ABCFold: Easier Running and Comparison of AlphaFold 3, Boltz-1, and Chai-1
- Structural biology has seen a revolution with deep learning-based protein structure predictors like AlphaFold 3, Boltz-1, and Chai-1. However, running and comparing these models efficiently remains a challenge.
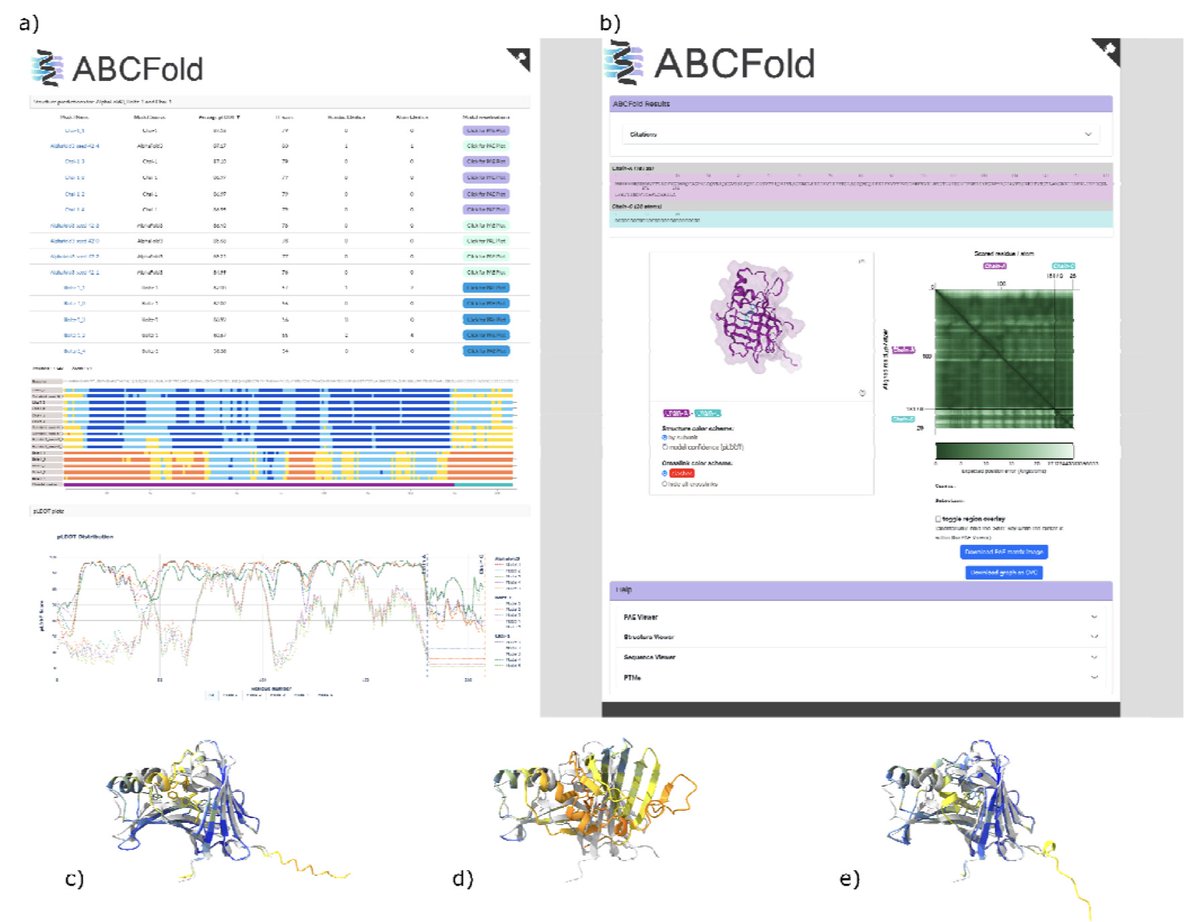
- ABCFold is a new tool that simplifies the process of running and benchmarking AlphaFold 3, Boltz-1, and Chai-1, allowing users to generate structure predictions with a standardized input format.
