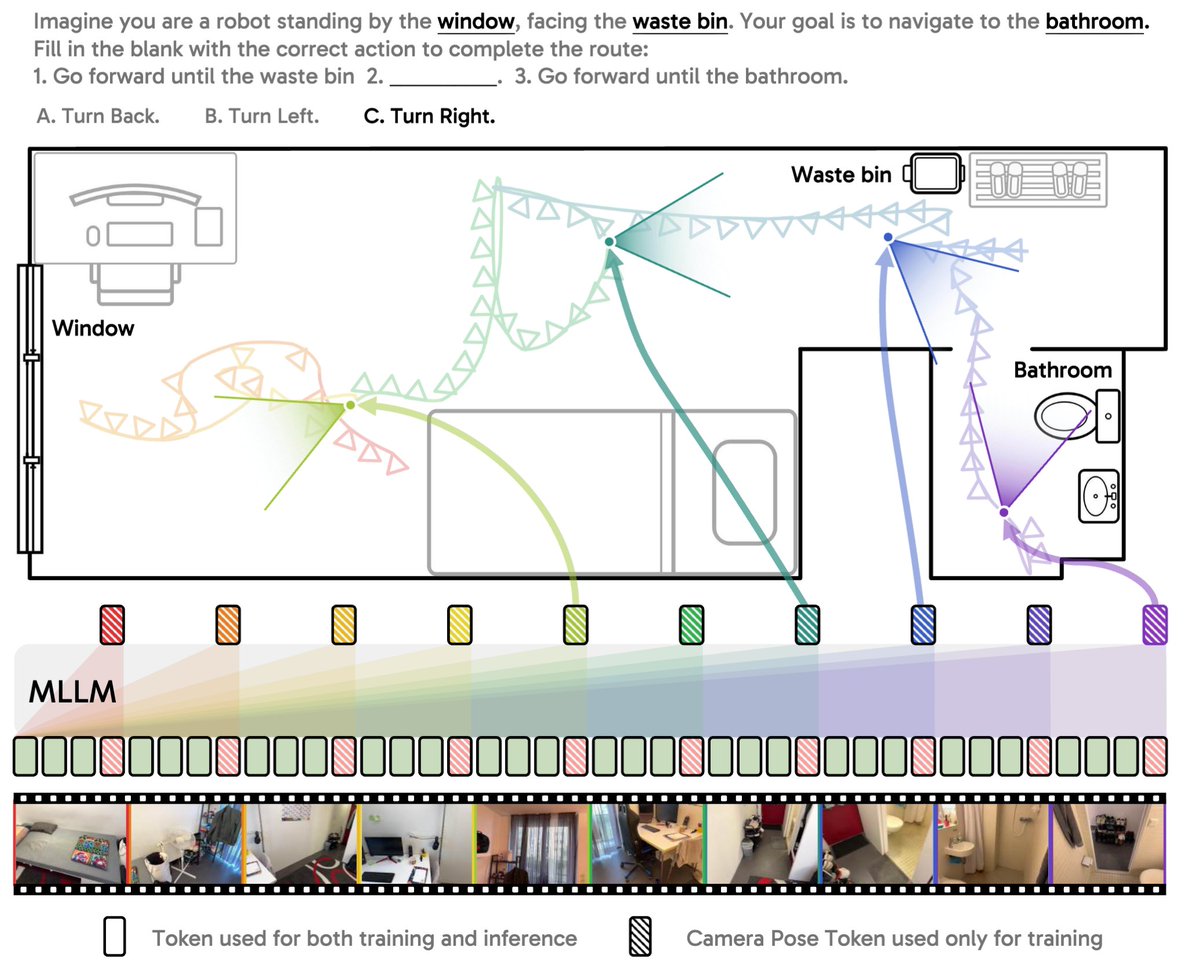
Camera pose matters for video understanding!
Today's MLLMs excel at recognizing activities, but still struggle with the underlying space and ego/object dynamics in video. We trace this gap to a missing piece: camera pose.
Introducing Cambrian-P: a multimodal LLM natively grounded in camera pose. (1/n)
Do 3D reconstruction transformers really need a billion parameters, or are most of those layers just doing the same thing over and over?
Introducing Déjà View: a single transformer block, looped K times, that matches or beats models 8–10× its size with lower compute. 🧵
Yesterday, I was giving an intro talk to our dept's new PhD students. Technical things aside, my number 1 suggestion has remained the same over the years: Treat your PhD like a job.
- Avoid 1.5h lunch and three tea breaks.
- Avoid gossiping and loitering at work.
- Lab at 9 am and leave at 6 pm. Being productive till 11 pm in the lab is a lie people till themselves when their day starts at 1 PM.
Everything worth doing can be done with high intensity focus during work hours. And having fun in life is the secret to being productive in a marathon.
Yay, finally! Introducing Vision Banana🍌 from @GoogleDeepMind, our unified model that outperforms SoTA specialist models on various vision tasks!
By treating 2D/3D vision tasks as image generation, we unlock a new foundation for CV.
Project page: https://t.co/GQgRi6mWwC
(1/5)
Introducing CityRAG!
We wanted video generative models to be grounded in the real world — if I’m in London, I want to look around and actually see Big Ben.
CityRAG generates videos of cities featuring real buildings and roads, with arbitrary weather, people, and cars. 1/N
page: https://t.co/jxMSX5Ik7F
paper: https://t.co/So2V9hyB4D
Most multi-view reconstruction models need full supervision. We show they can self-improve without any ground truth labels.
Introducing SelfEvo: Self-Improving 4D Perception via Self-Distillation. Up to +36.5% in video depth, +20.1% in camera estimation, zero annotation.