Your segmentation model can’t keep up with your camera‘s frame rate? 🏃♀️
Check out our work on FAST video segmentation that maintains the accuracy of modern vision foundation models! 🚴♀️
📍 Poster #611 @ #CVPR2026 (Denver)
🗓️ Sunday 12:45 - 2:45 PM, June 7th
If you’re in Denver for #CVPR2026 and want to make world models more efficient, chat with us at poster 611 on Saturday (17:45–19:45) or at the VGI workshop poster session on Wednesday (12:20–13:30).
Not in Denver? Reply below and let’s discuss!
Stellar oral presentations by @ClaudiaCuttano and @gabTrivv at #CVPR2026!
Definitely check out their great works INSID3 and MARCO on in-context segmentation and semantic correspondence.
DINOv3, but then for 3D CT images!
tldr: SPECTRE is a plain ViT pretrained on tons of CT data, obtaining SOTA results when finetuned on various tasks.
Great work by my friends from the ARIA lab at TU/e.
#CVPR2026@Chris_Viviers Cris Claessens et al.
Your segmentation model can’t keep up with your camera‘s frame rate? 🏃♀️
Check out our work on FAST video segmentation that maintains the accuracy of modern vision foundation models! 🚴♀️
📍 Poster #611 @ #CVPR2026 (Denver)
🗓️ Sunday 12:45 - 2:45 PM, June 7th
If you’re in Denver for #CVPR2026 and want to make world models more efficient, chat with us at poster 611 on Saturday (17:45–19:45) or at the VGI workshop poster session on Wednesday (12:20–13:30).
Not in Denver? Reply below and let’s discuss!
Challenge-maxxing at #CVPR2026 with my buddy @adr_kruse , using our recent 3D backbone Volt ⚡️
We won 3 challenges at this CVPR and I’ll present Volt at the ScanNet++ (@chandan__yes) and OpenSUN3D(@FrancisEngelman) workshops on the first day afternoon (June 3rd). Come by!
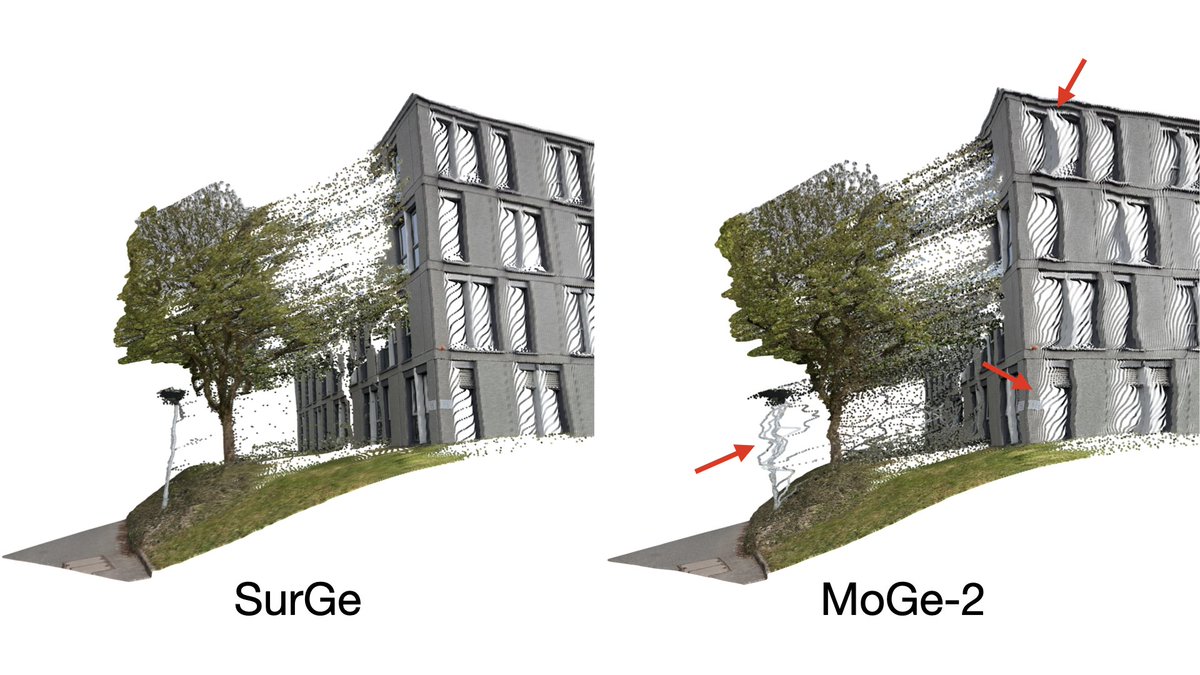
New work: SurGe
We improve local accuracy in feedforward 3D reconstruction. Current point map models struggle with bending and oscillating artifacts for thin structures (chair legs, street lamps, etc). Easy to spot visually, but not well captured by pointwise metrics like AbsRel.
