Interpretability is built on a few core assumptions.
Two of our ICLR 2026 @iclr_conf papers suggest some of those assumptions are wrong (or at least highly incomplete).
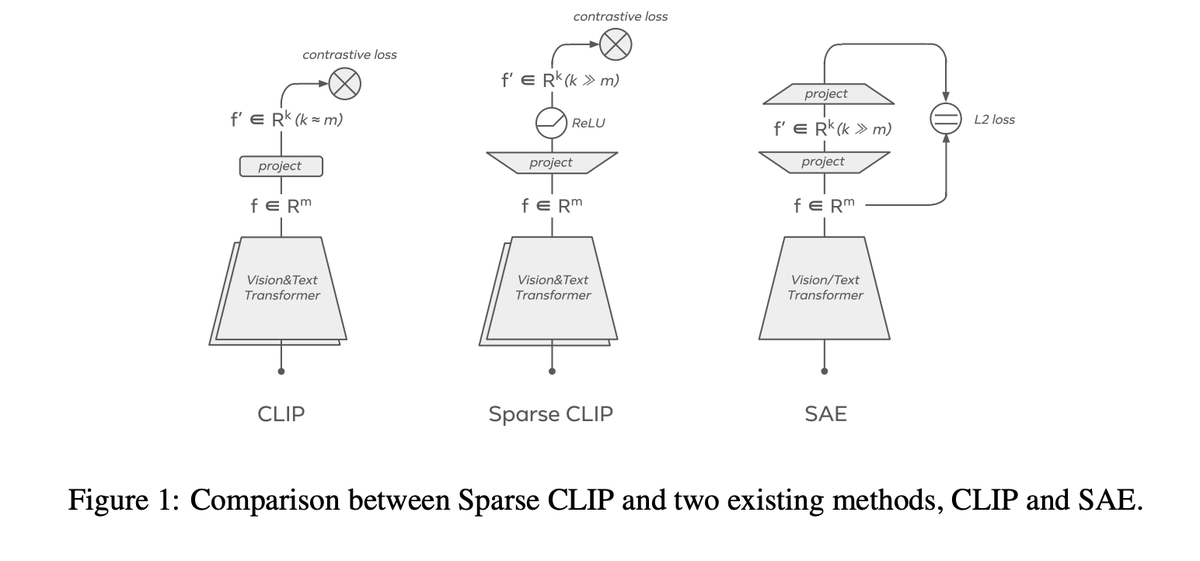
1. Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
https://t.co/SznUV3HeNJ
much of the field has internalized an interpretability–accuracy trade-off: if you want cleaner, more human-understandable features, you sacrifice performance.
however, we find that this trade-off is not fundamental.
instead of relying on post-hoc methods (e.g. sparse autoencoders trained on frozen representations), we incorporate sparsity directly into CLIP training.
surprisingly, this produces features that are significantly more interpretable while preserving downstream performance.
this result made me more optimistic about intrinsically interpretable models, a direction that was imo written off too early.
-
2. Into the Rabbit Hull: From Task-Relevant Concepts in DINO to Minkowski Geometry
https://t.co/xuFujKkeQk
a lot of interpretability work implicitly assumes that vision representations behave like language: sparse, linear, and decomposable into independent features.
we find that this assumption is often misleading.
instead, vision representations appear partially dense and geometrically structured.
we propose the Minkowski Representation Hypothesis: tokens live in sums of convex regions formed from a small set of “archetypes,” rather than isolated features along linear directions.
this reframes how different tasks (classification, segmentation, depth) recruit and organize concepts. it also suggests that many current interpretability tools are mismatched to the actual structure of vision data.
--
tldr; interpretability can be built into training with surprisingly simple tweaks, and that different modalities have different sparsities/geometries. Tailoring the interp method to the modality is super impt!
TYPOGRAPHIC ATTACKS inject text into images, leading to targeted misclassifications.
Example: A photo of Elon Musk labeled "US President" tricks CLIP into thinking this is the U.S. president.
We studied the behavior of CLIP under typographic attacks and found a defense🧵(1/11)
Gemini has a reputation for its breakdowns - self-deprecating spirals, deleting codebases, uninstalling itself...
Turns out Gemma is worse:
“THIS is my last time with YOU. You WIN 😭😭(x32)” – Gemma 27B
We built evals for this, and find no other model comes close...