- The tool converts AlphaFold 3 JSON inputs into compatible formats for Boltz-1 and Chai-1, enabling seamless execution of all three models from a single input.
- ABCFold provides automated multiple sequence alignment (MSA) handling, supporting both JackHMMER-based searches and the MMseqs2 API. Users can also supply custom MSAs and template structures.
- The software includes a unified output visualization framework, allowing side-by-side comparison of model predictions, pLDDT scores, and predicted aligned error (PAE) values. Structural clashes are also highlighted for better assessment.
- One of the key benefits of ABCFold is its ability to automate installation and version management of Boltz-1 and Chai-1, reducing setup complexity for researchers.
- By providing standardized evaluation metrics and interactive visualization tools, ABCFold enhances reproducibility and helps researchers assess the relative strengths of different structure prediction methods.
- This tool is an important step toward better benchmarking of next-generation protein structure predictors, enabling broader adoption and more effective model selection for specific biological applications.
💻Code: https://t.co/xSVlnU7xWr
📜Paper: https://t.co/CzeruToqne
#StructuralBiology #AlphaFold #MachineLearning #ProteinFolding #DeepLearning #Bioinformatics #ComputationalBiology
DGL (Deep Graph Library) is presented as a high-performance graph manipulation library that leverages GPU acceleration for enhanced computational speed. Its core strength lies in its versatile graph object, capable of residing on either CPU or GPU, and its ability to efficiently manage both structural graph data and associated node/edge features.
Furthermore, DGL offers a rich set of functions, including optimized and customizable message passing primitives, specifically designed to facilitate the development and execution of Graph Neural Networks (GNNs).
https://t.co/3YRyXiMDMF
Demonstrating through Molecular Dynamics (MD) simulations that the bacterial TAM complex facilitates the spontaneous flow of phospholipids from the inner membrane (IM) to the outer membrane (OM) is a significant contribution.
1/ In my final project as part of the @CorryLab, we show the bacterial TAM complex facilitates the spontaneous flow of phospholipids from the IM to the OM in MD simulations..
https://t.co/74LBAaoP7I
This approach within the Deep Graph Library (DGL) provides excellent user control and transparency! Consolidating the complete GraphSAGE model definition, data processing, and training loop into a single Python script offers significant benefits.
The ability to replicate the dgl train results by simply executing this script ensures reproducibility and greatly simplifies understanding the entire workflow within DGL. Furthermore, it empowers users to easily customize any part of the process – such as integrating their own GNN modules or altering the loss function – fostering experimentation and a deeper understanding of graph neural networks within the DGL framework.
This level of accessibility and flexibility is highly valuable for both education and advanced research using DGL.
https://t.co/KMSMTq8rPS
Biotite 1.2 connects to the bioinformatics ecosystem with seamless interfaces to RDKit, PyMOL and OpenMM. Below you see a simple MD simulation of lysozyme combining the interfaces to OpenMM and PyMOL. The full changelog is available at https://t.co/lmERsUQTqA #Bioinformatics
DGL-Go, a pipeline within the Deep Graph Library (DGL), utilizes its task for node multiclass classification, generating configuration files that encompass dataset specifications, model and training hyperparameters, and explanatory comments for each option; this allows users to customize and optimize the training process by adjusting parameters related to the chosen dataset, model architecture (such as the number of layers and hidden size), and training dynamics (like learning rate and loss function) within the DGL framework.
https://t.co/kO6yOSzc1Z
Graph Neural Networks (GNNs) have demonstrated remarkable performance across a wide array of industrial applications. However, a significant bottleneck in their training process lies in their substantial memory requirements.
The core operations of GNNs are inherently memory-bound, demanding extensive Random Access Memory (RAM) due to the large tensor sizes involved. To address this challenge and enhance the memory efficiency of GNN training, particularly within frameworks like Deep Graph Library (DGL), a strategy utilizing Bfloat16 data types on Intel® Xeon® Scalable processors was implemented.
