#ChatGPT as an Analyst
Motivation
I want to ask ChatGPT to estimate the AI market value in 2023 providing the history data.
Here is my question, and the generation output of ChatGPT is astonishing.
Exciting release from @Alibaba_Qwen 🔥
Qwen 2.5-Coder is now live on @huggingface
👉https://t.co/QuVqn4Sjn4
✨ Apache 2.0 license
✨ 0.5B, 1.5B, 3B, 7B, 14B, 32B base & instruct
✨ 128K long context support
✨ SOTA performance on coding benchmarks
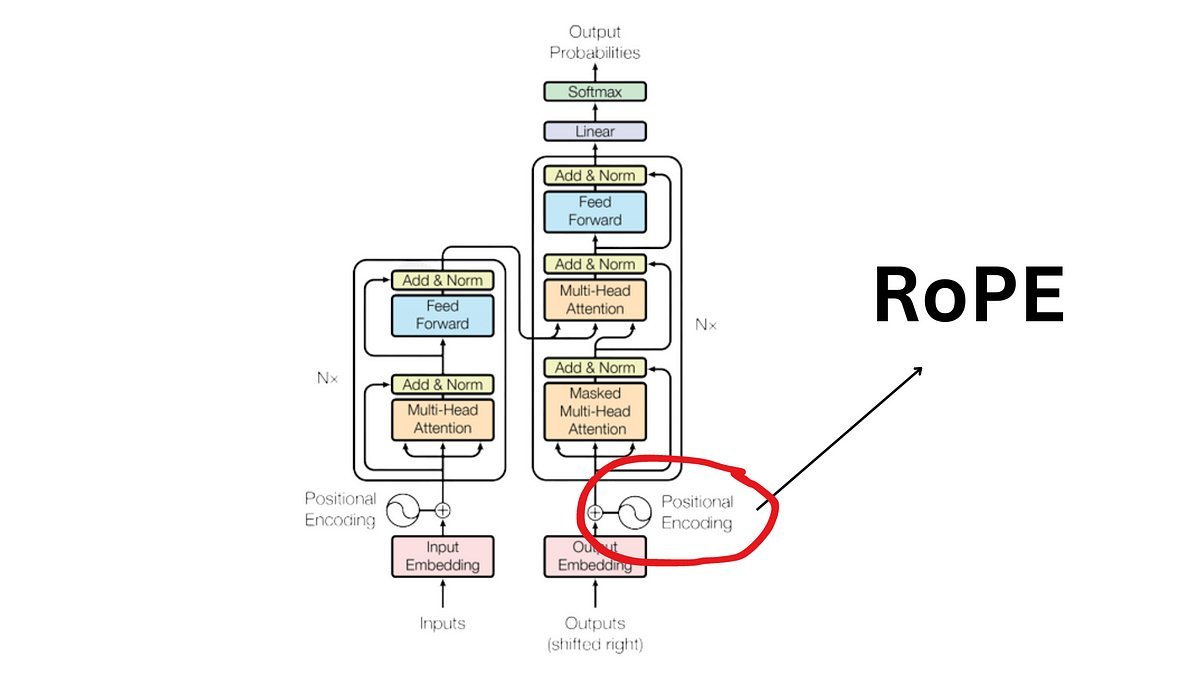
"Attention Is All You Need" paper was truly a landmark paper.
However, the original "vanilla" transformers are seldom used now.
The huge key upgrade is the use of RoPE, or Rotary Positional Embeddings.
**Vanilla Decoder**
- Input tokens -> Embeddings -> Embeddings + Positional Encoding -> Decoder Blocks
**RoPE Decoder**
- Input tokens -> Embeddings -> Decoder Blocks
**Rotary Positional Embeddings**
RoPE are used in attention blocks, which need to know token positions.
Attention blocks combine information from a lot of tokens and need to know their relative positions
For example, consider this sentence "It's a big thrill to climb a big mountain."
"mountain" should focus more on the nearby "big."
RoPE applies a rotational matrix to queries and keys, not values. If "mountain" is the 9th word, it rotates fully, while earlier words rotate less, aligning "mountain" more with the second "big."
This approach is efficient as it applies positional embeddings only where needed and keeps token magnitudes unchanged.
RoPE scales well to longer contexts, allowing models to be pre-trained on 4k contexts and fine-tuned for up to 4M by adjusting rotation speed.