Reading "Distilling Knowledge in a Neural Network" left me fascinated and wondering:
"If I want a small, capable model, should I distill from a more powerful model, or train from scratch?"
Our distillation scaling law shows, well, it's complicated... 🧵
https://t.co/b1uuyJwzRF
Uncertainty methods and correctness metrics often share "mutual bias" (systematic errors from a common confounder like response length), skewing LLM evaluations.
New paper from my colleagues shows that "LM-as-a-judge" evaluation is more robust and human-aligned. Important work - check it out!
https://t.co/3ed0lFUQlK
Uncertainty quantification (UQ) is key for safe, reliable LLMs... but are we evaluating it correctly?
🚨 Our ACL2025 paper finds a hidden flaw: if both UQ methods and correctness metrics are biased by the same factor (e.g., response length), evaluations get systematically skewed
Data mixtures are crucial for achieving strong pre-trained models. Loved collaborating on this project led by @PierreAblin and @MustafaShukor1 tackling data mixing ratios through the lens of scaling laws. Check out @MustafaShukor1's 🧵.
We propose new scaling laws that predict the optimal data mixture, for pretraining LLMs, native multimodal models and large vision encoders !
Only running small-scale experiments is needed, and we can then extrapolate to large-scale ones. These laws allow 1/n 🧵
Excited to be heading to Vancouver for #ICML2025 next week!
I'll be giving a deep dive on Distillation Scaling Laws at the expo — exploring when and how small models can match the performance of large ones.
📍 Sunday, July 13, 5pm, West Ballroom A
🔗 https://t.co/yNd5eZByHR
@AmitisShidani1@samira_abnar@harshays_@alaa_nouby@AggieInCA@LouisBAlgue@PierreAblin Here's an Apple@ICML guide with all our talks, posters, and booth events:
🔗 https://t.co/fEkTYVZIo1
Come say hi if you're around, always happy to chat. Looking forward to a week of great research, and catching up with familiar faces (and meeting new ones too).
Excited to be heading to Vancouver for #ICML2025 next week!
I'll be giving a deep dive on Distillation Scaling Laws at the expo — exploring when and how small models can match the performance of large ones.
📍 Sunday, July 13, 5pm, West Ballroom A
🔗 https://t.co/yNd5eZByHR
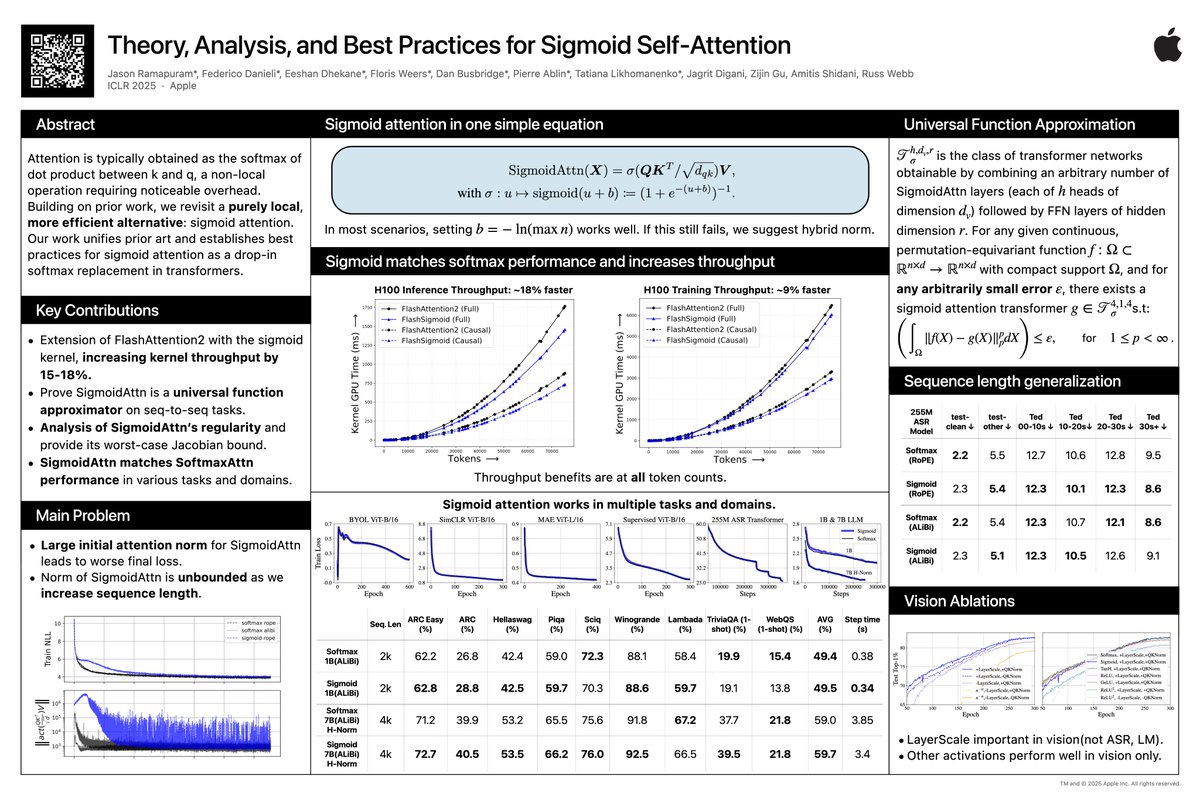
Stop by poster #596 at 10A-1230P tomorrow (Fri 25 April) at #ICLR2025 to hear more about Sigmoid Attention!
We just pushed 8 trajectory checkpoints each for two 7B LLMs for Sigmoid Attention and a 1:1 Softmax Attention (trained with a deterministic dataloader for 1T tokens):
- Sigmoid: gs://axlearn-public/experiments/gala-7B-sigmoid-hybridnorm-alibi-sprp-2024-12-03-1002/checkpoints/
- Softmax: gs://axlearn-public/experiments/gala-7B-hybridnorm-alibi-sprp-2024-12-02-1445/checkpoints/
Inference code at https://t.co/b0cp49qvAv
I’ve been curious about how early vs late-fusion multimodal approaches compare in controlled conditions. Great to see this studied in depth. Turns out, optimal late fusion has higher params-to-data, and performance between early and late fusion is similar. Brilliant work from @MustafaShukor1 and team!
Check it out: https://t.co/ySGPN5Ss19
We release a large scale study to answer the following:
- Is late fusion inherently better than early fusion for multimodal models?
- How do native multimodal models scale compared to LLMs.
- How sparsity (MoEs) can play a detrimental role in handling heterogeneous modalities? 🧵