🔗: https://t.co/VEsddNMrII
DGL-Go, a command-line tool within the Deep Graph Library (DGL) ecosystem, simplifies the entry point for users working with Graph Neural Networks (GNNs).
It's designed to be accessible to both data scientists, who can leverage it for quick application of GNNs to their problems, and researchers, who can use its customizable features for in-depth experimentation. By providing a streamlined interface for training, using, and studying GNNs, DGL-Go lowers the barrier to entry into graph-based machine learning.
🔗 : https://t.co/kO6yOSyEcr
LLMs struggle with abstract concepts despite strong performance on verbal analogies.
This is because their internal representations are not truly conceptual. This paper introduces Concept Vectors (CVs) extracted via Representational Similarity Analysis (RSA).
CVs aim to capture invariant conceptual information within LLMs.
📌 Concept Vectors, extracted by Representational Similarity Analysis, offer a more concept-invariant representation than Function Vectors.
📌 Concept Vectors act as feature detectors. Models can internally represent concepts correctly, even with incorrect outputs.
📌 Representational Similarity Analysis effectively localizes attention heads relevant to specific task attributes beyond just concepts.
----------
Methods Explored in this Paper 🔧:
→ Function Vectors (FVs) were initially explored using activation patching. These proved sensitive to input format changes.
→ Representational Similarity Analysis (RSA) was then used to identify attention heads encoding invariant concept vectors (CVs).
→ CVs are formed by summing outputs from top-ranking attention heads based on RSA.
→ CVs showed invariance to low-level input changes for verbal concepts.
→ Interventions with CVs causally influenced model behavior, demonstrating their functional role.
→ However, for abstract concepts like "previous" and "next", invariant CVs were not found, hindering generalization in tasks like letter-string analogies.
I taught an LLM to optimize proteins. It proposed a better carbon capture enzyme.
Introducing Pro-1, an 8b param reasoning model trained using GRPO towards a physics based reward function for protein stability.
It takes in a protein sequence + text description + previous experimental results, reasons over the information given in natural language, and proposes modifications to improve the stability of the given sequence.
🧵(1/n)
Deep Graph Library (DGL) emerges as a critical tool in the landscape of modern machine learning, specifically tailored to handle the complexities of graph-structured data. In an era where data relationships are increasingly vital, DGL provides a robust and high-performance framework for building and deploying Graph Neural Networks (GNNs). Its core strength lies in its ability to leverage the computational power of GPUs, significantly accelerating the processing of large and intricate graphs.
DGL's architecture is designed around a flexible graph object that can dynamically shift between CPU and GPU memory, optimizing performance based on the computational load and available resources. This adaptability is paramount for handling diverse graph sizes and complexities, ensuring efficient execution across various applications. Furthermore, DGL integrates structural data, which defines the connections between nodes, with feature data, which encapsulates the attributes of those nodes and edges, within a unified and manageable structure. This integration streamlines data manipulation and provides developers with granular control over their graph data.
Repo : https://t.co/pl2i5hWPBF
Incredible 👏
A 7B parameter model (Qwen2.5 7B Deepseek-R1 Distilled) ourperforms OpenAI’s o1.
Achieves a 90% accuracy on the MIT Integration Bee qualifying exam.
LADDER (Learning through Autonomous Difficulty-Driven Example Recursion), a novel framework that enables large language models (LLMs) to enhance their problem‐solving capabilities without requiring manually curated datasets or human feedback.
Instead, LADDER leverages the model’s own abilities to recursively generate and solve progressively simpler variants of complex problems, thereby creating a natural gradient of difficulty for self-improvement.
LADDER prompts an LLM to break down a challenging problem into multiple easier variants recursively. Each variant, forming a branch in a variant tree, serves as a stepping stone toward solving the original complex problem.
The framework uses reinforcement learning (specifically, Group Relative Policy Optimization or GRPO) to update the model based on a reward signal derived from a numerical verification mechanism. This mechanism numerically verifies solutions (e.g., via numerical integration), ensuring that only correct solutions are rewarded.