It's been one week since I launched PapersWithCode, and I've already added a bunch of new features!
It includes support for papers beyond @arxiv, new methods, social media thumbnails, and support for multiple metrics per leaderboard.
Find them all here:
https://t.co/i4NfgFWuh6
Could this be the ViT moment for 3D scene understanding? 🚀
We revisit the good old Transformer architecture and apply it to 3D scene understanding with minimal modifications. #Volt ⚡️
Project page: https://t.co/1HYyTrtdak
Arxiv link: https://t.co/imcuvM6j0X
(1/5)
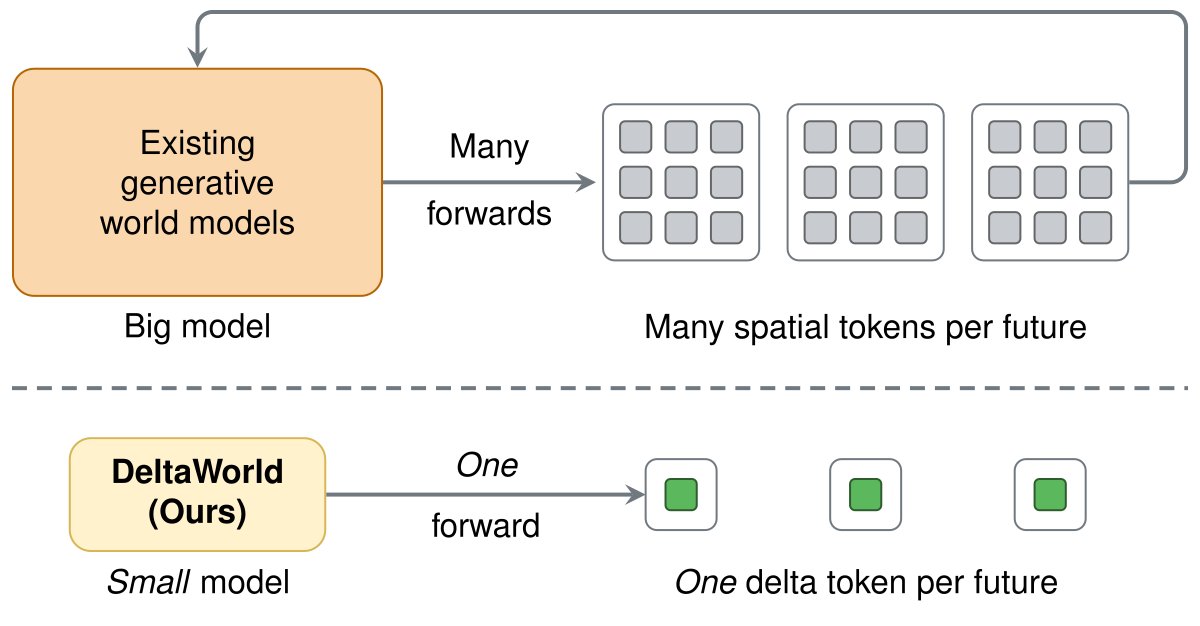
World models are heavy. They don't need to be.
Each frame is encoded as 1024 spatial tokens. What if it were just 1?
In our #CVPR2026 Highlight from Amazon FAR, we compress frames into "delta" tokens for efficient generative world modeling.
Paper, code & models below ↓
(1/7)
🚀 New CVPR Workshop paper: Plain Mask Transformer (PMT)
Finetuning VFMs for segmentation breaks their key advantage: using a shared, frozen encoder for multiple tasks.
PMT: a fast Mask Transformer for frozen VFM features.
📄 https://t.co/FlCJiaJ6Yk
💻 https://t.co/xzwf17Xirf
Video segmentation methods have become increasingly complex. In our #CVPR2026 paper we show once again that a surprisingly simple encoder-only architecture is actually sufficient, boosting speed up to 10x!🚀
📄Paper: https://t.co/RGp2EnUN7U
💻Code: https://t.co/kaC8yxQBYe
(1/5)
Opus 4.6 made a @Gradio demo for it too!
It uses a "chunked window" approach, allowing it to run up to 160 frames per second (FPS)
I'm really impressed by coding agents - porting a model + demo in less than 2 days
🔥Encoder-only Mask Transformer (EoMT) now also supports DINOv3!
⚡️ Upgrading DINOv2 to DINOv3 ➡️ more accurate image segmentation, same lightning-fast inference
🔗 Code and models: https://t.co/ON0EF5sXFv
Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense prediction tasks.
Learn more about DINOv3 here: https://t.co/lQpKhJLTZQ