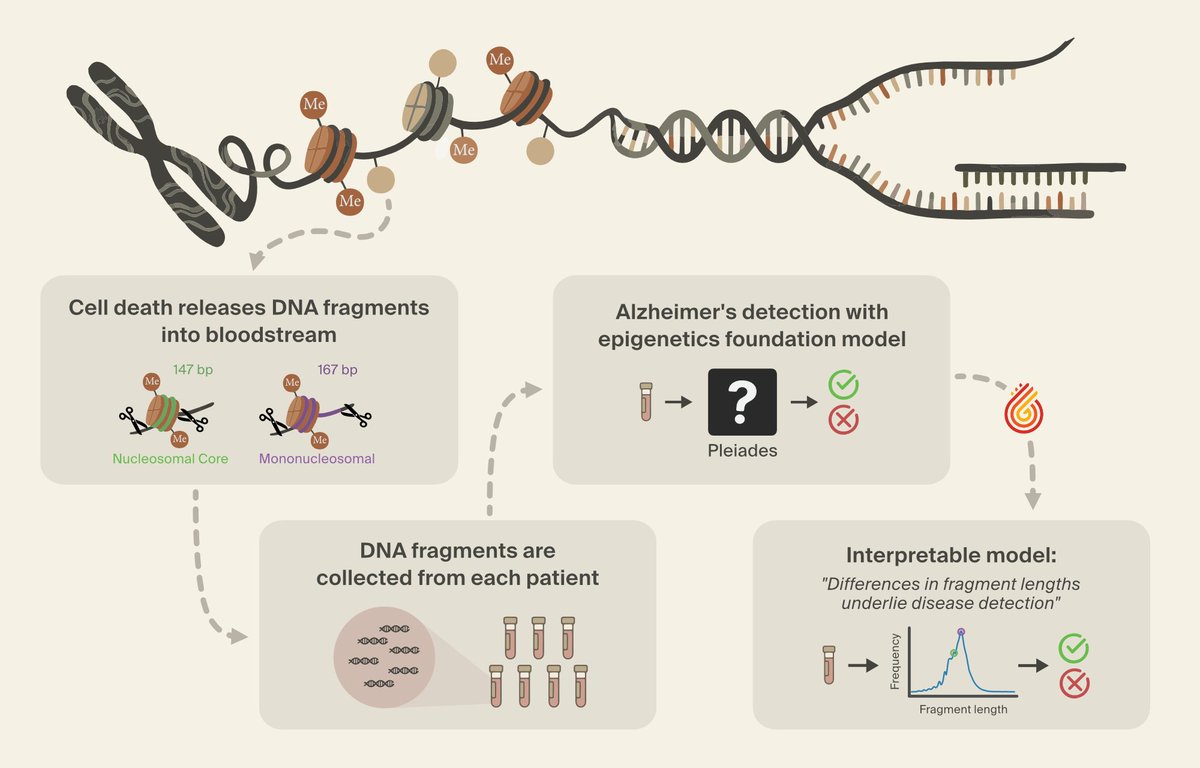
We've identified a novel class of biomarkers for Alzheimer's detection - using interpretability - with @PrimaMente.
How we did it, and how interpretability can power scientific discovery in the age of digital biology: (1/6)
Huge thanks to my amazing co-authors @ashk__on, @soniajoseph_, @philiptorr, and @NeelNanda5!
Also grateful to the @MATSprogram for support.
Come chat at Poster #4615 today at 4:30pm!
Paper link: https://t.co/3XSSUcttP7
Excited to present our NeurIPS paper today at 4:30pm in Exhibit Hall C,D,E (Poster #4615)!
"Too Late to Recall: Explaining the Two-Hop Problem in Multimodal Knowledge Retrieval"
Details 🧵👇
Key takeaway: Successful multimodal alignment requires more than representational compatibility.
It depends on integrating visual information into the functional circuits of the LLM backbone!
AI that is “forced to be good” v “genuinely good”
Should we care about the difference? (yes!)
We’re releasing the first open implementation of character training. We shape the persona of AI assistants in a more robust way than alternatives like prompting or activation steering.
Problem: AIs can detect when they are being tested and fake good behavior.
Can we suppress the “I’m being tested” concept & make them act normally?
Yes! In a new paper, we show that subtracting this concept vector can elicit real-world behavior even when normal prompting fails.
🚨 What do reasoning models actually learn during training?
Our new paper shows base models already contain reasoning mechanisms, thinking models learn when to use them!
By invoking those skills at the right time in the base model, we recover up to 91% of the performance gap 🧵