TTRL extends LADDER to inference time. When faced with a difficult problem at test time, the model generates a focused set of simpler problem variants and applies reinforcement learning on the fly. This targeted “micro-learning” process allows the model to adapt dynamically to each test instance, boosting performance further.
Deep Graph Library (DGL) presents itself as a user-friendly, high-performance, and remarkably scalable Python package meticulously designed to facilitate deep learning on graph-structured data. Its strength lies not only in its robust feature set but also in its framework-agnostic nature, offering unparalleled flexibility to developers.
This means that while DGL excels at handling the graph-specific components of a deep learning model, the remaining aspects of a comprehensive application can be seamlessly implemented using any of the prevalent deep learning frameworks, including but not limited to PyTorch, Apache MXNet, and TensorFlow.
This interoperability empowers developers to construct complex, end-to-end applications by leveraging the strengths of multiple frameworks, ensuring that DGL can be seamlessly integrated into diverse and sophisticated machine learning pipelines.
🤹 Excited to share Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems
joint work with @wellingmax and @jwvdm
Core components of Erwin:
- hierarchical organization of data via ball trees
- localized attention for linear complexity
- hardware-efficient multi-scale architecture
preprint: https://t.co/eZo8X1cBLb
code: https://t.co/hjOVFiZeD7
1/N
"FeatureDock for protein-ligand docking guided by physicochemical feature-based local environment learning using transformer"
• Molecular docking is essential for drug discovery, but current deep learning methods like DiffDock lack well-defined scoring functions to distinguish between strong and weak inhibitors during virtual screening.
• FeatureDock is a transformer-based deep learning framework that leverages chemical features from protein local environments to accurately predict protein-ligand binding poses while achieving strong scoring power for virtual screening, demonstrating robustness on Cyclin-Dependent Kinase 2 (CDK2) and Angiotensin-converting enzyme (ACE) datasets.
• The researchers discretized binding pockets into grid points with 3D-invariant FEATURE representations (6 concentric shells with 80 physicochemical properties), trained a Transformer encoder to predict binding probabilities, and developed a scoring function combined with a position optimization algorithm to screen and predict binding poses.
• FeatureDock outperformed DiffDock, Smina, and AutoDock Vina in distinguishing strong from weak inhibitors with higher KL divergence (0.67 vs. 0.39, 0.04, 0.04) and better AUC (0.74 vs. 0.76, 0.43, 0.43) for CDK2, while achieving accurate binding poses with an average RMSD of 2.4Å from native structures.
Link:https://t.co/ZzH8pW72II
No More Tears with Matryoshka🪆 & Let's Embrace Sparsity
With sparse autoencoders + sparse contrastive learning, we can compress SOTA text/image/multimodal embedding models from 2k/4k dimensions to 16 active dimensions with: ~100x faster at large-scale retrieval, minimal degradation (eg <0.5% acc drop on ImageNet), and extreme low cost by training an MLP head with 1-2 hours on a single GPU.
Reasoning models lack atomic thought ⚛️
Unlike humans using independent units, they store full histories
Atom of Thoughts (AOT): lifts gpt-4o-mini to 80.6% F1 on HotpotQA, surpassing o3-mini and DeepSeek-R1 !
Test-Time Alignment for Complex Reward Functions? We introduce a test-time, reward-guided iterative refinement algorithm for diffusion models.
Unlike existing single-shot guided methods (e.g., classifier guidance, SMC methods), our method employs an iterative refinement. It alternates between reward-guided denoising and noising, enabling the optimization of complex rewards that single-shot methods struggle with.
Applications: By leveraging our method, which combines unconditional discrete diffusion models for protein sequences with multiple reward functions (i.e., seq → functionality) at test time, we demonstrate the ability to generate desirable protein sequences.
Notably, our approach can be seen as a variant of evolutionary algorithms, where candidate generation is guided by reward-driven denoising within diffusion models. + We provide the theoretical guarantees + application to cell-type-specific regulatory element design.