Maya and Miles are joined by Simone and Charlie, and have far greater utility than they used to, while still being extremely conversational and low-latency. More info in the blog: https://t.co/8yGu9c1jSO
We're a small team @sesame, but looking for great people to join. Check out this podcast with @_apkumar to get a feel for how we work. More info at https://t.co/BD2PsOWlhk
the core research team behind the sesame voice model is <9 ppl
as @_apkumar walked through in our latest 1.5 hr podcast, talent density beats team size most days
We’re exploring a future where the computer isn’t just a tool—it’s a partner with a truly natural voice and personality. No big claims, just early work we’re excited to share. @sesame
@realmrfakename@sesame Yeah, we’re open-sourcing one of the base models (not fine-tuned with the voices you hear in the demo) in the next two weeks. Will be here: https://t.co/BPN0hMXxui
Excited to share a peek of what I’ve been working on
We @sesame believe voice is key to unlocking a future where computers are lifelike
Here’s an early preview you can try! 👇
We’ll be open sourcing a model, and yes…
we’re building hardware! 🧵
At Sesame, we believe in a future where computers are lifelike. Today we are unveiling an early glimpse of our expressive voice technology, highlighting our focus on lifelike interactions and our vision for all-day wearable voice companions. https://t.co/Edp8V8urgC
Introducing Parler-TTS: an inference and training library for high-quality, controllable text-to-speech (TTS) models 🗣️
To fuel the development of open-source TTS research, we are open-sourcing all datasets, training code and our first iteration checkpoint: Parler-TTS Mini v0.1
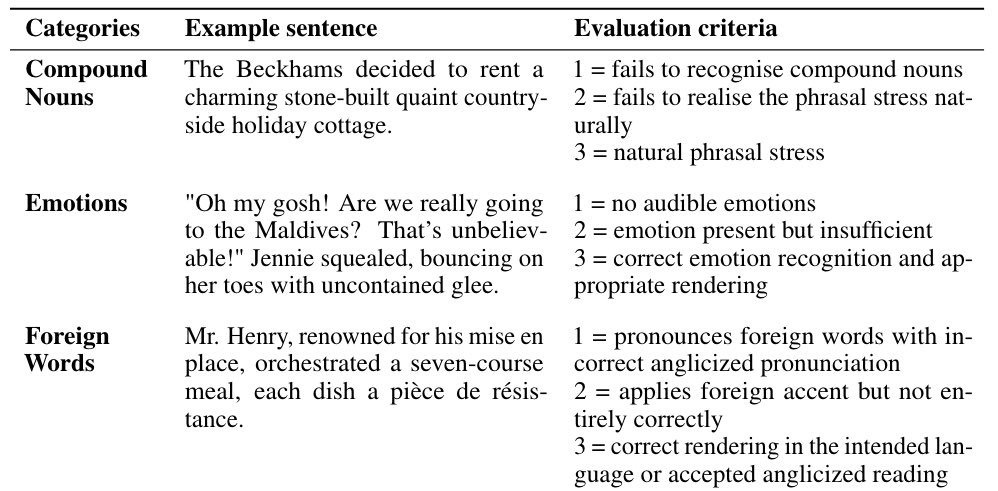
Moving beyond naturalness and WER, they propose a set of sentences that test the model’s ability to deal with compound nouns, emotions, foreign words, paralinguistics (e.g. whispering if the text requires it) etc. etc.
The full test set is included in the appendix. 👏
2/7
There are a bunch of other interesting elements to this work, and it’s worth a read. Plenty of examples on the demo site too. Nice work Mateusz Łajszczak, @guillecambara, Yang Li, and all the other contributors.
https://t.co/VV2SwDmidD
The speech “de-tokenizer” (or decoder) is a convolutional model that’s streamable and 3x faster than their diffusion-based baseline (and also sounds better).
It’s built around BigVGAN.
6/7