are you using in your RAG pipelines? Drop it below
#RAG #AI #pythpn
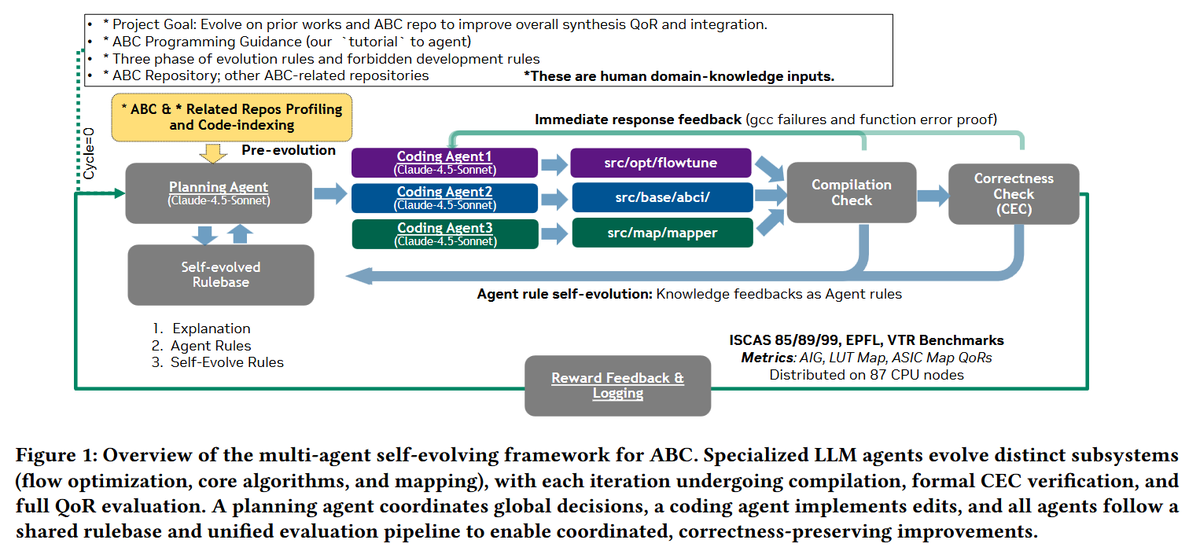
In this paper, Nvidia researchers have demonstrated an agentic LLM-based coding framework capable of autonomously evolving a multi-million-line EDA tool, demonstrating self-improving code generation at the full scale of the ABC logic synthesis system.
https://t.co/SZN6t5bV7N
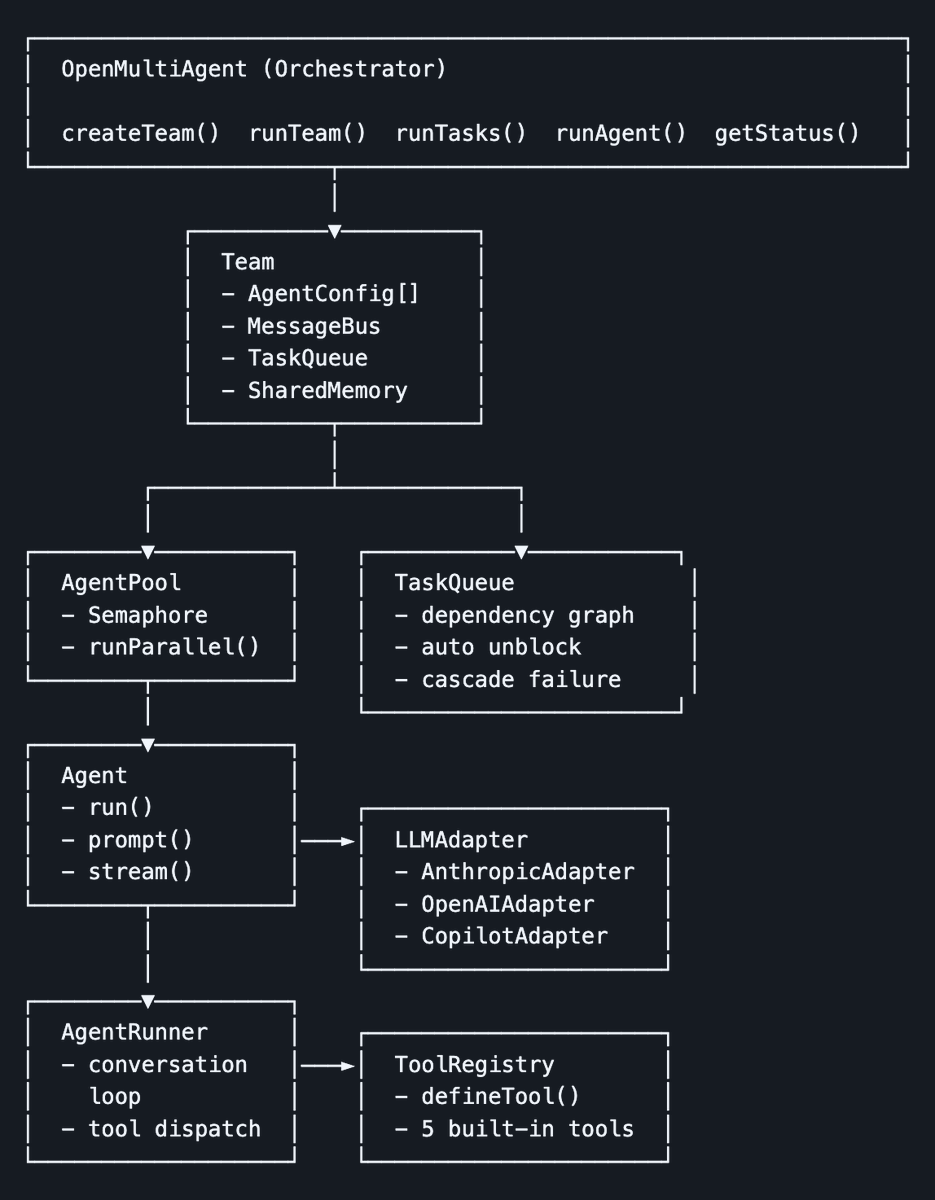
After the Claude Code source code leak, a former PM extracted its multi-agent orchestration system into an open source model agnostic framework.
He studied the architecture, focused on the multi-agent orchestration layer (the coordinator that breaks goals into tasks, team system, message bus, task scheduler with dependency resolution), and reimplemented these patterns from scratch as a standalone open source framework without infringing on Anthropic's code.
The result is what @JackChen_x calls an "open-multi-agent." Unlike claude-agent-sdk, which spawns a CLI process per agent, this runs entirely in-process and can be deployed anywhere (serverless, Docker, CI/CD)
Check it out: https://t.co/w3XjnZEk92
You really don’t need to worry about prompts. Just start from talking, from an idea, dive deep, until you feel it is almost there, let your agent create golden prompt for implementation. Then start new session, copy that prompt.
Qwen3.5 0.8B running real-time video captioning on a Mac Studio M2 Ultra.
<1s per frame.
269 frames from a 3m49s video.
Streaming descriptions as it plays.
Pause anywhere, it actually understands the scene.
~1GB model.
Local AI is getting unreasonably capable.
Video credit: @stevibe